C/C++
1. 引论: 程序设计范式
本章着重介绍两种贴近底层但功能强大的计算机程序设计语言: 鼎鼎大名的 C 语言 和在此基础上发展而来, 具备面向对象程序设计特性的 C++.
我们将从 程序设计范式 的角度出发, 分别剖析C (面向过程) 和 C++ (面向对象) 这两种 描述数据和计算过程具有较大差别 的程序设计语言.
定义 1.1 (程序设计范式, Programming Paradigm)
程序设计范式描述的是 程序设计的本质: 描述所使用的数据和对数据执行的计算 的不同方法.
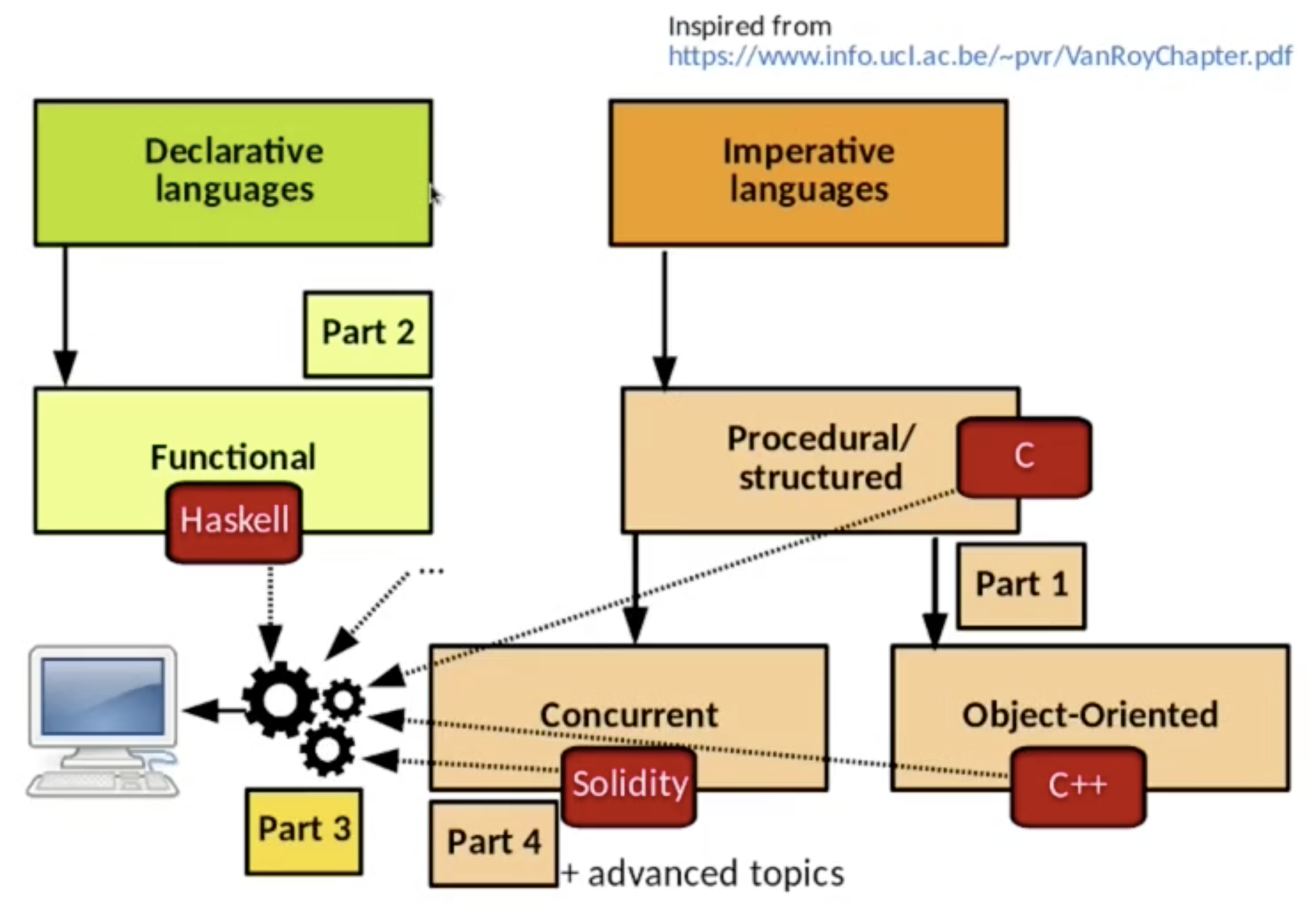
程序设计范式一般分为 函数式 (如
Haskell), 面向对象 (如C++,Java) 和 逻辑式 (如Prolog,tptp).需要注意的是, 程序设计语言可能同属多种不同的范式, 如
C++虽然常被视为面向对象语言, 但也支持一些函数式编程的特性.程序设计范式没有优劣之分, 它们对于不同的情形具有各自的优越性.

程序设计范式表现为程序设计风格. 如常见的程序设计语言均为过程式编程, 而 Haskell 和 Prolog 则为声明式编程:

程序设计范式还可表现为程序员描述程序计算过程的不同方式:

程序设计范式同时决定了程序员应该如何描述在计算过程中使用的数据:

纯过程式程序设计语言
主要的 过程式/命令式 (Imperative) 程序设计语言包括汇编语言, C 语言等, 通过明确地命令计算机如何处理某件事情来达到所希望的结果, 程序员在编写程序时需要使用循环, 条件判断等语句明确描述算法的每一步过程. 和纯粹的声明式语言相比, 过程式语言能够更清楚地描述复杂程序.

过程式面向对象程序设计语言
而 过程式/命令式面向对象 程序设计语言 将 特定的功能代码和数据封装到对象中, 利用继承和多态 (Inheritance & Polymorphism) 等面向对象建模思想实现了高效的代码复用并降低了程序复杂度, 适合使用在包含大量状态转换和操作的复杂程序中, 而且便于理解和维护.

过程式并行程序设计语言
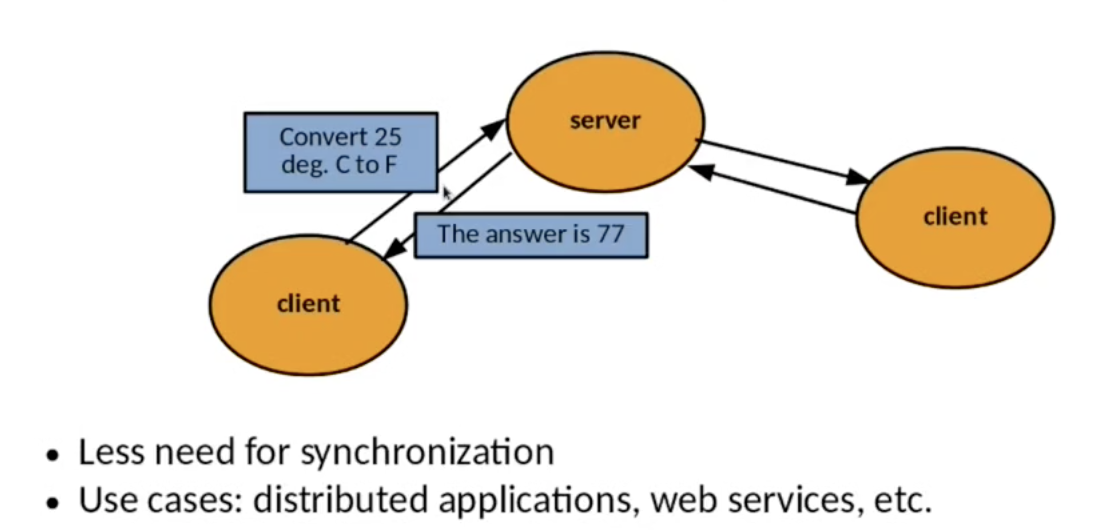
在 过程式并行程序设计语言 中, 程序员可以使用 线程/进程 的概念描述 交错执行 或 并行执行 的计算流, 适合应用于分布式计算, 高性能计算, 图形处理等领域.

声明式/描述式程序设计语言
主要的 声明式语言 包括 SQL, HTML, Markdown, 正则表达式等, 解决问题的方式并非详细解释解决问题的步骤, 让机器严格按照步骤执行计算, 而是使用特定语法清晰明确地描述问题本身或所期望得到的结果, 让机器自行基于预设规则尝试解决问题.
声明式语言具备高度的抽象性, 往往同时具有极高的复杂度, 应用场景主要是文本渲染, 结构化数据存储等领域.

声明式/描述式函数式程序设计语言
声明式/描述式函数式程序设计语言 基于一阶函数 (可被作为参数输入其他的函数中, 也可以从其他的函数中作为返回值返回的函数) 或高阶函数, 循环是通过递归实现的. 使用这类语言编写的程序主要包括 纯函数: 输出完全由输入决定, 不产生任何副作用, 由此具有更高的安全性, 某种程度上也相对更容易理解.

声明式/描述式并行程序设计语言
最后总结如下:
相关题目解析





2. C语言简介
C 语言诞生于上世纪 $70$ 年代, 是一种久负盛名的重要的, 结构化命令式面向过程的程序设计语言.

C 由于其高效, 贴近硬件底层 (如可直接执行内存读写和内存空间分配) 的特点, 非常适合操作系统, 驱动程序, 嵌入式系统开发.
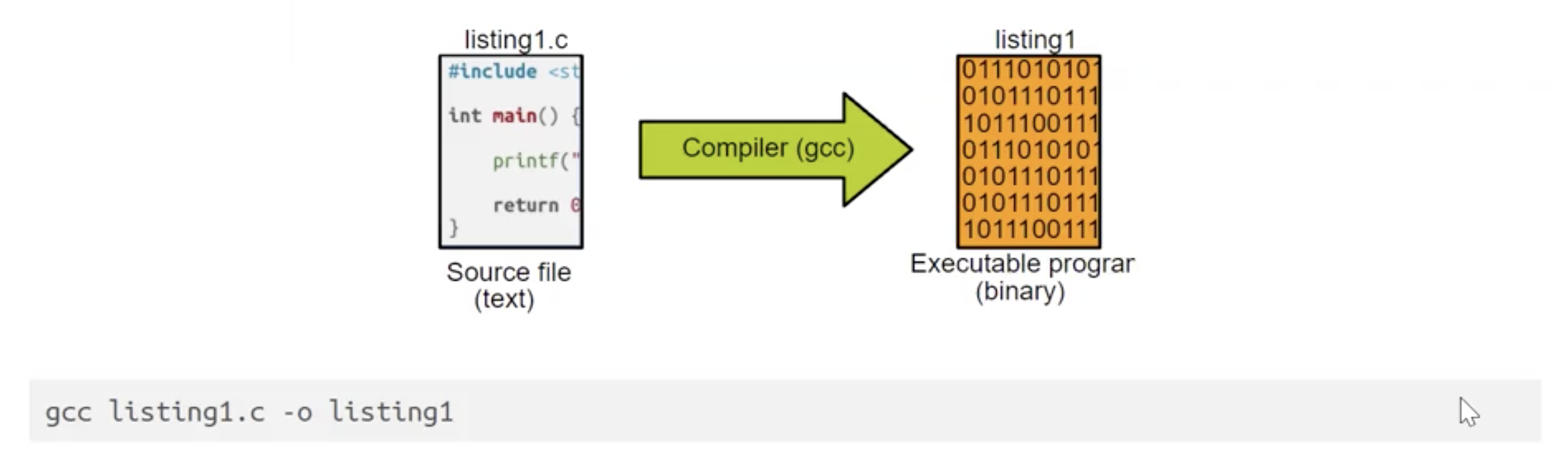
首先以最简单的 Hello World 程序为例描述 C 语言程序源代码中不同元素的作用:

而由于 C 是一种编译型语言, 我们需要在执行程序前先使用编译器从源码生成实际的可执行程序.
变量, 类型
C 是强类型语言, 任何变量在使用前需要声明其变量名, 初始值和变量类型.

C 语言中的 变量类型 描述了 分配给变量的内存空间大小, 同时编译器在执行程序编译时会检查程序所执行的变量运算和变量调用等是否在类型匹配的角度上是合法的.
C 语言中的三种基础数据类型包括: 整数 (int, short, long), 浮点数 (float, double) 和 字符 (Char).

而在 C 中对不同类型数据的控制台格式化输出方法如下:

注: 可以将 无符号 (unsigned), 长型 (long) 视为前缀 u 和 l, d 表示整数 (digit), 注意长浮点数 (double) 即为 lf.
同时需要注意, 由于类型定义的不同只是决定了编译器如何解释固定长度内存空间中的数据的方式, 因此如果意外地在处理数据和格式化输出时使用和变量类型不匹配的输出标记编译器也不会报错.
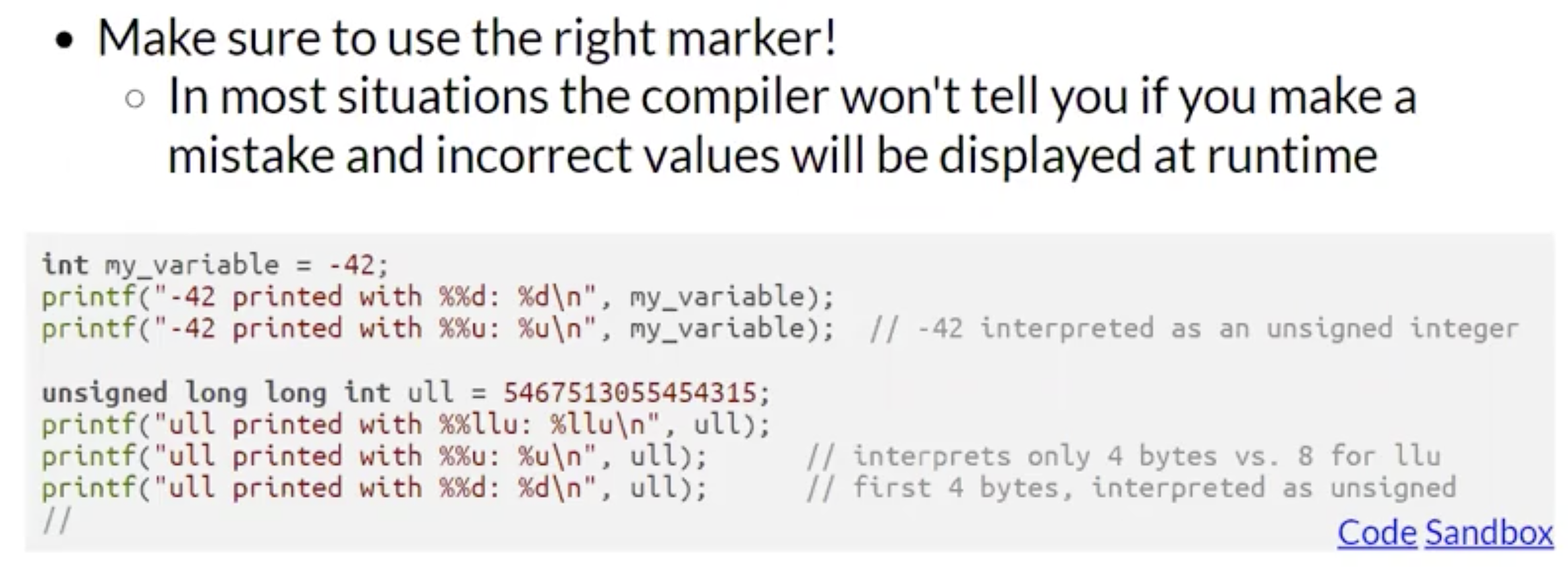
在上图的例子中, 当我们将含符号整数当成无符号整数格式化输出时, 将会得到非常意外的结果.
提示: 回顾无符号整数表示法, 含符号整数的补码表示法和小端序定义.
数组, 字符串和命令行变量
数组
在 C 语言中, 数组的编码方式为 行主导 (回顾 COMP26020 Ch3 编译器导论), 且存储方式为: 在一段连续的内存空间内依次存储每行的所有元素:
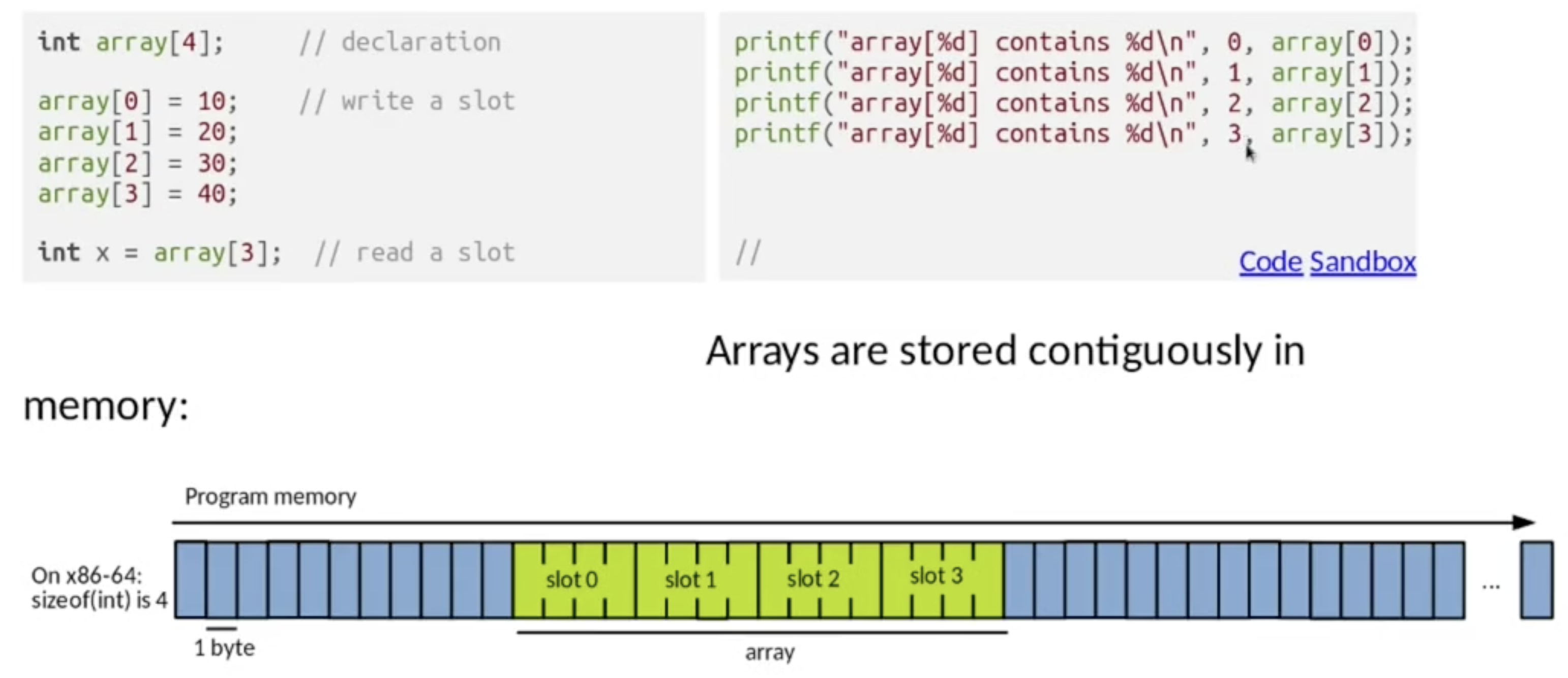
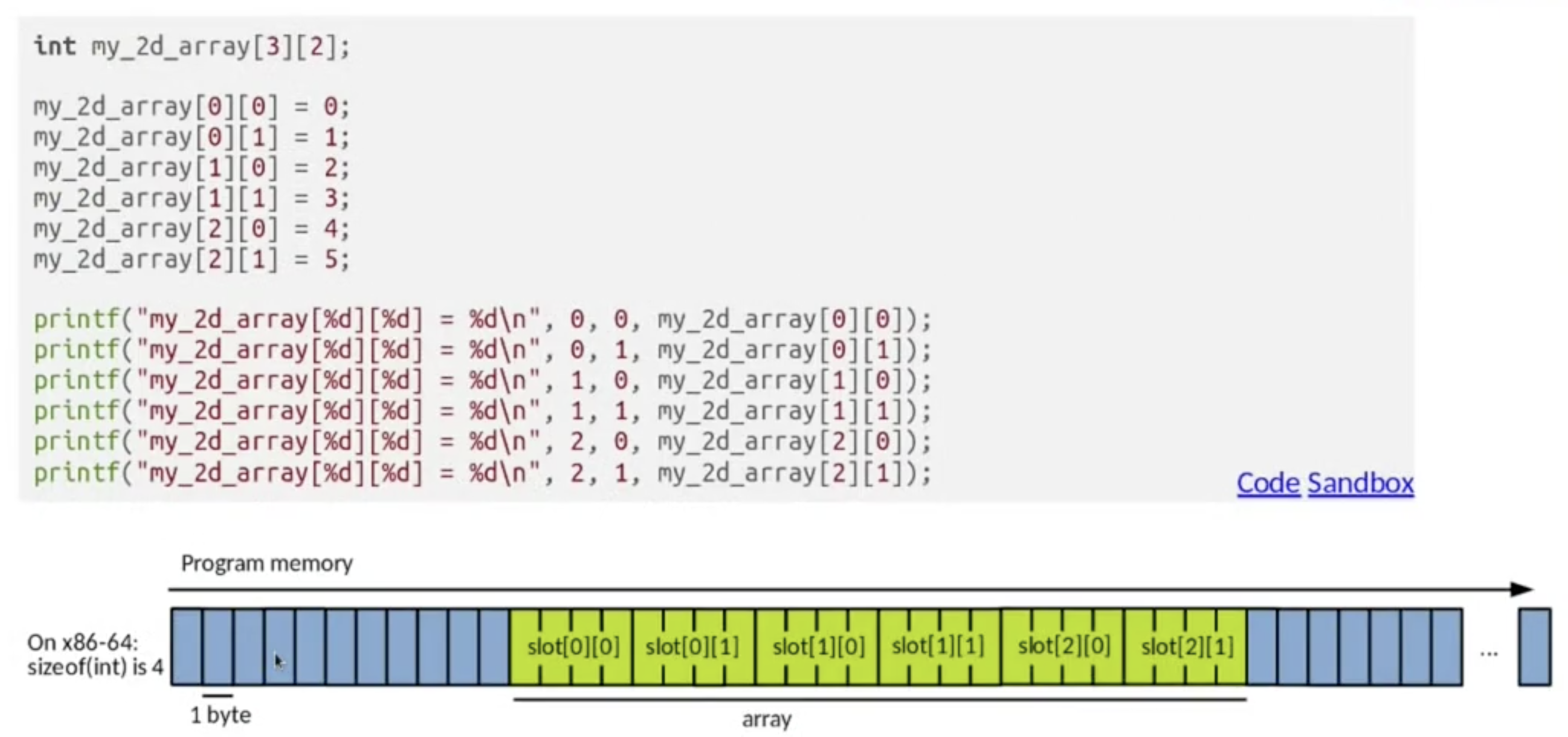
在 C 语言中, 对数组的声明一般伴随着初始化. 需要注意的是, 在静态初始化 (Static Initialisation) 数组时, 我们可以 忽略对数组 第一维度 尺寸信息的声明.

字符串
此外, 数组和 C 语言中的字符串也有密不可分的联系. 在 C 语言中, 字符串实际上就是一个字符数组, 而其特点是在该字符数组中, 除了按照顺序存储每个字符外, 还会在字符串尾额外加上一个 \0 表示 字符串的终止.
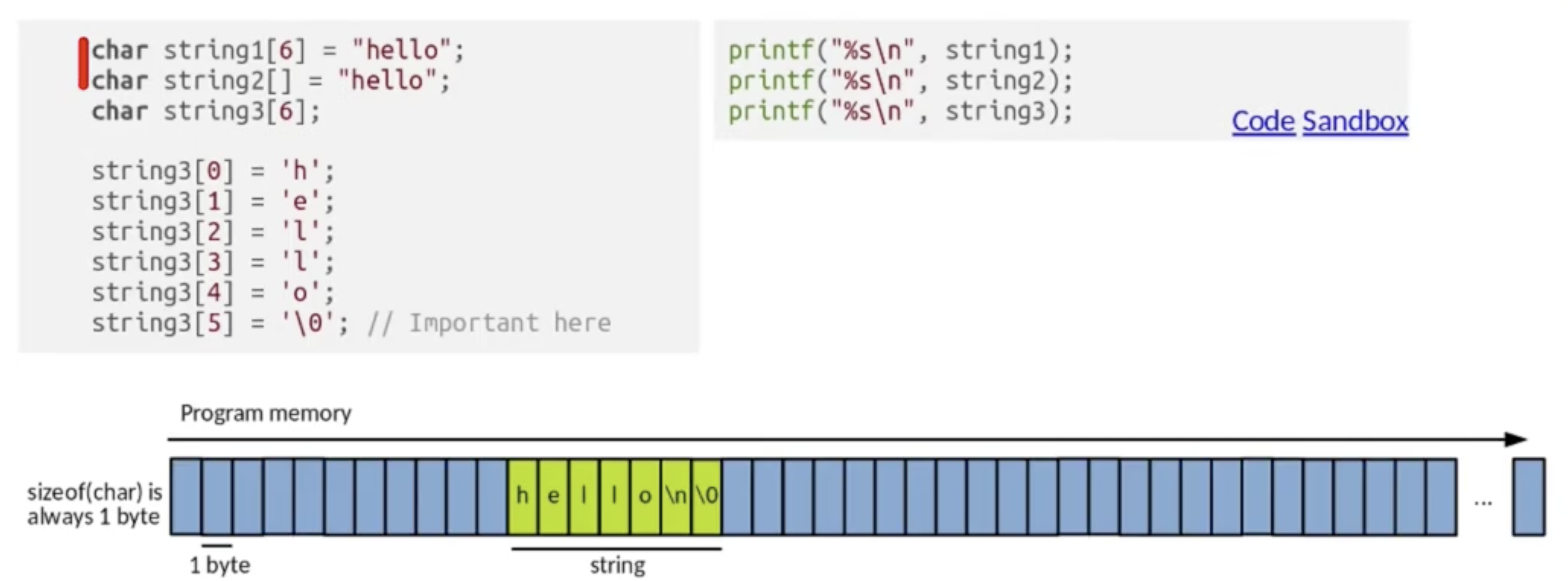
命令行变量
下面介绍 C 语言中命令行变量及其调用方法:
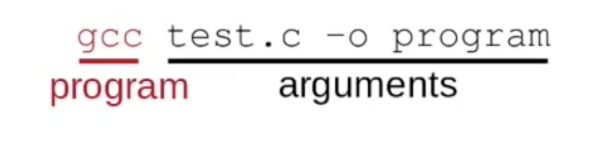
C 语言中任何程序的 main 主函数 都需包括两个参数: 存储命令行变量数量的 argc (argument count), 以及存储实际命令行变量的 数组 argv (argument vector).

需要注意:
-
可执行文件路径 本身在任何情况下都会被作为第一个命令行变量传入
main中. -
输入的命令行参数类型恒为字符串.
条件控制语句和循环语句
本小节讨论 C 语言中的条件控制与循环语句.
在 C 语言中, 每一条陈述语句 (基本语句) 都以分号 ; 结尾, 并且按照顺序依次执行:

条件控制语句
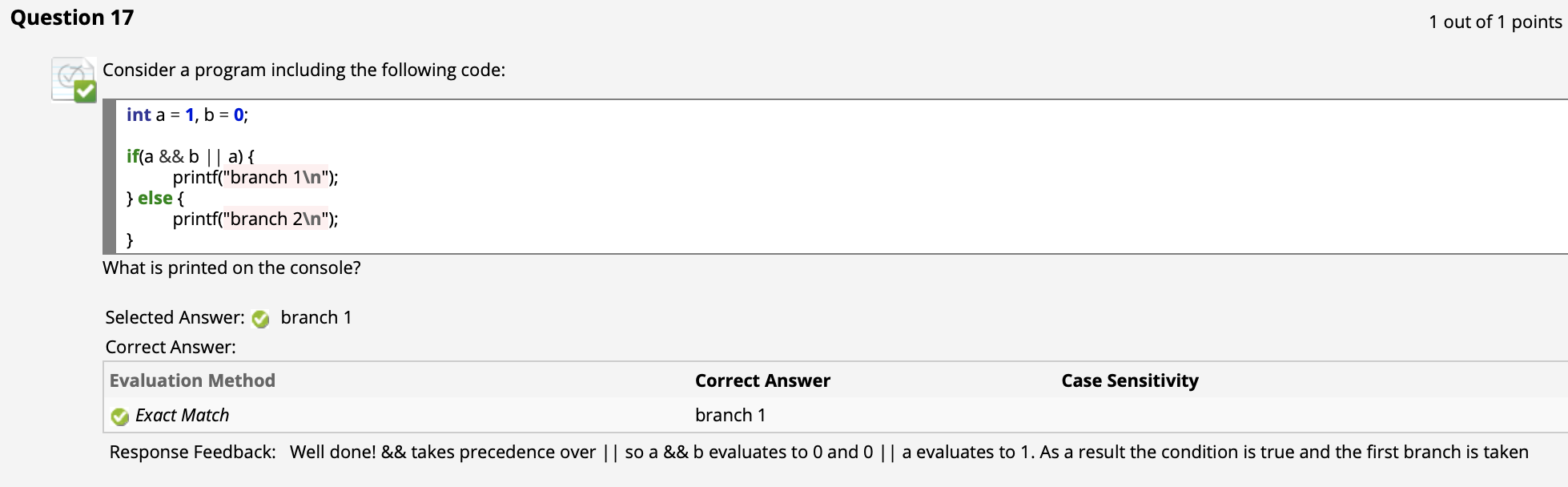
而 C 语言中对条件控制语句 if...else.. 的定义如下:

注意逻辑表达式的短路特性和优先级: “非 > 与 > 或”.
C 语言同时具有 Switch 语句:

注意在每一种子情况对应的语句后都需要加上 break 以防止自动执行后面的不同情况对应的语句; 以及在任何情况下最好都要确保声明了默认情形 default.
循环语句
C 语言提供了 while 和 do...while 循环:

其核心差别在于 while 总会优先检查循环条件, 可能执行 $0~\infty$ 次循环, 而 do...while 总是先执行循环体再检查条件, 循环体至少会执行一次.
C 语言还提供了 for... 循环, 我们可以精准控制循环变量和循环条件:

循环控制语句
C 语言还允许我们使用下列的循环控制语句:
break 允许我们 终止当前循环体的执行并跳出当前循环.
continue 允许我们 跳过当前循环体的执行并进入下一轮循环, 类比于 Python 中的 pass 关键字.

最后, 我们说明控制循环/条件判断语句作用范围的 中括号 {} 在避免程序出现歧义上的重要性:

若每个循环体/条件判断语句体只包含 一条语句, 则此时才可以安全地省略括号, 否则就可能导致类似于上图中第二个例子里 else 和 if 配对时出现的歧义问题.
函数
函数的声明
我们可以在 C 语言中定义函数. 对函数的定义必须包括一个 函子 (functor, 实际上就是函数名), $0$ 个或多个 声明类型 的参数, 以及 返回值的类型 (也就是常说的, 函数的类型).

如果函数不返回任何值, 则定义其类型为 void. 注意, 即使函数不返回任何值, 仍需要保留 return 语句.

函数参数和返回值的传值
而在调用函数时, 函数参数和函数的返回值会以拷贝而非引用的方式传入/传出函数, 这和包括 Python 在哪的程序设计语言一致. 这意味着, 我们将某个变量 $x$ 作为函数参数 $y$ 传入函数后, 该函数对这个参数 $y$ 进行的任何修改都不会影响 $x$, 因为在传入变量时 $y$ 是作为 $x$ 的拷贝 独立存在的.

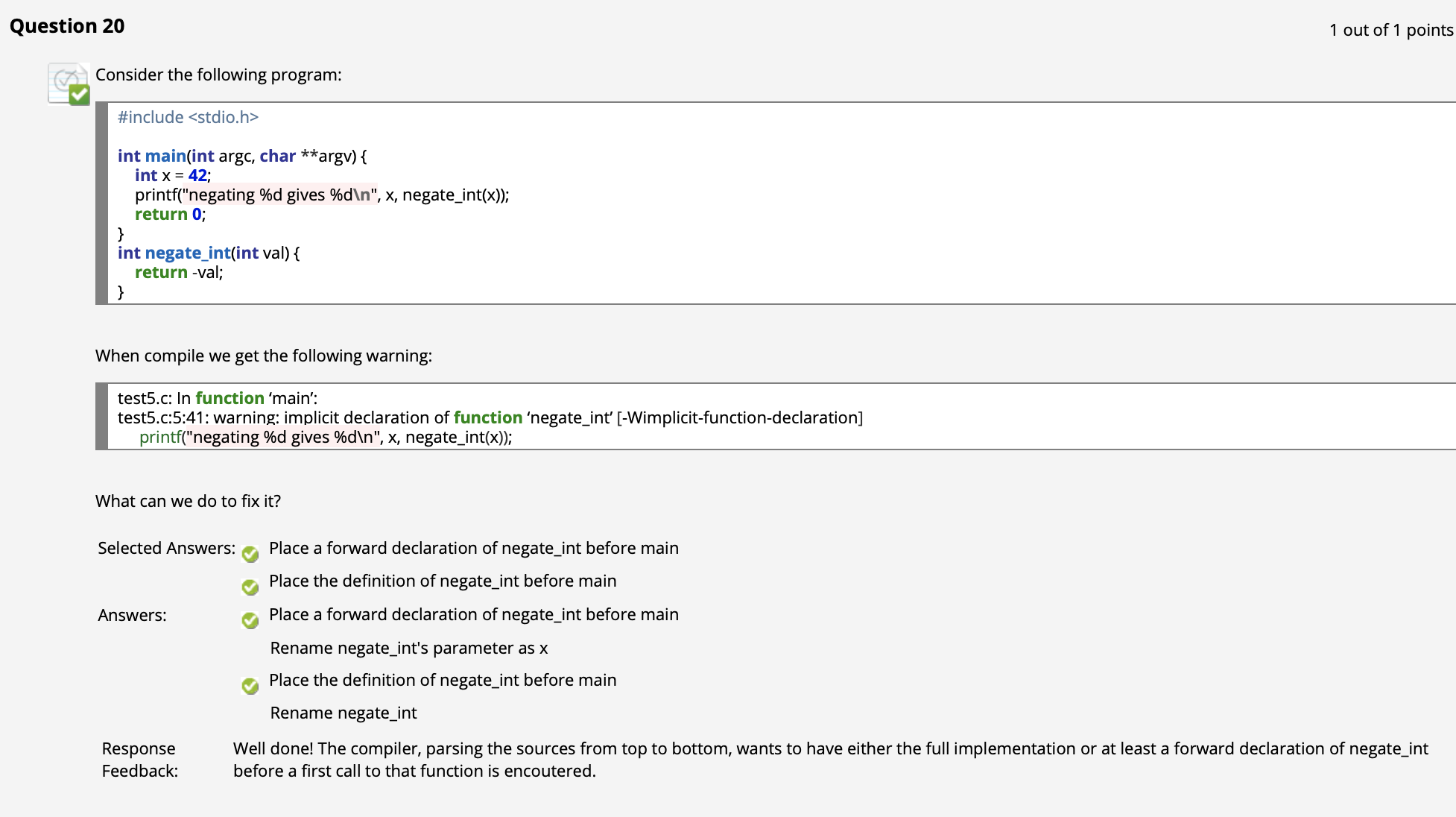
此外, 由于 C 语言编译器在编译源码时会进行全局扫描, 我们完全可以对函数 “先调用, 后定义”, 也就是所谓的 前置定义 (Forward Declaration).
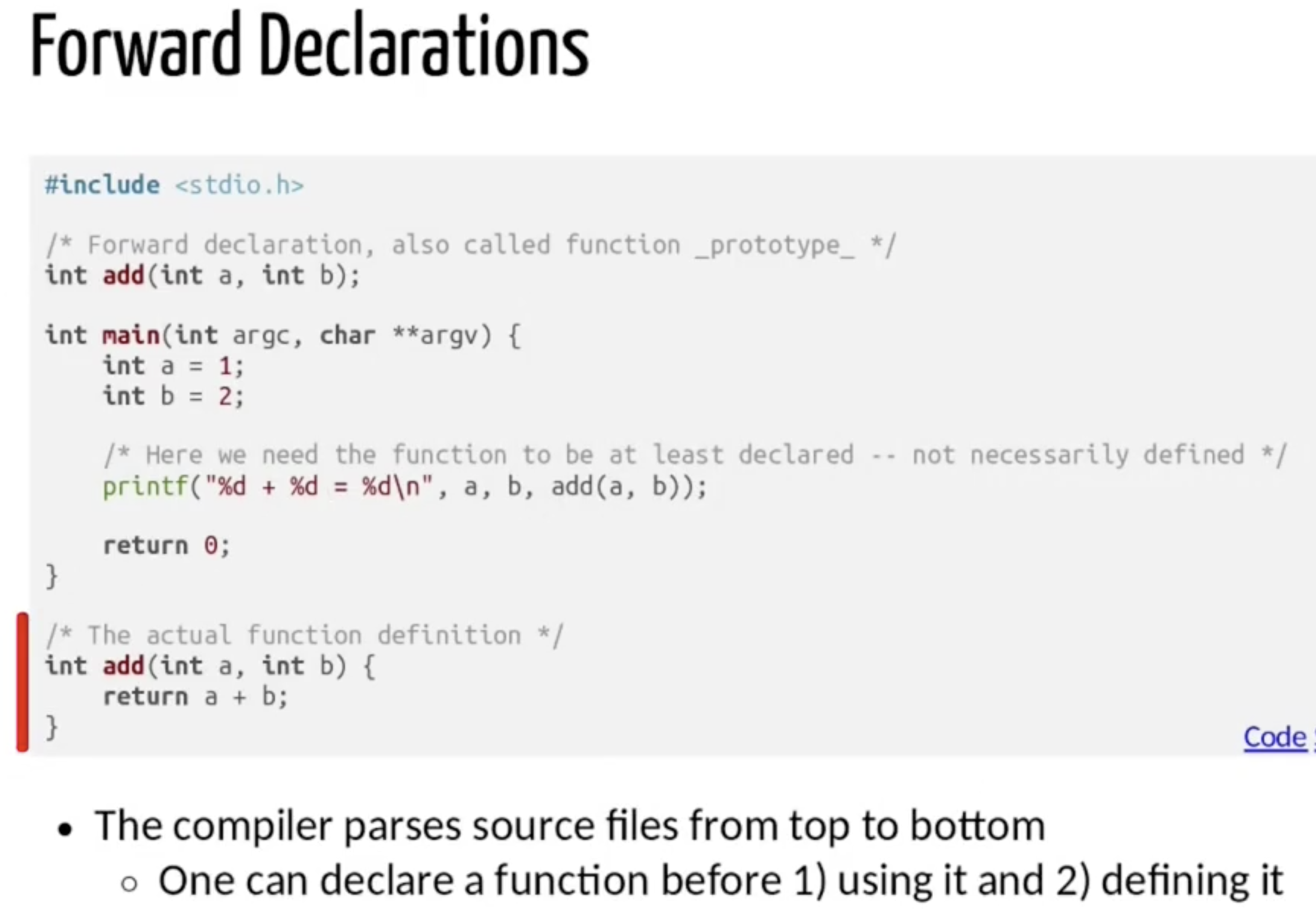
变量的作用域和生命周期
我们再明确 C 语言函数变量作用域和生命周期的问题:
-
全局变量定义在 函数体之外, 整个源代码 范围内均可见.

-
局部变量定义在函数体内 (也就是由一对中括号
{}包裹起来的程序段中), 而其作用域也 仅限于这个程序段里.
出于安全考虑, 应当 尽可能地避免声明和使用全局变量.
用户自定义类型和数据结构
本节讨论 C 语言中的用户自定义类型和数据结构.
自定义类型
我们可以使用 typedef 关键字为 特定的数据类型创建别名:

如在上面的例子中, 我们就使用 typedef 关键字为类型 long long unsigned int 创建了别名 my_int, 此后就可以用 my_int 指代它对应的类型.
自定义数据结构
C 语言中的自定义数据结构称为 结构体, 它可以使用 struct 关键字, 我们想要赋予结构体的名称和结构体中 包含的变量类型 (namefield) 来定义:

而在调用对应结构体时, 也需要指明被调用变量的类型为结构体.
在从外部访问结构体内存储数据时, 需要使用的语法为 <variable_name>.<field_name>, 如从描述某个 Arcaea 玩家 axton 的结构体 struct axton 中访问存储其潜力值的字段 float potential 时就需要使用 axton.potential.
在 不考虑编译器优化 的情况下, 结构体的大小就等于其 内部存储的所有数据字段对应类型的大小之和.

如上图所示的结构体 person 在内存中占用的空间大小就为 10 * 1 + 4 + 4 == 18 字节.
我们可以利用自定义类型简化对结构体的调用.
假定我们想声明存储个人信息的结构体 person, 则按照常规的定义方法我们每次在声明一个新的 person 类型的变量时都需要使用 struc person.
利用自定义类型语句 typedef struc s_person person, 再将对 person 的结构体定义名从 person 改为 s_person, 从此在程序中 person 就代表 struc s_person, 再也无需表明它是一个结构体类型 struc.

枚举类型
C 语言支持 枚举类型, 注意编译器实际上会自动为每个枚举定义一个对应的整数常量, 这使我们可以直接在 switch 语句中调用枚举类型.

同样地, 我们也可以相应地利用自定义类型简化对枚举类型的引用.

相关题目解析




($\uparrow$ 注意 C 结构体没有 C++ 那种乱七八糟的对齐优化)

($\uparrow$ 注意指针数据类型的位数就是计算机硬件位数: $32$ 位机指针大小 $4$ 字节 $48=32$ 位, $64$ 位机指针大小 $8$ 字节 $88=64$ 位)
( $\uparrow$ 注意 $0$ 被解释为 False, 非负整数被解释为 True)
($\uparrow$ 可以先调用后定义, 但是声明必须放在调用前)
3. C语言进阶
本节介绍 C 语言学习中的核心和重点概念: 指针及动态内存分配.
首先明确 C 程序和数据在内存中的存储方式. C 语言认为, 程序的所有代码和数据都存储在内存的某个区域中, 而程序的寻址空间 - 即该程序所可以访问的内存空间, 则为一块 连续的, 足够大的内存区域. C 进一步将这个连续的内存区域视为一个数组, 因此内存区域中每一个块对应的内存地址 (Address) 就是这个数组的索引 (Index).

需要注意: 任何程序的寻址空间实际上都是经过操作系统抽象化后的 虚拟的连续内存空间, 实际上这些数据可能存储在不同内存颗粒甚至不同内存条的不同位置, 而 Memory Mapping 由操作系统的内存管理功能完成.
并且, 在正常情况下, 任何程序都将被分配一块独属于它自己的寻址空间.
指针
基于上面的定义, 我们认为 C 语言中任何变量的地址均为 存储这个变量的数据的, 连续的内存空间的第一个比特位对应的地址.

而进一步地, 在明确了任何变量的地址的概念后, 就可以引入指针的概念.
C 语言中的指针本质上就是 存储内存地址的变量, 或者说 C 语言恒将指针数据类型的变量所存储的内容当作内存地址来处理.
在 C 语言中, 指针的申明 (Declaration) 方式如下:
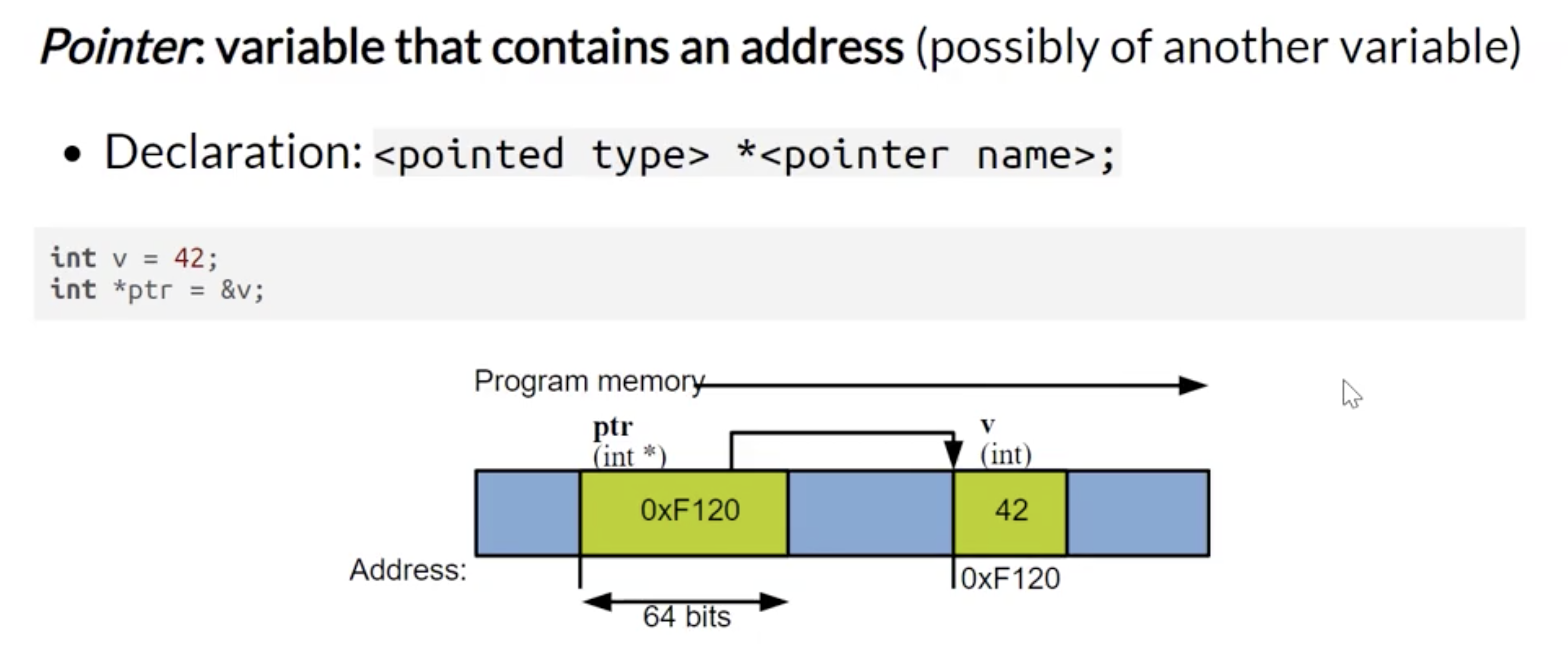
由于指针存储的数据是某个内存地址, 因此指针可以被 间接引用 (Dereferencing), 程序可以通过间接应用指针将 指针所存储的内存地址视为某个变量的内存地址, 尝试访问这个变量.

指针的定义本身看上去非常简单, 但由于通过指针我们可以实现对特定内存地址的直接读取和各种操作, 因此利用指针可以实现花样繁多的高端操作. 下面我们讨论指针的应用:
指针的应用
首先我们可以利用指针直接存储内存地址的特性 突破 C 语言中 “任何函数的参数的引用方式都是拷贝” 这一限制.
通过将某个变量的指针 (也就是存储这个变量的内存地址的指针) 作为参数传入函数内, 我们就可以通过修改 这个指针所存储的内存地址对应变量的值 来实现对 “真正的函数参数” 的修改:


注意上图中 *param++ 的含义是: 对指针 param 的间接引用 *param (在这个语境下就是变量 $x$ 的值) 加 $1$, 因此得到的效果是变量 $x$ 被从 $20$ 修改为 $21$.
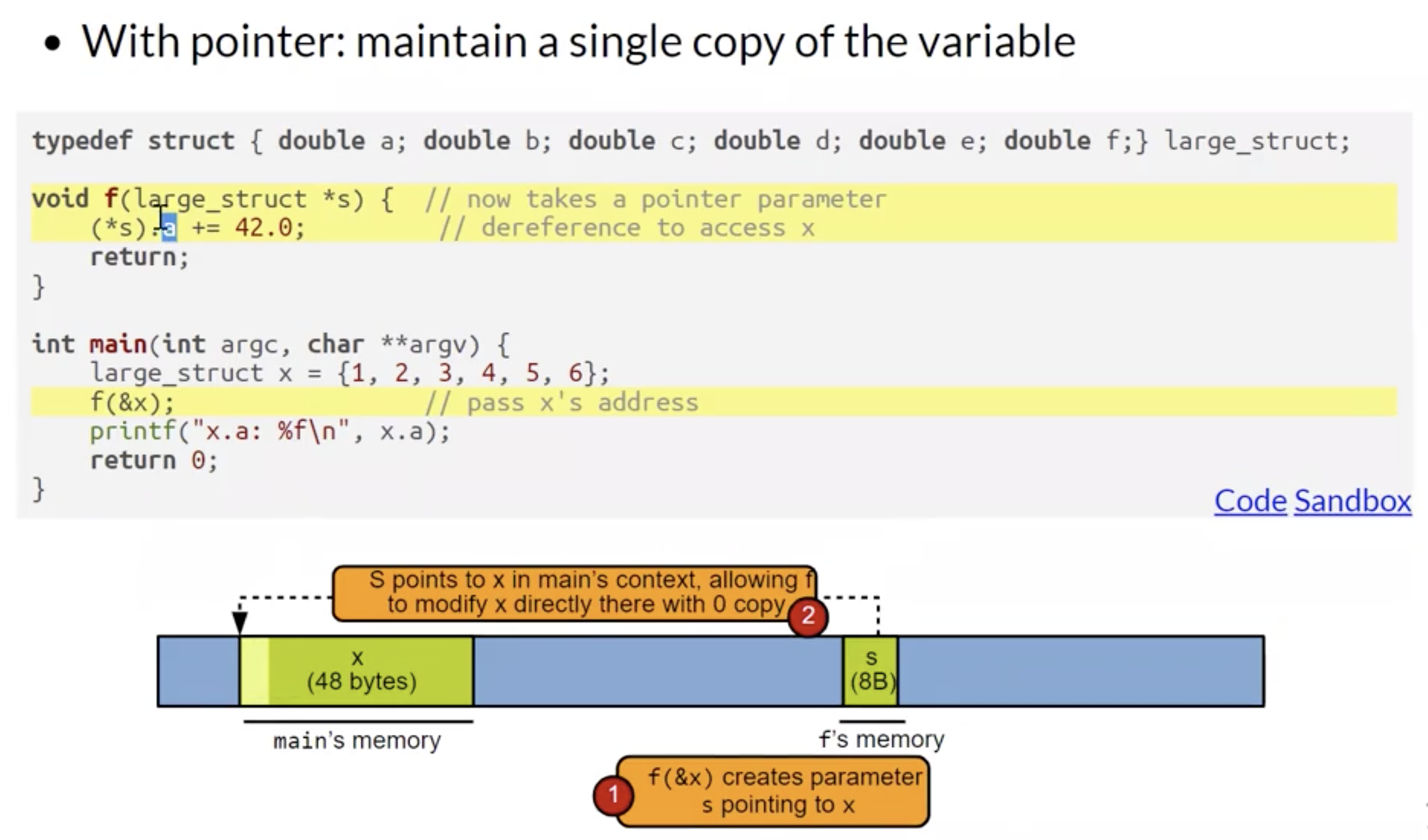
突破函数参数拷贝式引用限制的使用场景除了修改函数参数外, 还包括避免在引用函数时拷贝过于庞大的结构体/变量节省资源开销的情形. 考虑下面的例子:

由于 C 语言规定任何函数的参数引用方式必须为拷贝, 因此要修改这个庞大的结构体 $x$ 中某个字段的值, 我们不得不拷贝整个结构体, 造成巨大的资源浪费.
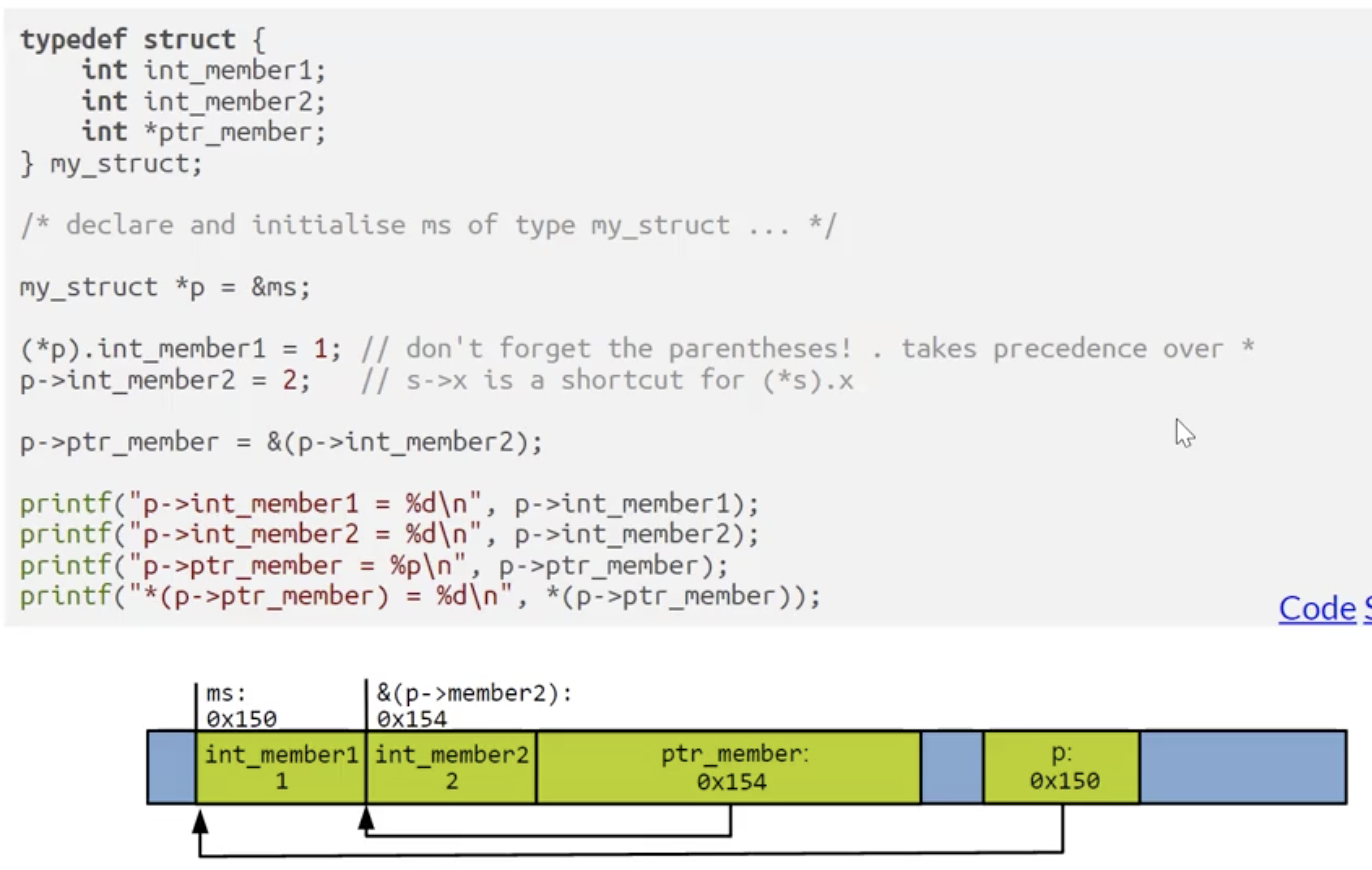
对应的解决方式就是将该结构体的地址 $&x$ 作为参数传入函数中. 由于我们对应地将函数 $f$ 的输入参数类型设为了指针 large_struc *s 类型, 因此我们在函数内部可以直接调用存储着外界被修改结构体 $x$ 内存地址的指针 $s$. 通过使用 (*s).a (或它对应的语法糖 s->a) 间接引用字段 a, 就可以修改该结构体对应字段 a 的值, 完全避免了对庞大的结构体 $x$ 的拷贝.
其次, 我们可以利用指针间接地实现让函数返回多个值的目的.

在上面的例子中, 函数 multiply_and_divide 实际的效果是修改变量 product 和 quotient 的值, 等价于同时返回了除法和乘法的结果.
更进一步地, C 语言中定义为数组数据类型的变量实际上存储的数据就是该数组第一个元素所在的内存地址, 因此 C 语言中的数组就是指针. 因此, 我们可以利用这一特性进行各种荒诞离奇的操作:
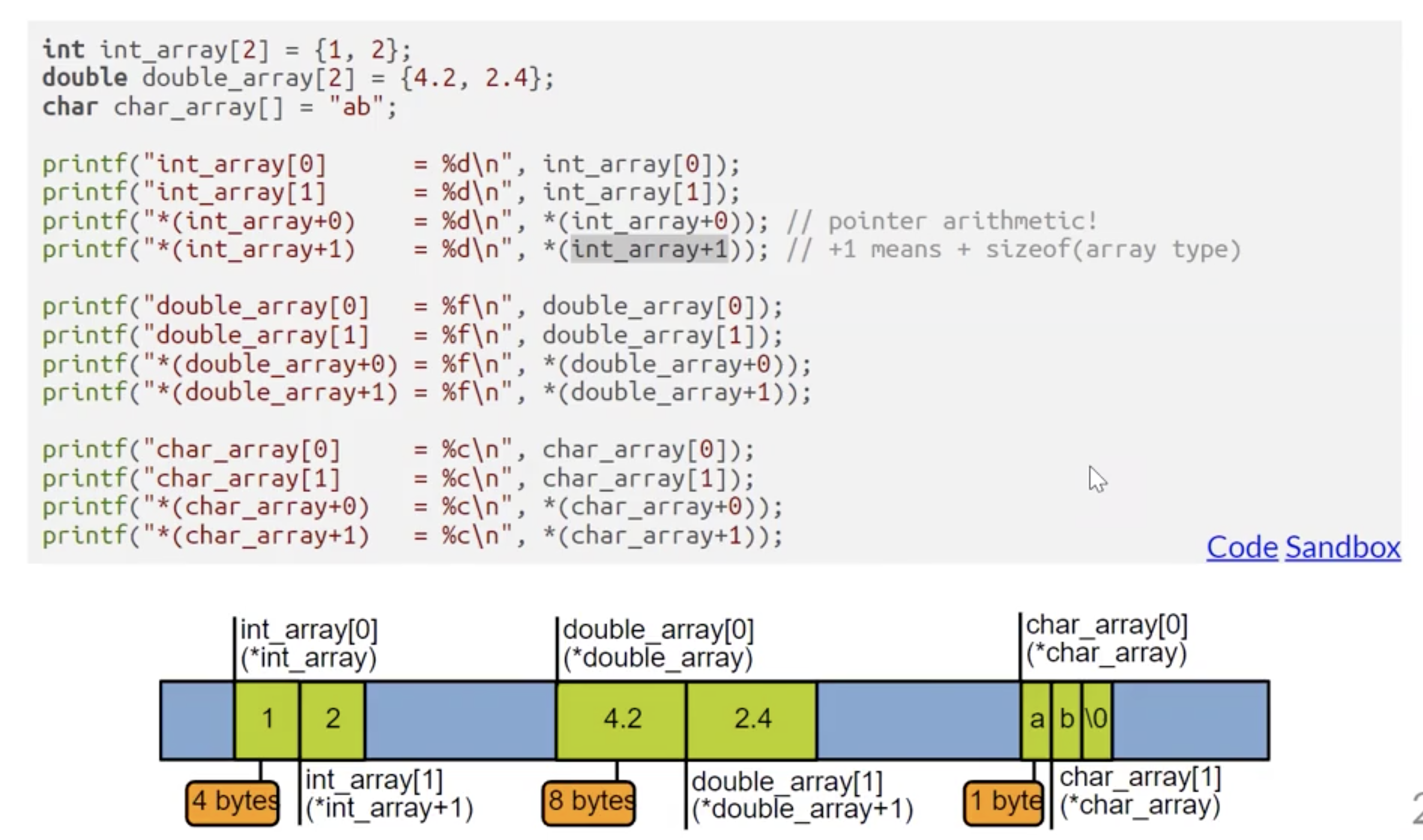
注意此处 *(int_array+1) 执行的操作并非先将指针 int_array 的内存地址数值+1后再执行间接引用, 而是会 自动检查该数组存储的数据类型 array_type, 然后执行指针运算, 将指针的内存地址加上 1 * sizeof(array_type) 后再引用!
也就是说, 假设 p 为某个整型数组, 则有:
p[k] = *(p + k)p[k]+1 = *(p + k) + 1&p[k] = p + sizeof(int) * k
更重要地, 如上面第二个例子所示, 我们可以使用指针进行对结构体字段的间接引用.
最后, 我们还可以自然地利用指针支持嵌套引用的特性玩指针叠叠乐. 而实际上这一技术被用于多维数组的表示之中: 以二维数组 int p[114][514] 为例, 我们可以将其视为一个存储了 114 个指针的一维数组, 而 p 因为存储了该数组中第一个元素的内存地址, 因此它就是一个指向指针的指针.

动态内存分配和堆栈溢出问题
我们进一步讨论 C 语言中另一个极端重要和困难的问题: 动态内存分配.
动态内存分配问题进一步分为 堆内存分配问题 和 内存溢出问题.
我们首先讨论为何要进行动态内存分配:
显然地, 在多种情况下, 程序中一些数据结构所需要的内存大小是无法被预先确定的, 比如考虑某个维度为用户输入的数组, 它的尺寸无法在用户给定输入前预先确定; 同时, 由于 C 语言中的数组 无法被动态扩充, 假如我们需要用 C 编写哈希表, 在表的利用率到达阈值需要重哈希时就无法直接利用原来存储数据的数组 (回顾COMP26120相关知识).
同时, 在 C 语言中, 接受变量作为尺寸输入的数组 (Variable Sized Array) 存储在内存中的位置称为 栈 (Stack), 这是一片在内存中划分出来的 非常小的 空间, 在 Linux 上默认只有 $2$MB 大小, 因此也无法用来存储大尺寸数组, 否则就会因为用光了栈内空间而导致栈溢出.
因此可以看到, 使用常规的 Variable size arrays 有明显的局限性. 我们需要利用 动态内存分配 来更加自由地为变量分配对应的内存空间.
我们下面讨论程序所分配的内存空间中的 内存分配布局 (Program Memory Layout):
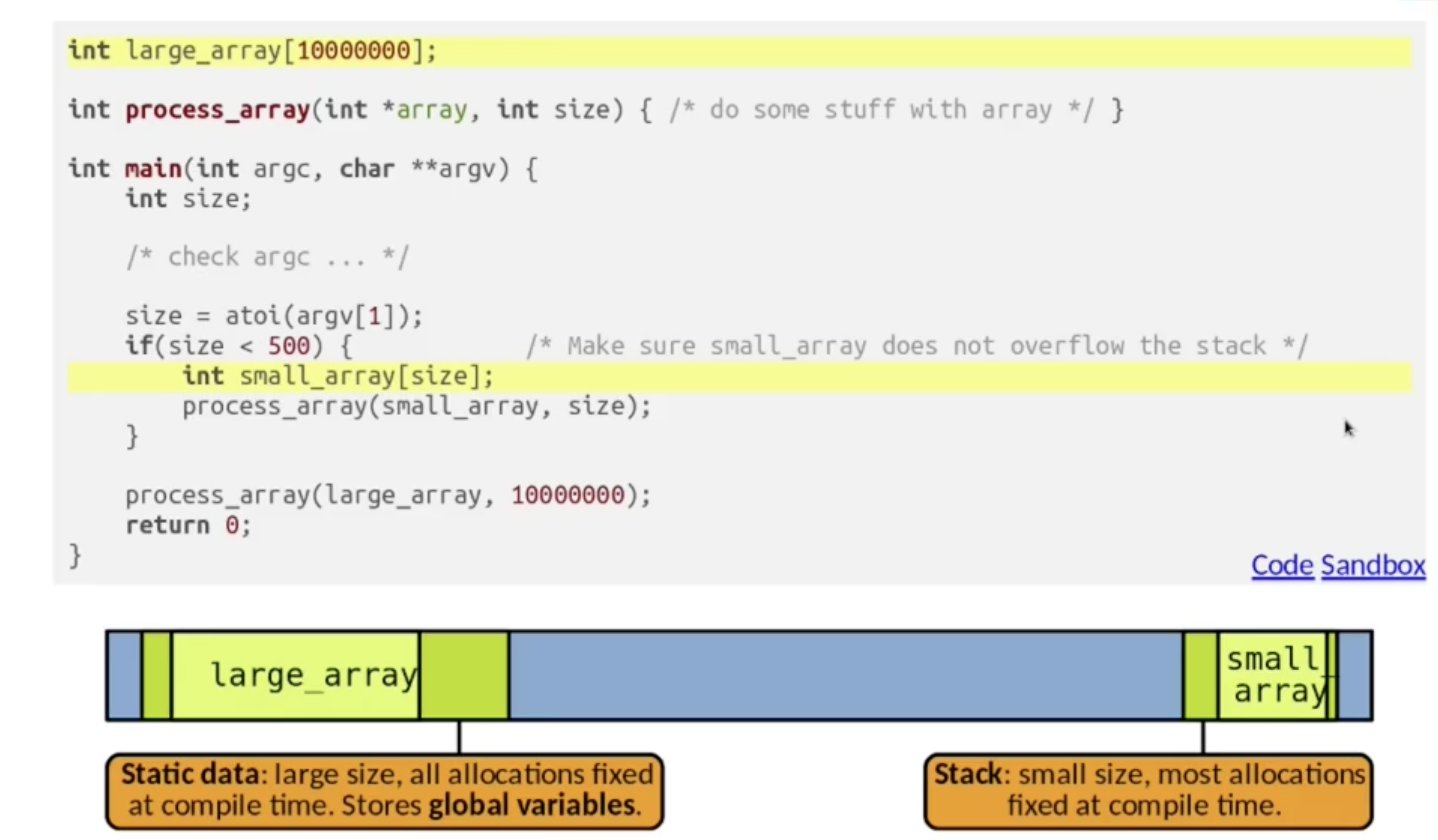
以上图所示的程序为例: 接受数字作为尺寸输入的数组 large_array[10000000] 作为全局变量 (对全体函数均可用, 可以视为大小不再改变的数据) 会被存储在 静态空间 (Static Data) 中. 静态空间 专门存储全局变量, 所存储的全局变量的内存分配在程序编译时就会被确定从而不再改变.
而在方法 main 内部定义的局部变量 small_array 则会被存储在空间狭小的栈 Stack 中, 而其中绝大多数变量的内存分配也会在程序编译时被确定.
而另一片可以通过 动态内存分配 利用的内存空间就是 堆 (Heap), 它的大小一般远大于栈, 而且在此之中所有的内存分配都是 动态 的.

对堆的访问和利用可以通过 动态内存分配方法 malloc() 实现, 它接收的唯一参数是 要在堆里动态分配的内存空间大小, 如果内存分配成功返回的将会是对应数据类型的指针, 如果内存分配失败将会返回 NULL.
基于上面的例子, 将局部变量小矩阵使用动态内存分配方法, 存储在堆中的新例子如下:
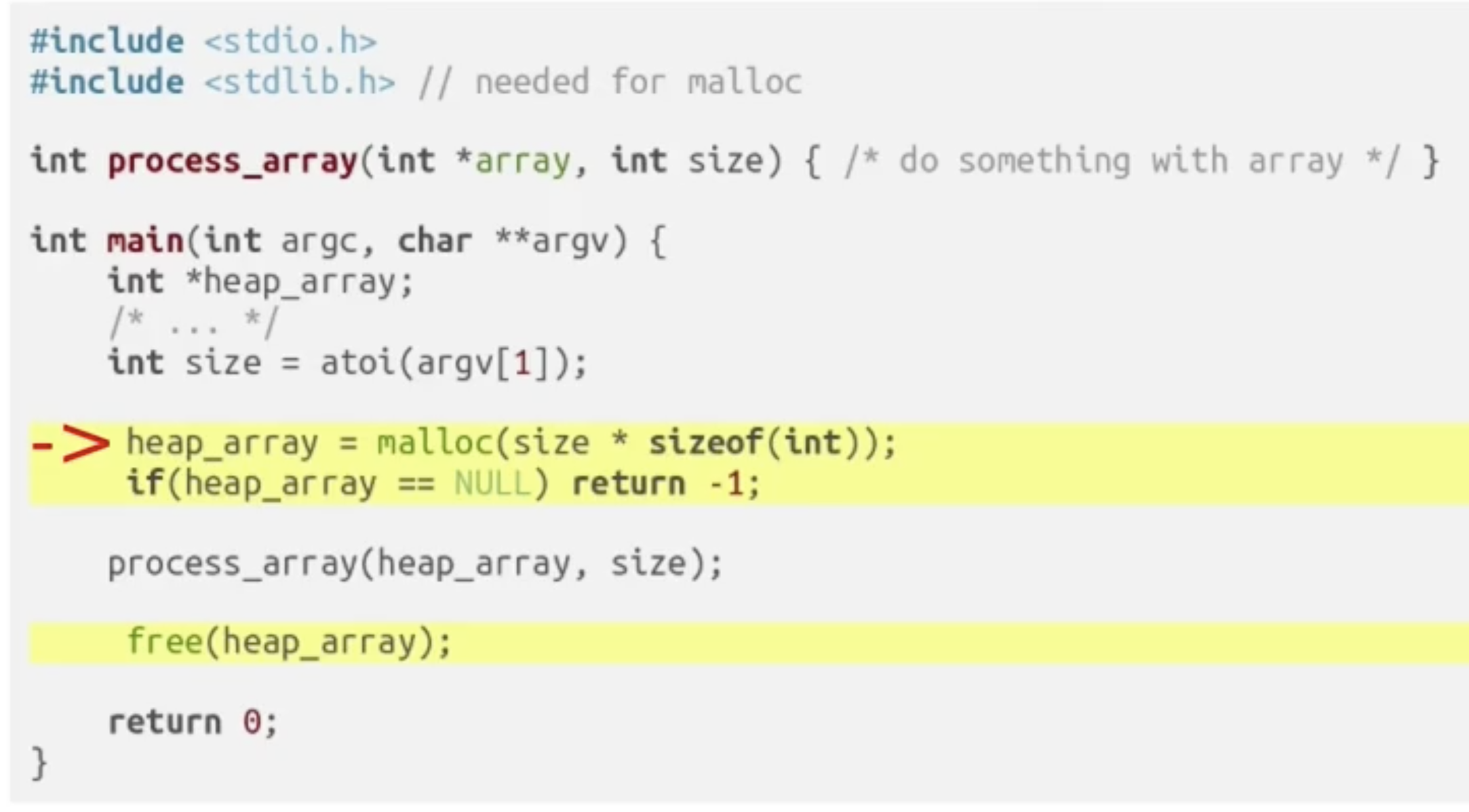
注意箭头处调用 malloc() 的方式以及调用之后立刻进行的, 对内存分配是否成功的检测. 如果不做检测直接假定内存分配总是成功的话, 在后面调用这个变量的时候就会出现一些非常麻烦的问题, 因为程序会尝试访问实际上并没有被分配到的内存空间.
更为重要的是, 使用 malloc() 分配的所有内存空间都需要 在用完之后使用 free(<用malloc分配堆空间的对应变量的指针>) 释放堆空间, 或者称内存垃圾回收. 由于 C 不像 Java 一样会自动进行垃圾回收, 如果我们不主动释放空间的话这些被分配的空间就会一直存在而无法分配给新的变量, 最终导致堆空间用光, 发生堆溢出.
我们最后对 堆内存分配函数 malloc() 的使用和注意事项总结如下:

注意其返回值类型 void * 实际上指的是 “通用类型的指针”, 也就是说 malloc 返回的指针类型可以是任意种 (int, double, long long long float*, …).
动态内存分配的利用案例
首先考虑下面的例子:

在这个例子中, 指针 ptr1 和 ptr2 分别属于程序中的全局变量和方法里的局部变量, 因此根据上一小节介绍的程序内存布局相关知识, 可知它们还是会被分别分配在静态空间和栈内存储, 而指针的大小等于内存地址的大小, 和计算机硬件/操作系统相关: 在 $n$ 位操作系统/硬件上, 指针的大小就是 $\frac{n}{8}$ 字节.
由于我们都使用动态内存分配 malloc 为对应的指针分配了长度不一的内存空间, 这些被分配的内存空间都位于堆中. 可见, ptr1 此时实际上是一个长为 $10$ 的浮点型数组, 而 ptr2 是长为 $30$ 的整型数组.
其次, 我们考虑多维数组的例子. 回顾指针应用中 “指针叠叠乐” 一节, 我们可知:
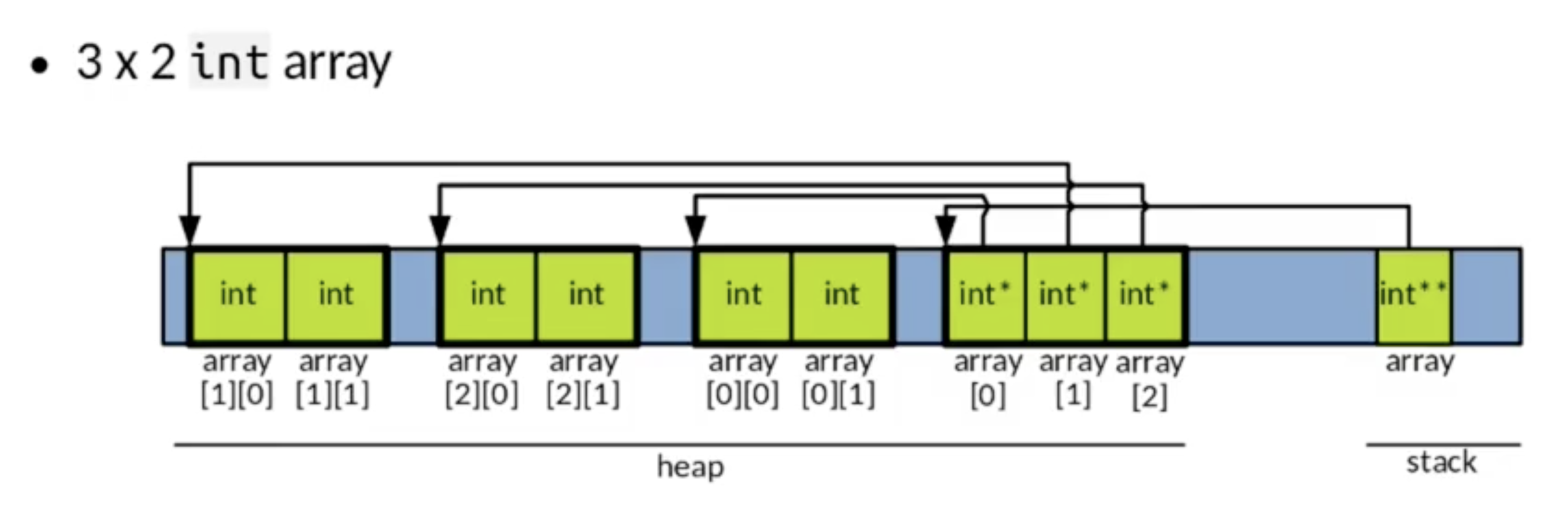
对于多维数组而言, 它的第一维 (行数组) 实际上就是一个 存储了指向每一个行数组第一个元素的指针的一维指针数组.
因此, 使用 malloc 为多维数组在堆中分配内存空间时, 首先还是要从最外层的行数组开始, 并一步步地为每个维度分配空间, 如下图所示:

同样, 注意每次执行内存分配后立刻进行的内存分配成功与否的检查, 以及在程序最后的垃圾回收.
C标准库
我们在本节中介绍 C 语言中常用的一些标准库. 通过利用这些标准库, 我们可以在 C 语言程序中执行一系列贴近底层的操作.
字符串操作
i. 字符串复制: strcpy / strncpy
回顾对字符串的定义, 我们知道在 C 中字符串等价于字符数组等价于数组等价于指针, 因此我们若要进行字符串复制, 绝对不可使用 =, 否则我们所做的只是 对指针的复制, 生成的还是对原字符串的引用而不是进行真正意义上的复制.
要复制字符串, 需要使用 strcpy() / strncpy(). 其用法和示例如下:
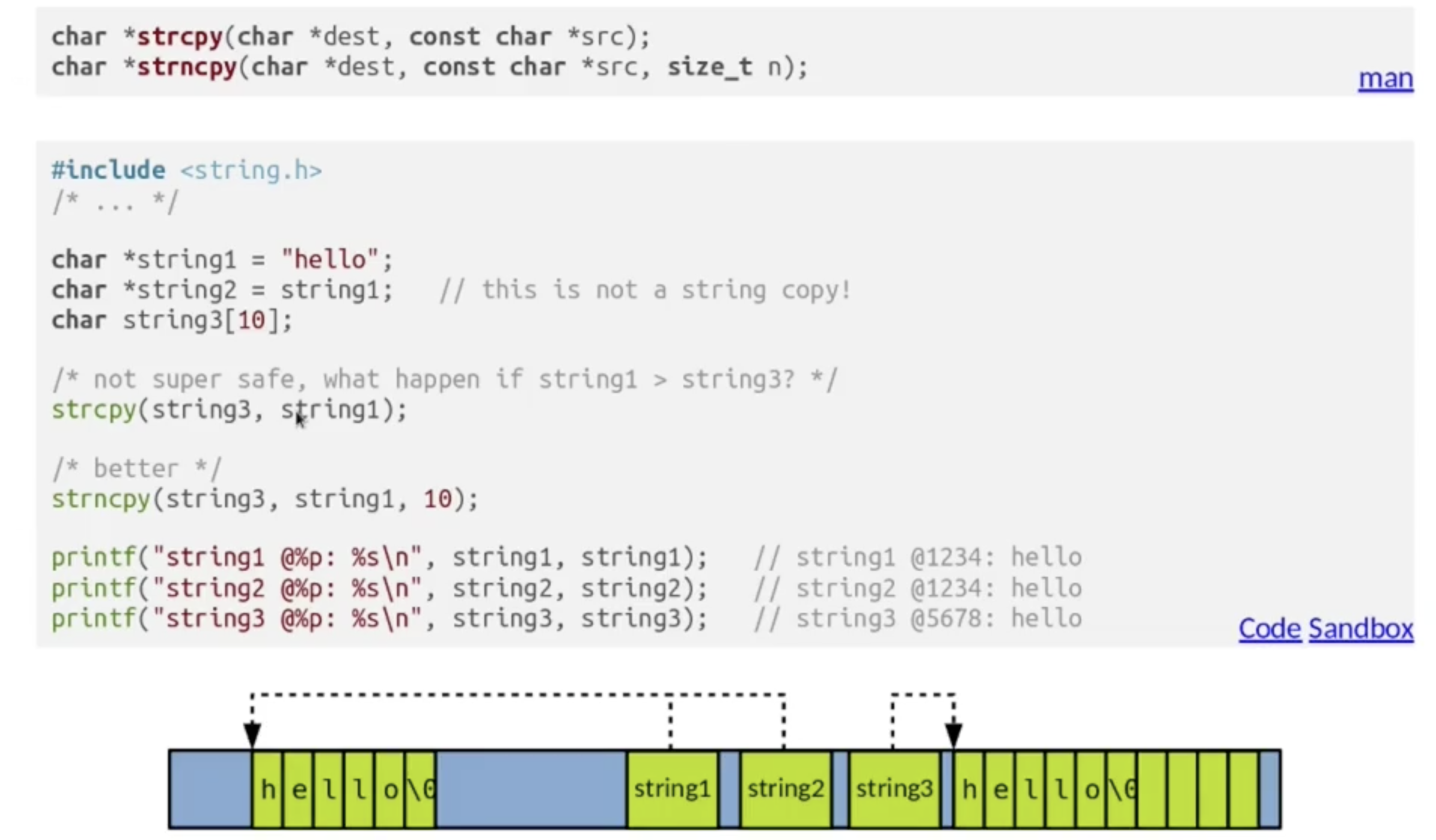
注意 strcpy 不加检查地 将源字符串存储的所有内容完整拷贝到目标字符串首指针开始的内存空间内, 因此 必须确保目标字符串被分配了足够的内存空间, 否则就会出现各种乱七八糟的结果 (如覆盖了堆中其他变量的内存空间).
因此更为安全的做法是使用同时接受 “最大拷贝位数” 参数的 strncpy(), 确保在字符串拷贝操作时不会出现溢出的情况.
其次, 由于这两个方法执行的操作是 对字符串的复制, 因此它们也会将源字符串尾的终止符号 \0 一并复制.
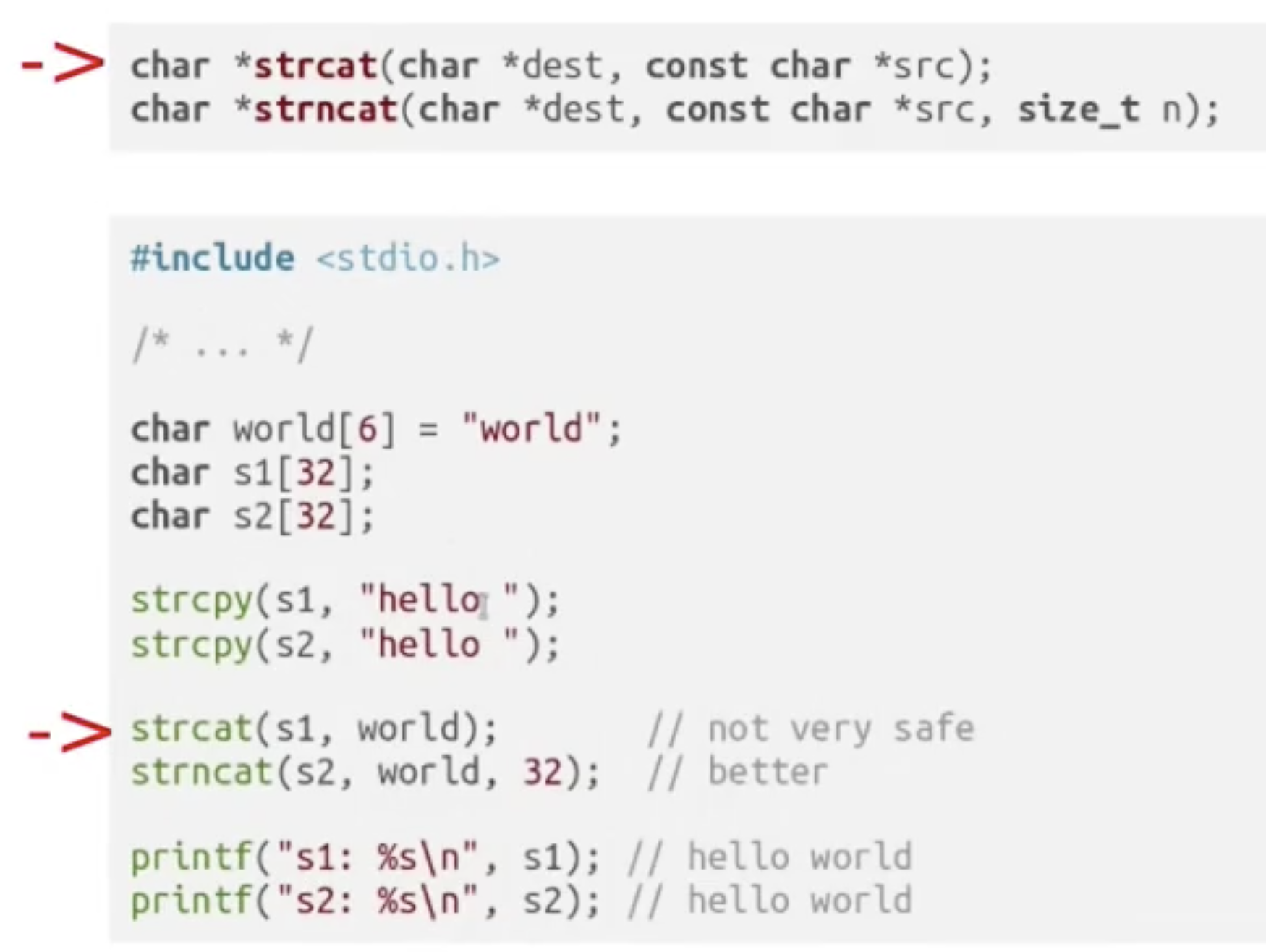
ii. 字符串拼接: strcat / strncat
相应地, C 语言也提供了两种字符串拼接方法:
iii. 格式化字符串构造: sprintf
我们可以使用 C 提供的 格式化字符串构造 用形如 printf() 的方式通过 “向字符串中填入对应的参数” 构造不同的字符串:

同样地, 我们需要确保被写入的字符串 (字符串数组) string 的 大小足够.
iv. 字符串比较和信息提取
C 还提供了方便的字符串长度检查方法与字符串比较方法:
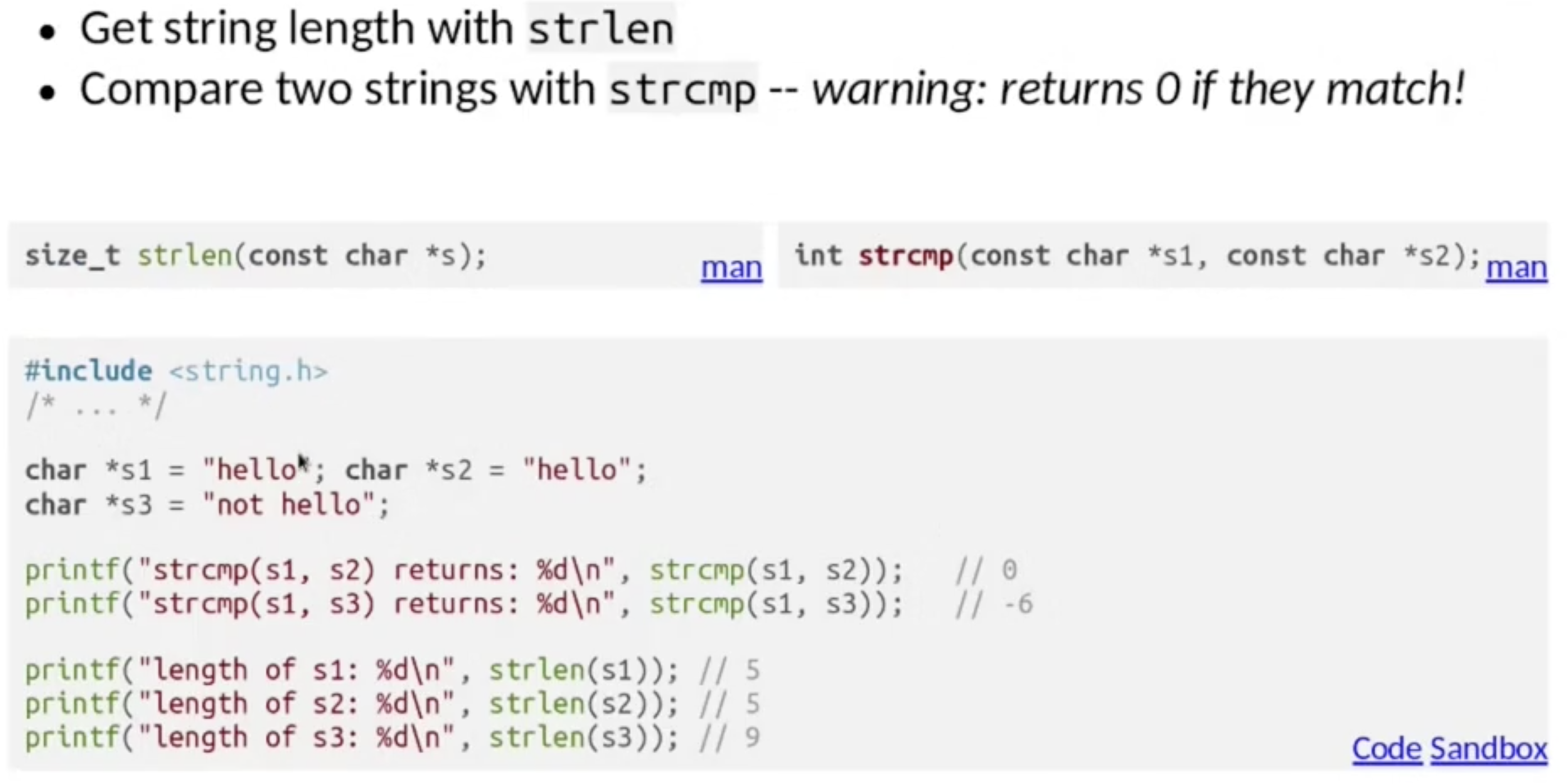
注意 strlen() 返回的是 不包含字符串数组末尾终止符号 的, 字符串的真实长度.
命令行用户输入提取
C 提供了 fgets 和 scanf 两种用于从命令行中提取用户输入作为程序输入的方法:
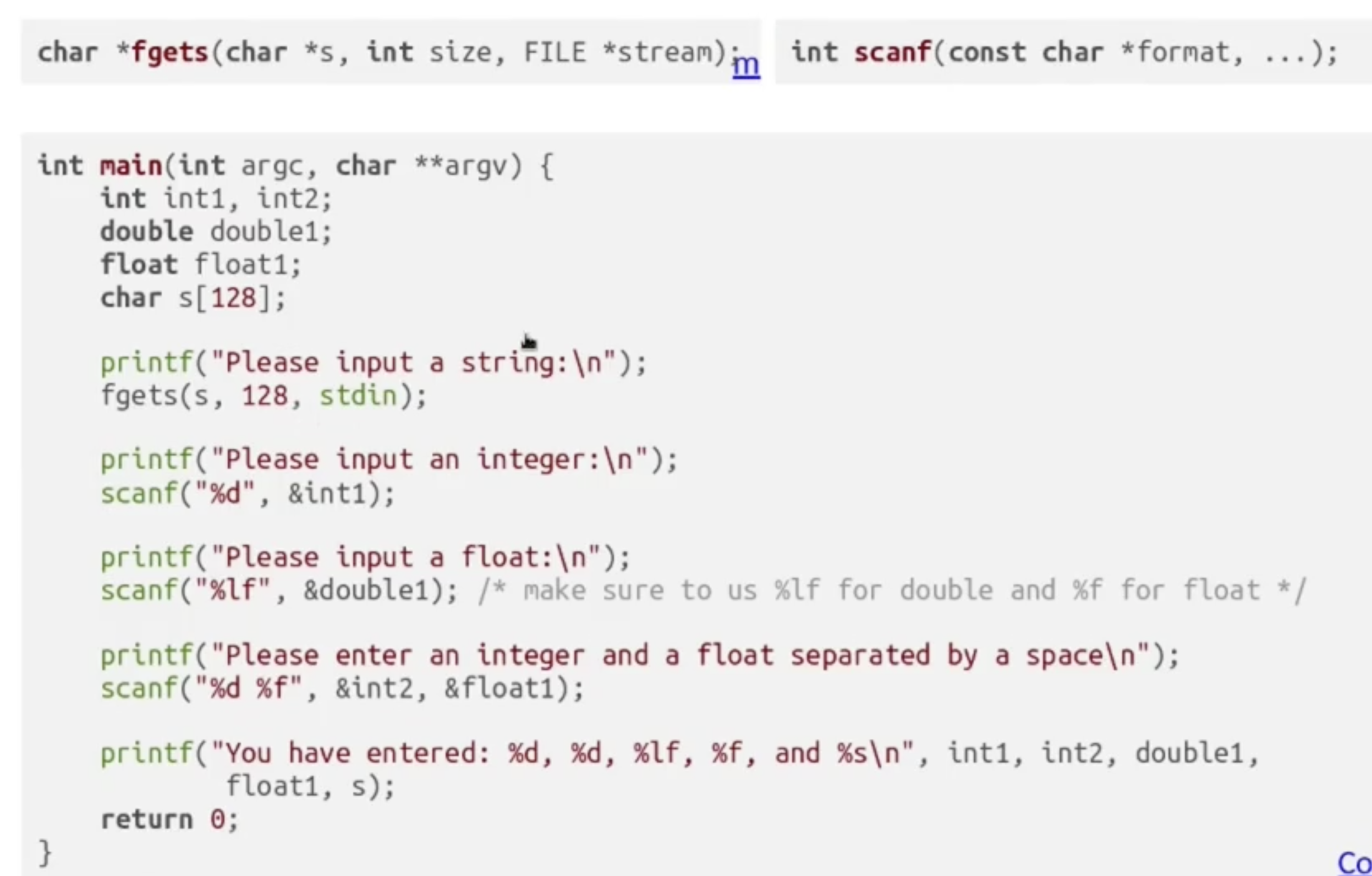
其中 fgets 将用户的命令行输入转为字符串, 而我们可以使用 scanf 限制用户输入的数据类型和输入格式.
内存操作
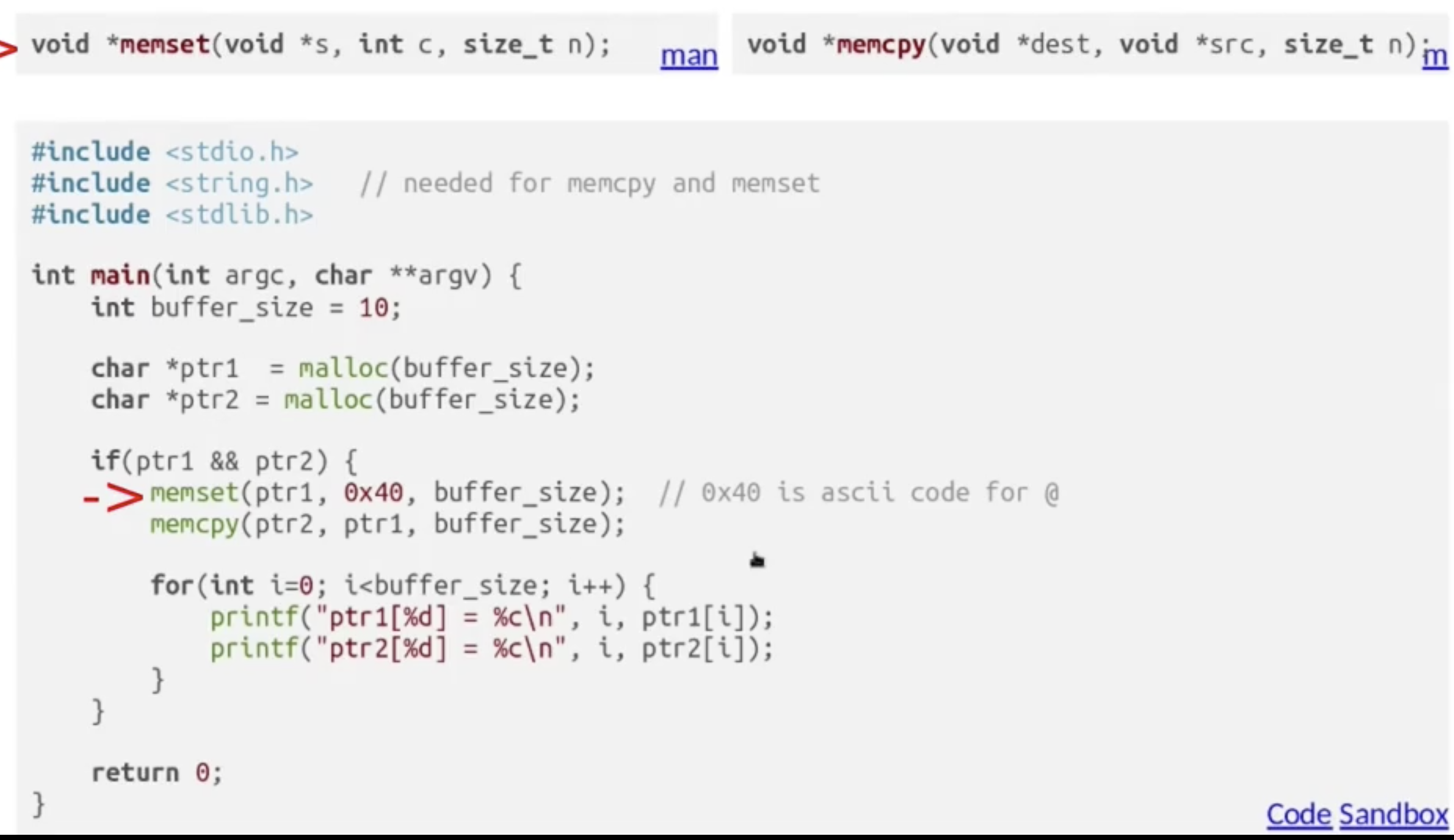
我们还可以使用 memset 和 memcpy 直接进行内存写入和复制操作.
数值运算函数
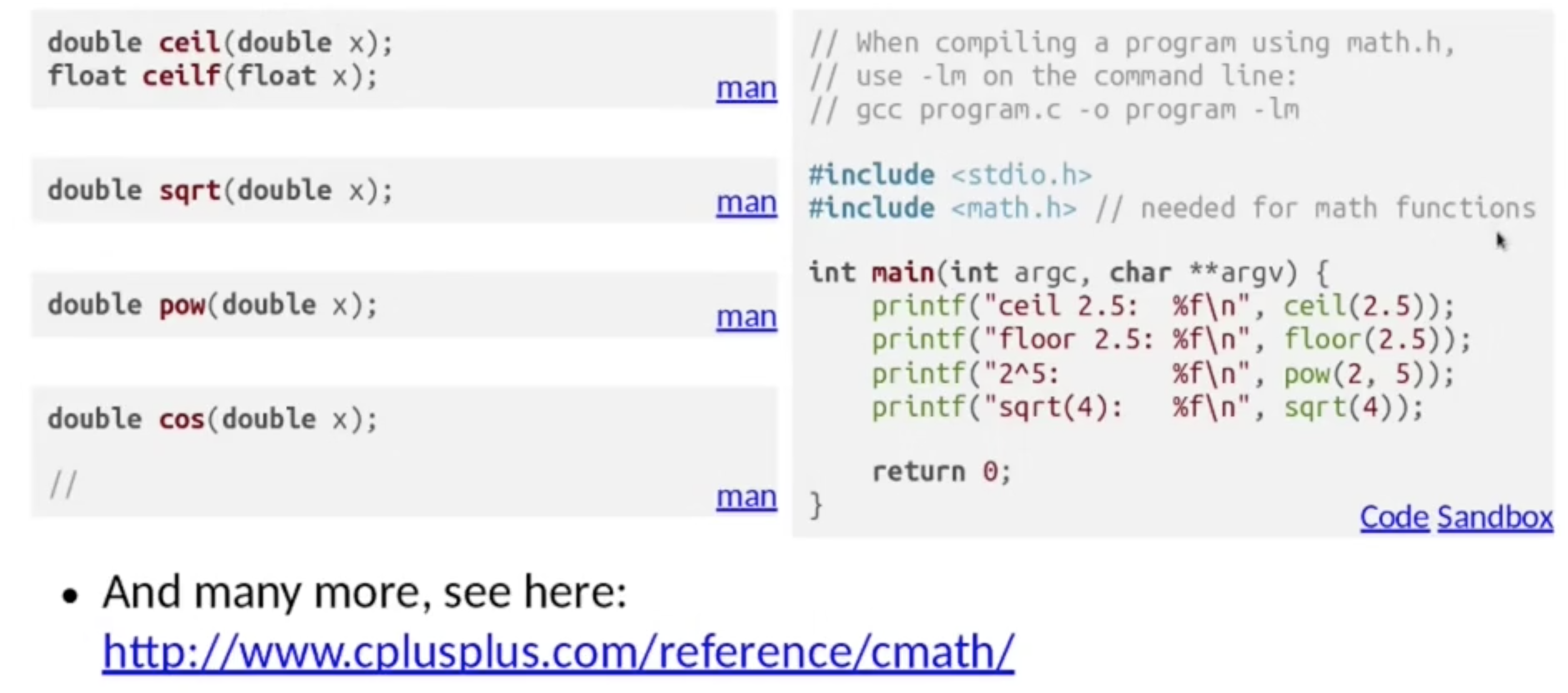
C 还提供了一系列基本的数值运算函数:
程序暂停
我们可以使用 sleep() 和 usleep() 手动暂停程序的执行:
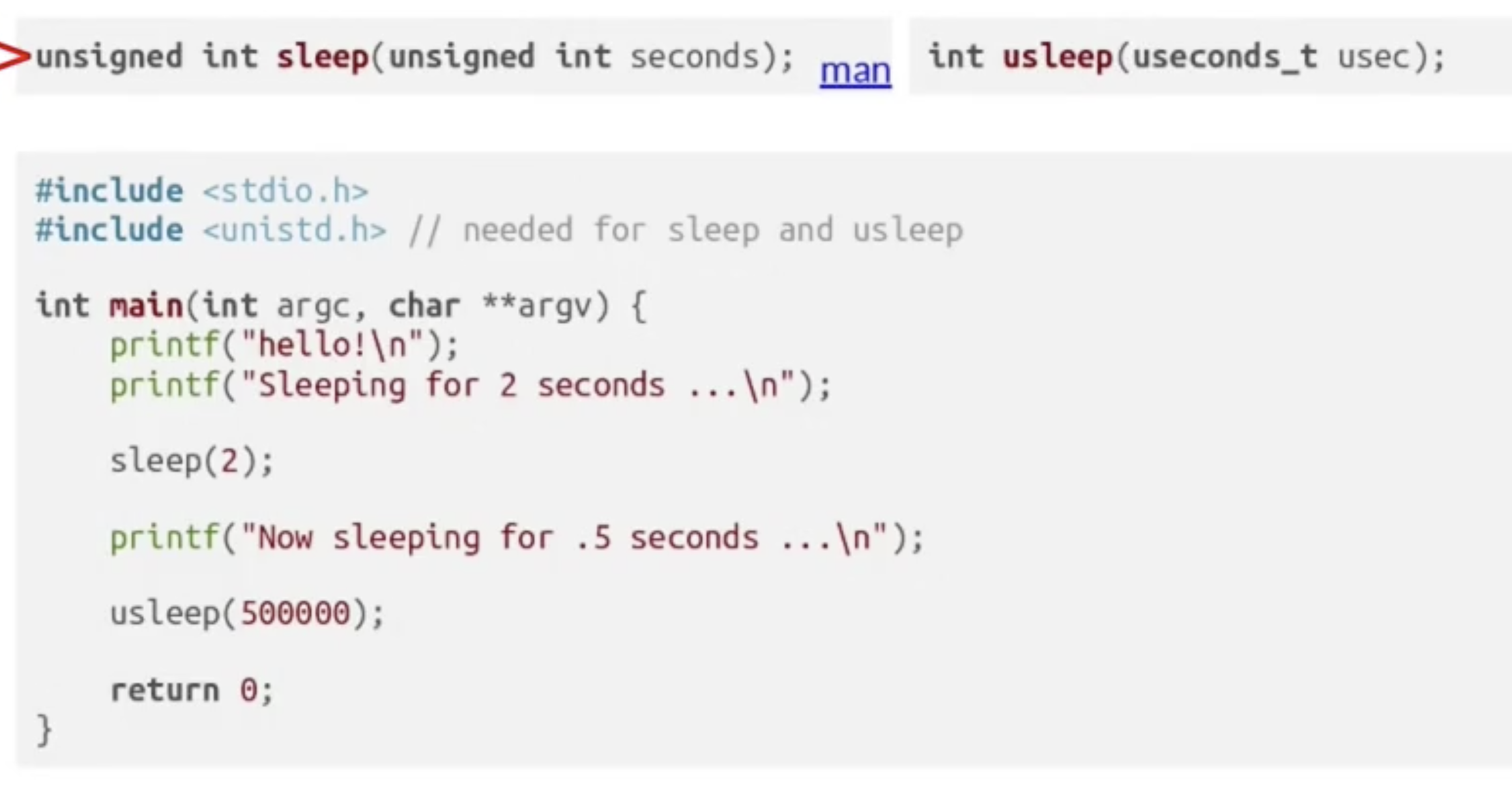
其中 usleep() 的睡眠时间为 微秒 ($10^{-6}\text{s}$), 而 sleep 的睡眠时间为 $秒$.
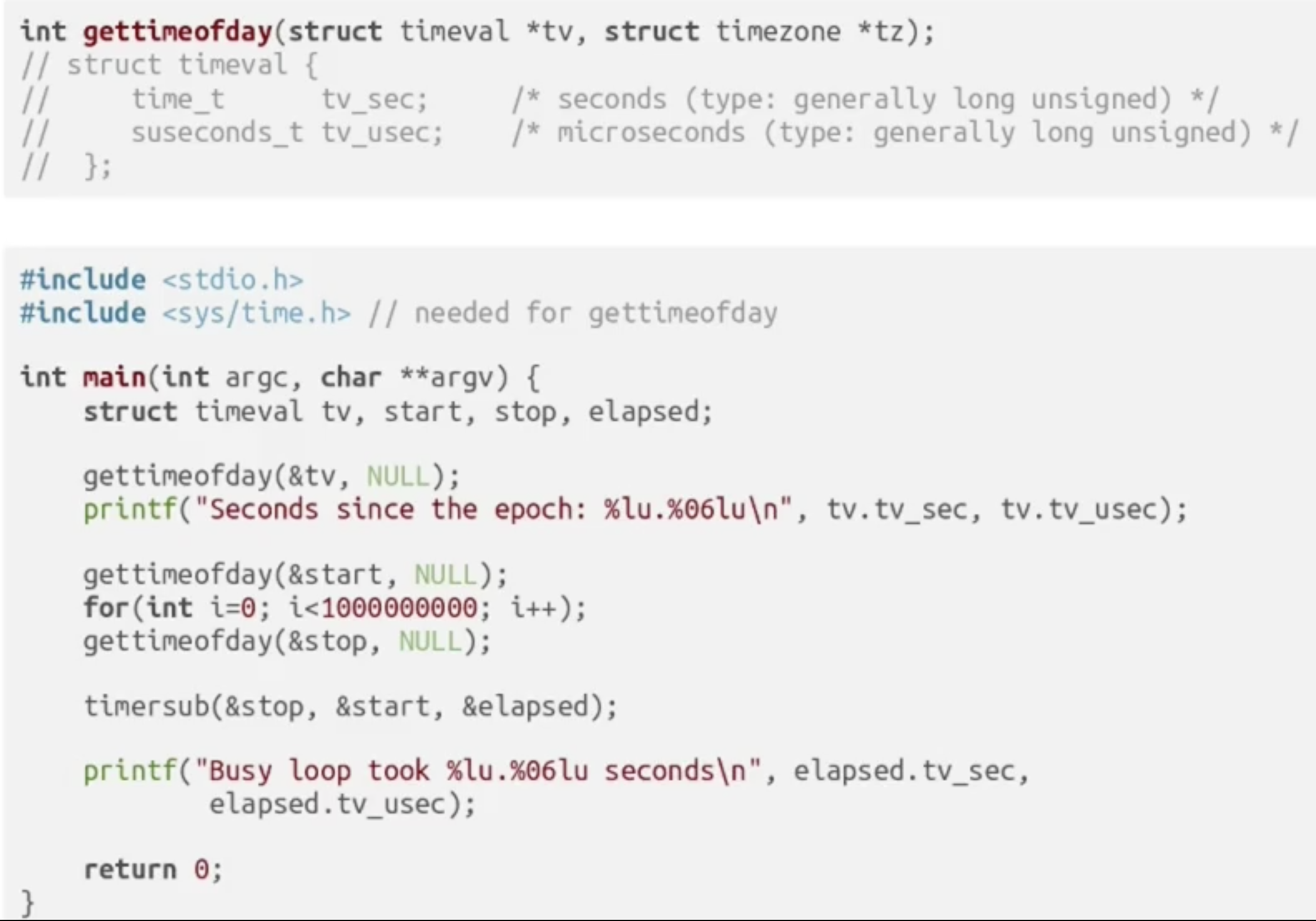
获取当前时间

统计程序运行时间
文件读写
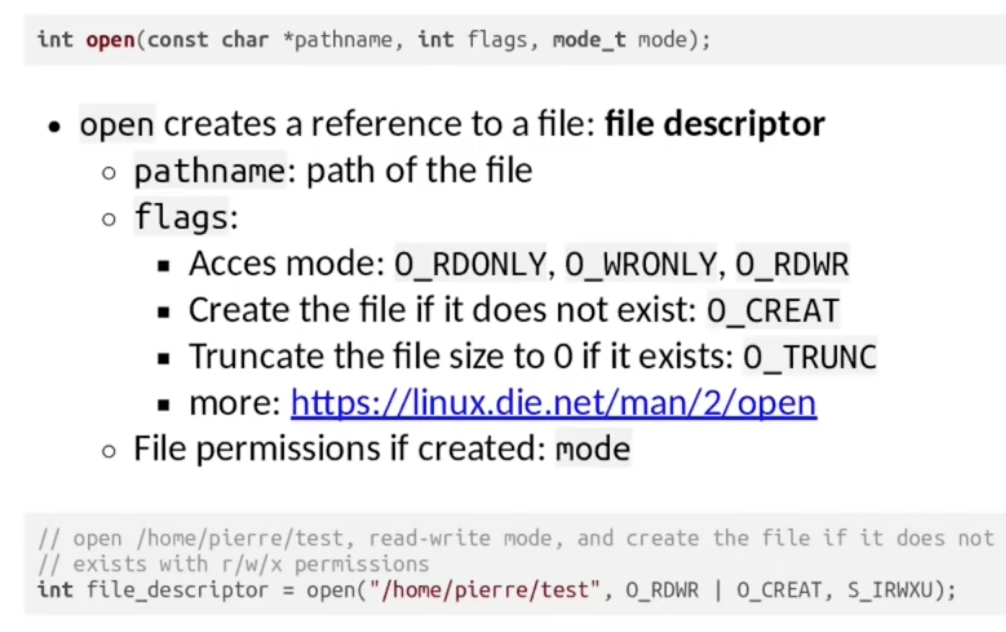
C 中的 文件读取 由 open() 和 read() 组合实现.
首先需要使用 open() “打开” 文件, 获取文件描述器 (File Descriptor):
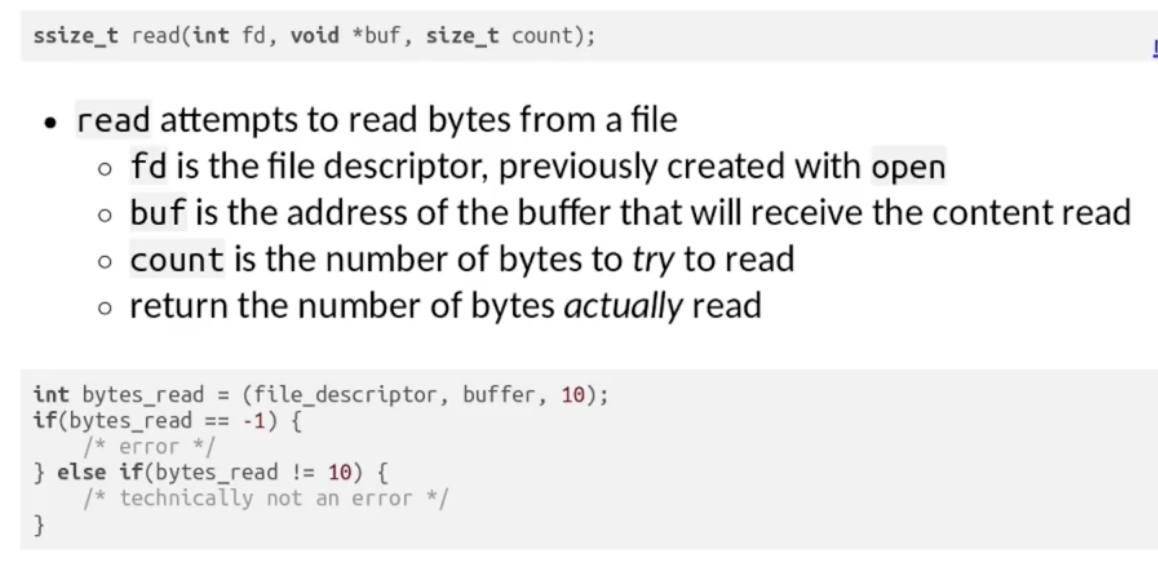
其次就可以使用 read() 尝试从文件描述器所描述的文件中读入给定位数的数据:
同时也可以使用 write() 尝试向文件描述器所描述的文件中写入给定长度的数据:

而在文件读写结束后, 需要使用 close() 关闭文件描述器, 这一步同样 非常重要.
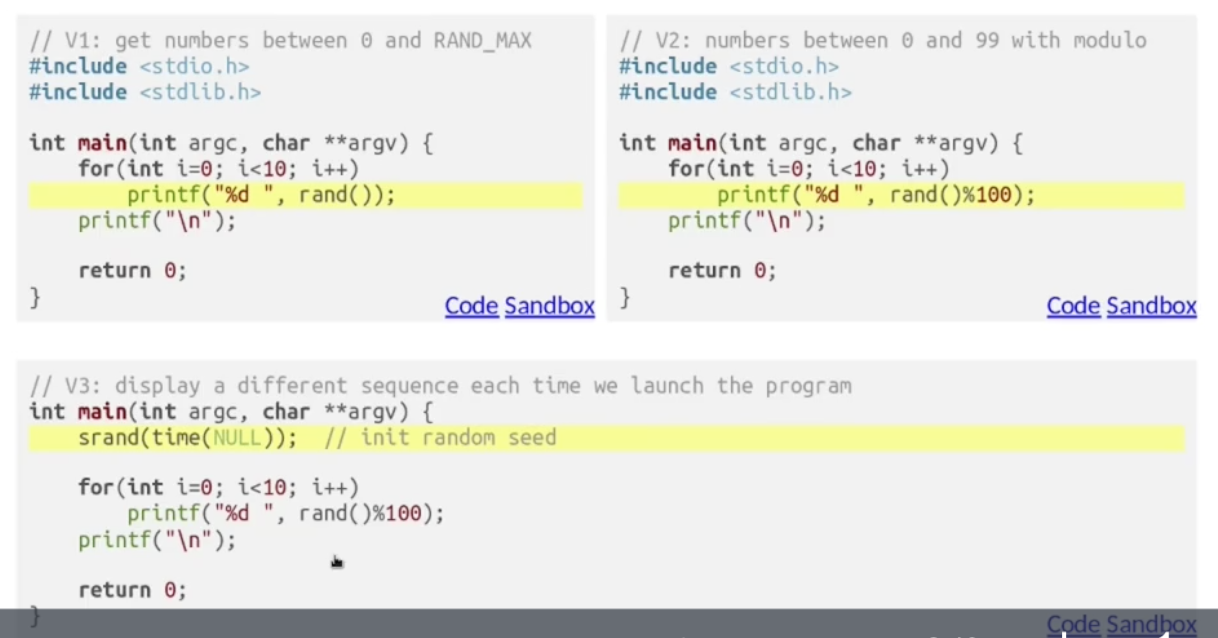
随机数生成
在 C 中, rand() 返回的是 $0 - 32767$ 范围内的 (伪) 随机数. 我们可以使用 srand() 指定 随机种子:
错误管理
C 中的错误管理是通过利用变量 errno (Error Number) 和/或 perror 实现的:

在执行函数出错时, 存储对应错误代码的变量 errno 会自动创建, 我们可以通过访问它得知错误原因, 也可以调用 perror(<出错的函数名>) 获取错误描述.
相关题目解析
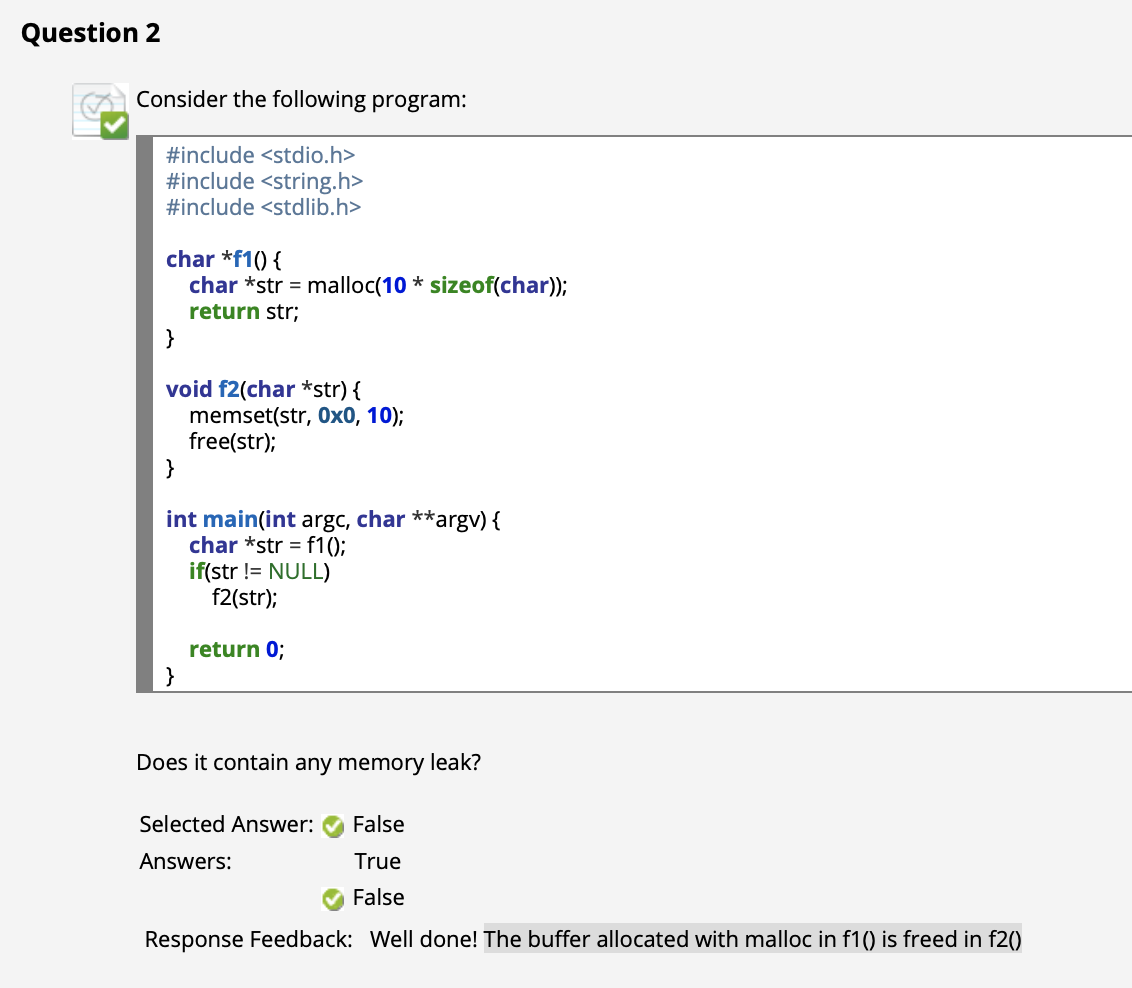

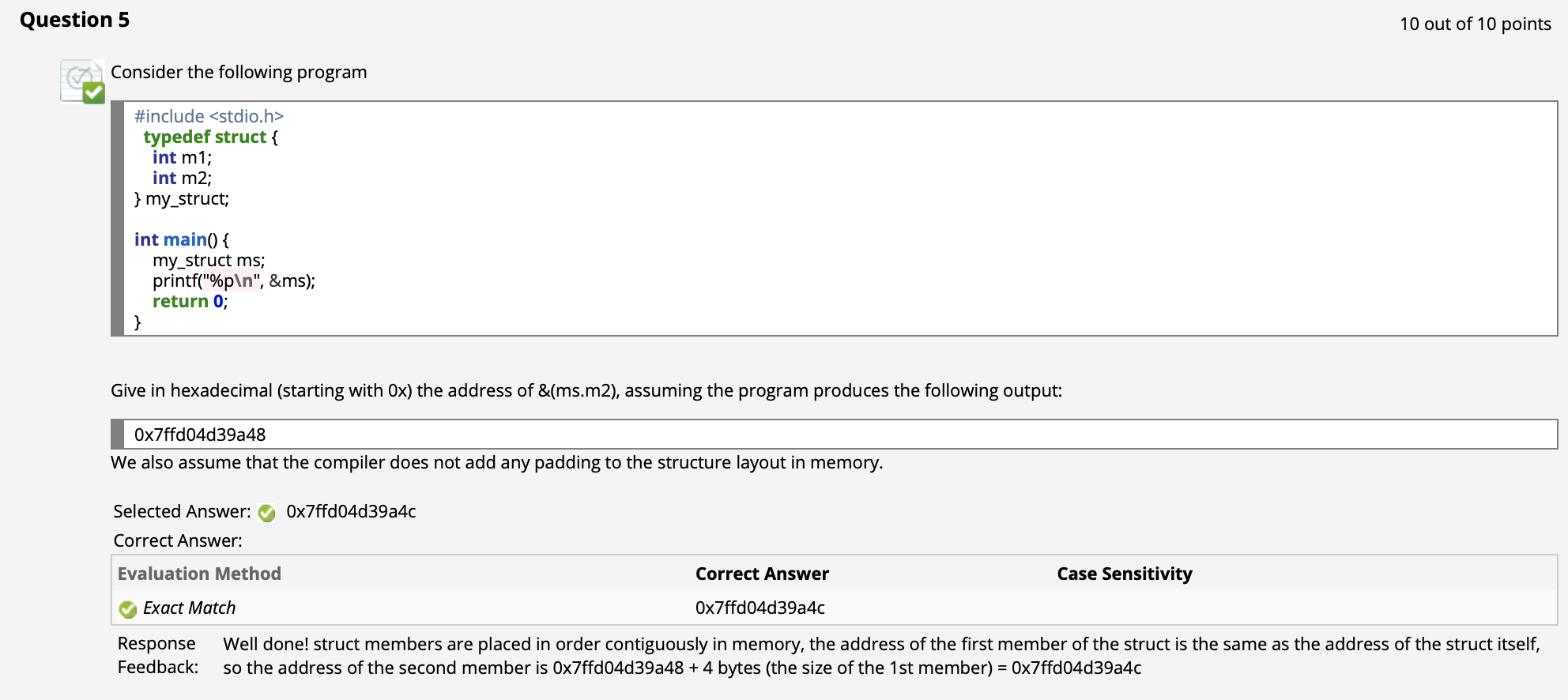
($\uparrow$ 回忆 十六进制 (Hexadecimal) 表示方式)
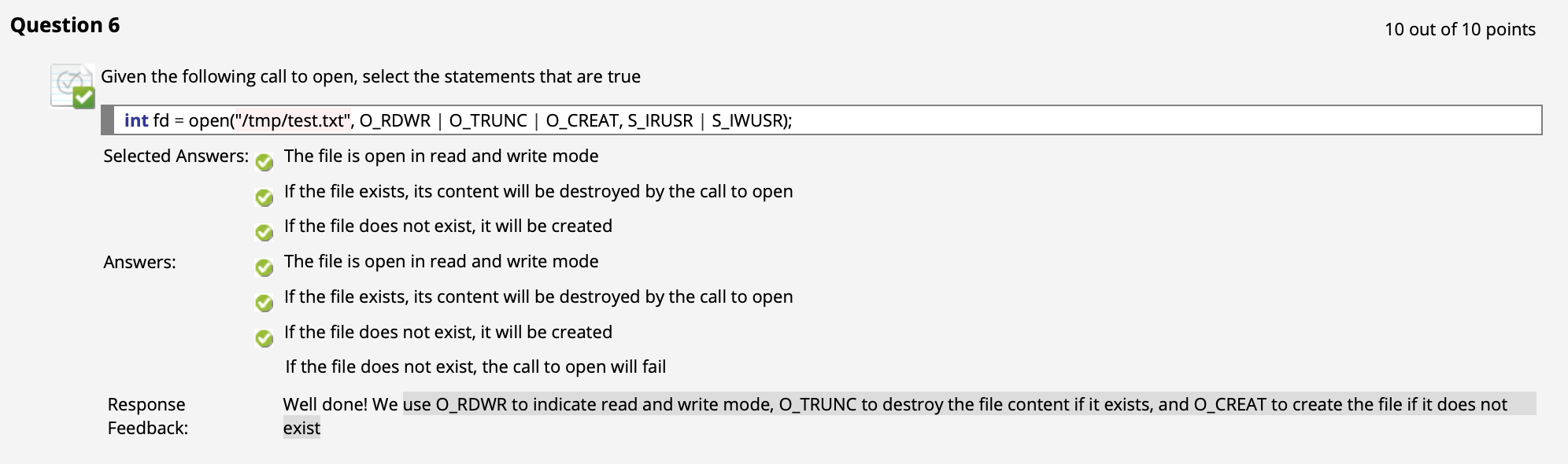

($\uparrow$ 注意一下, 不过应该不考)
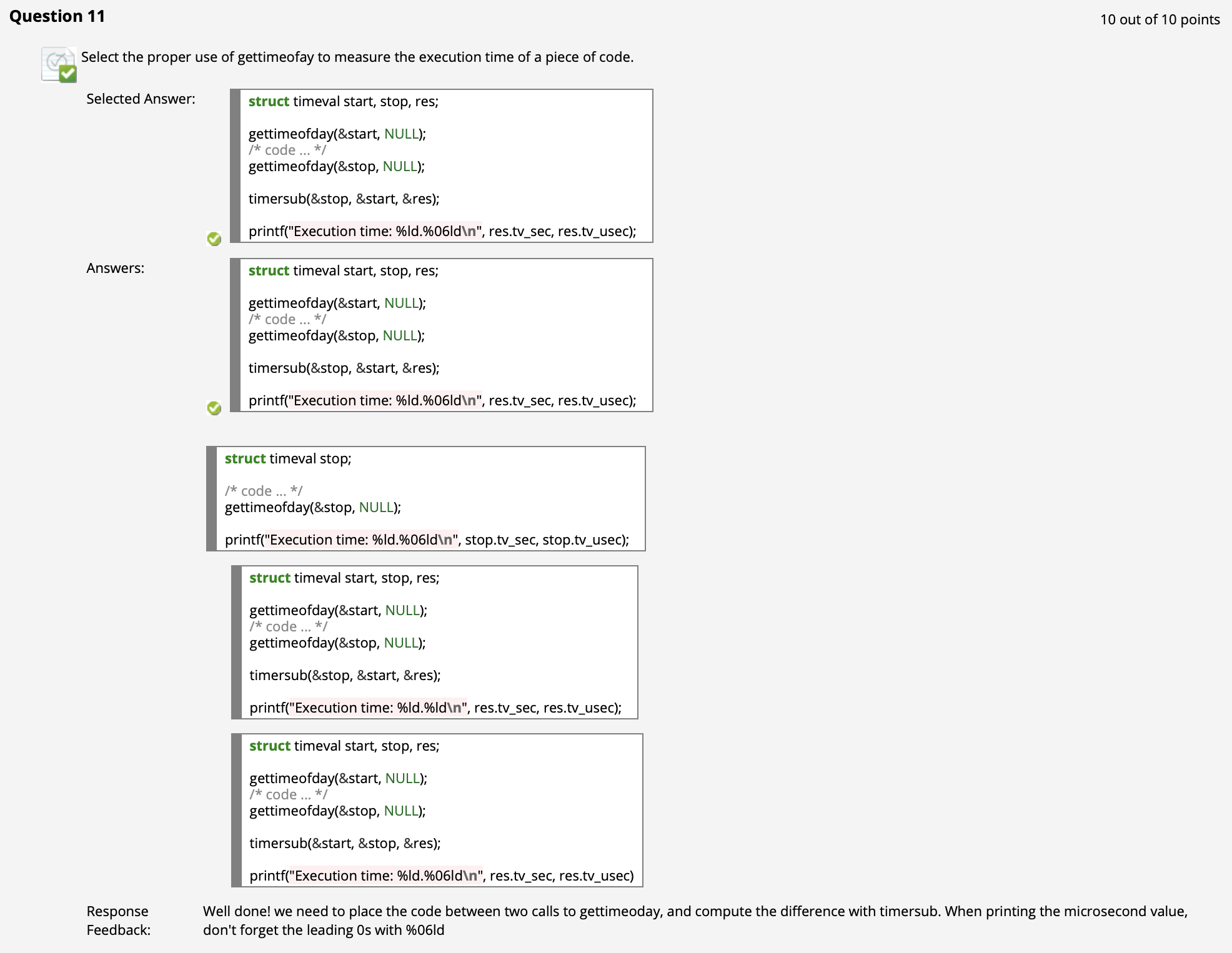
($\uparrow$ 注意用法: 1. 注意表示微秒用.06 2. timersub(后, 前, 结构体名))
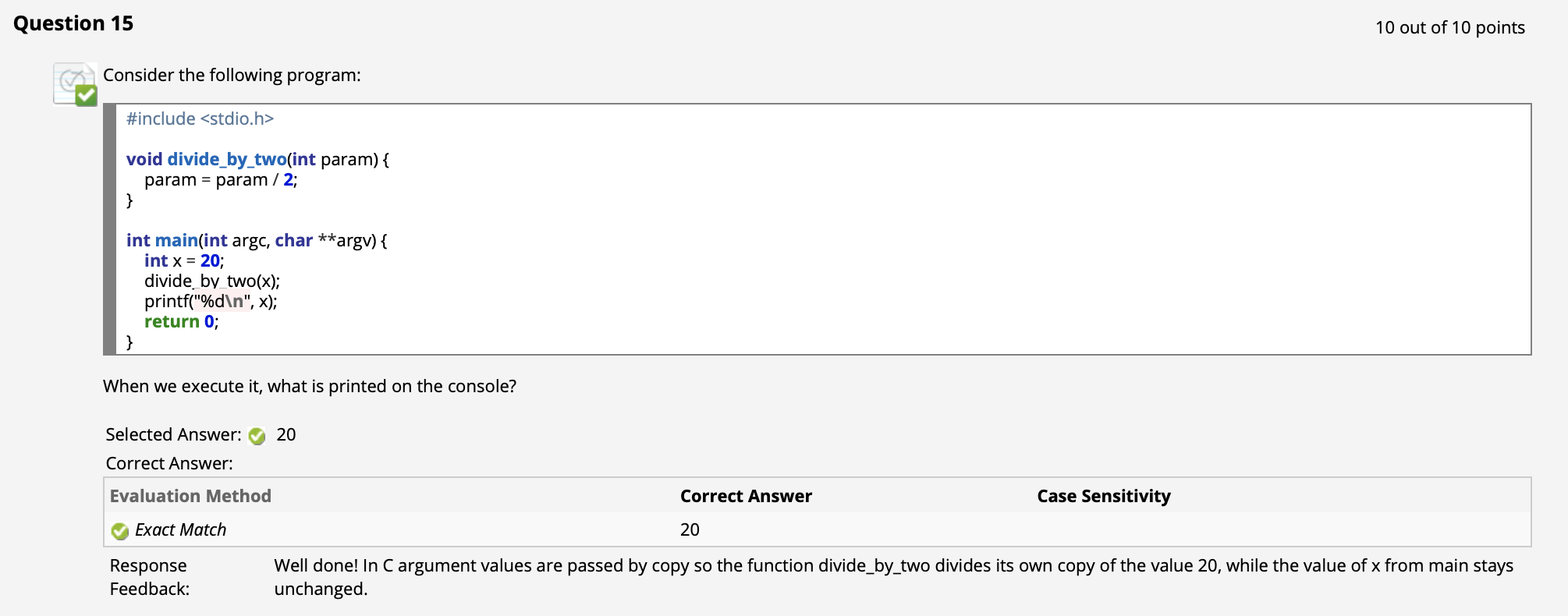
($\uparrow$ 回忆 C/C++ 函数传参方式)

($\uparrow$ 回忆 C/C++ 变量存储方式: 全局变量总在static, 函数内啥东西都在stack里, 动态分配空间放heap)
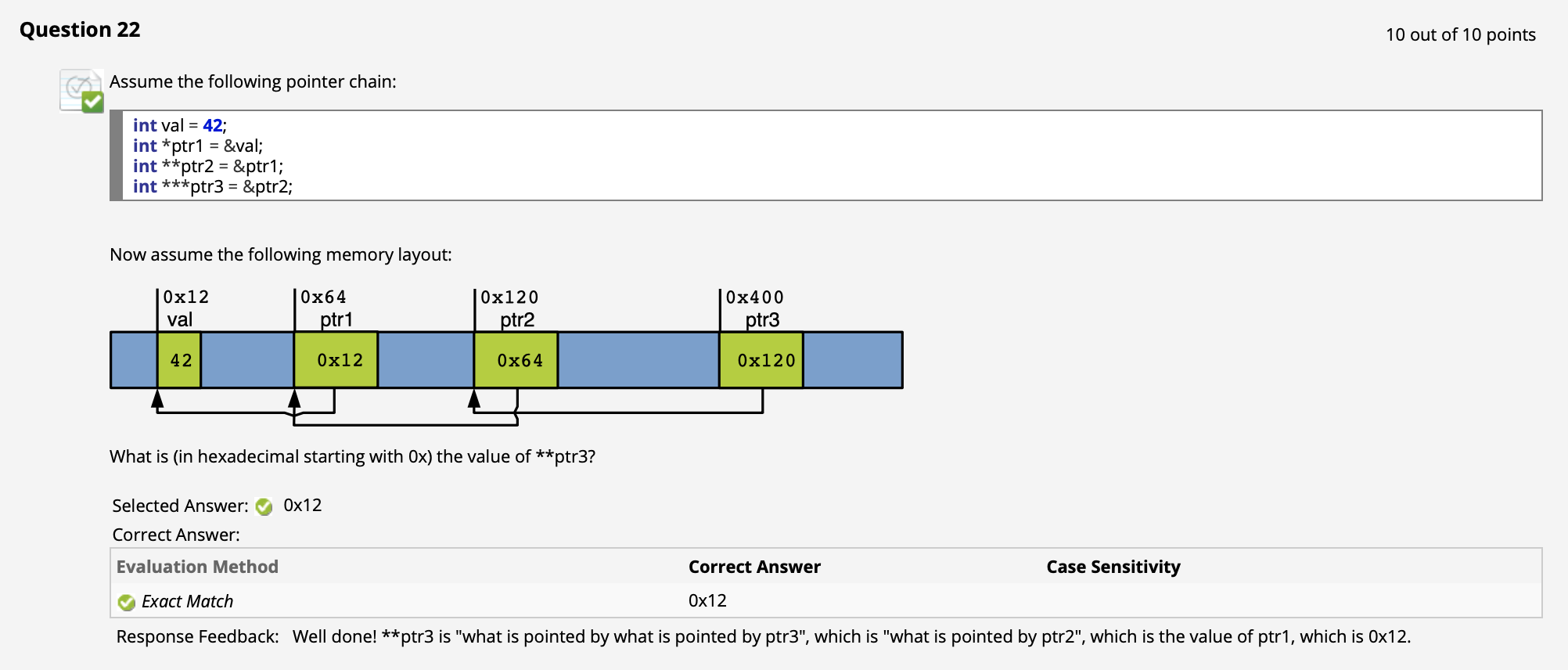
($\uparrow$ 我 -> 我引用我自己, *我 -> 对我的间接引用, a.k.a. 引用我引用的东西, **我 -> 引用我引用的东西所引用的东西, …)
4. C++简介
C++ 基于 C 发展而来, 可视为 C 的超集, 在支持 C 的全部特性基础上具有大量新功能和特征, 其中最重要的就是引入了 面向对象程序设计 (OOP) 的概念.
C++ 实现了面向对象程序设计理念中 封装 (Encapsulation), 继承 (Inheritance) 和 多态 (Polymorphism) 的概念.
封装, 类和对象
封装思想
封装 将数据和操纵数据的代码逻辑整合在 类 和 对象 中.
面向对象程序设计思想中, 对象 封装了被操纵的数据和操纵数据的方法, 记和特定对象相关联的数据为 成员变量, 不同对象的成员变量值也相应不同; 而对象中操纵成员变量的方法称为 成员方法. 而具有相同性质的对象被进一步抽象为 类, 成员方法在类中需要声明, 因而我们可以基于特定的类 实例化 属于这个类的任意多个对象.

进一步考虑下面的例子. 在使用类和对象将数据与操纵数据的方法封装后, 我们常常会发现允许直接从外部访问某个类的变量是不安全的, 因此我们需要将类变量进一步封装起来, 并在类中定义安全完备的调用和修改方法 (getter/setter).

对数据进行封装的核心方法是:
- 将尽可能多的数据的可读性设为
private, 让它无法被外界直接访问. - 只对有必要被外界访问的类数据设计
setter或/和getter.

Encapsulation is a concept from OOP where some data and the code that is supposed to manipulate this data are binded together into classes that can be instantiated into objects.
实例化: 构造器和析构器
回顾在 Java 中, 当我们实例化类时, 总是使用 构造器 (Constructor) 在生成对应类的某个实例 (对象) 的同时初始化/设定这个对象的内部变量. 在 C++ 中, 出于内存安全的考虑 在确定某个对象不再有用 (如结束生命周期) 时调用 对应类的析构器 将这个对象无害化处理, 释放内存空间.
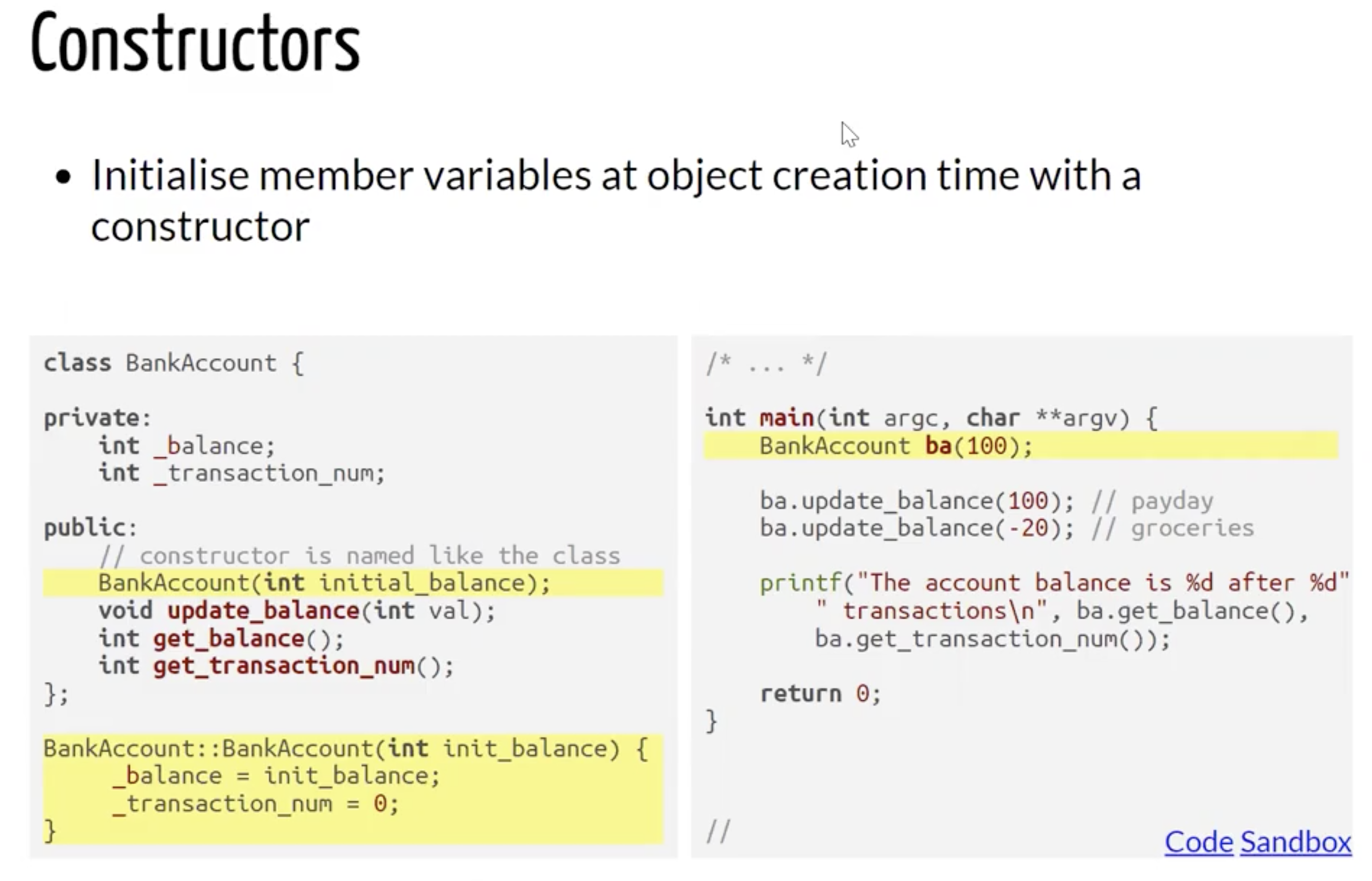
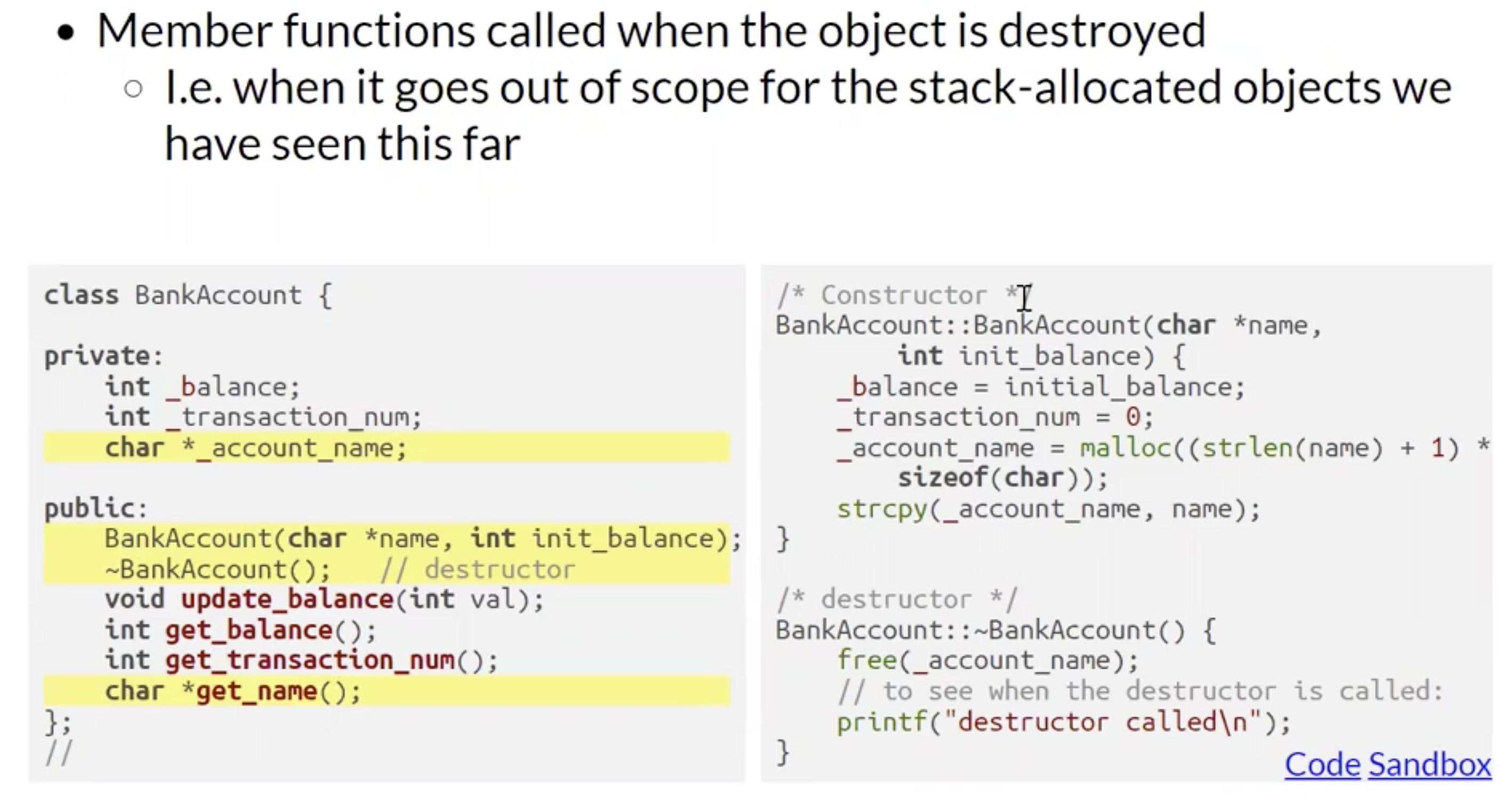
需要注意, 析构器是 自动调用 的, 由于某个对象中变量除非特殊指定否则都会被存储在堆以外的专属内存空间中, 因此这个对象被析构时这些变量占据的内存都会被自动释放, 我们所需要做的就是在析构器中使用 free() 完成对那些在对象中 手动分配的堆内存空间 的释放.
如:

在上面的例子中, 对象 ba 的生命周期只在函数内, 因此在函数执行完毕返回上一级主函数体 main 前会最后调用该对象 ba 对应类 BankAccount 的析构器 ~BankAccount().
同时因为这个类中我们在构造器中手动使用 malloc() 为类变量 _account_name 在堆中分配了内存空间, 因此这些被分配的内存空间需要在析构器中手动释放, 因此在析构器中可以看到对应逻辑 free(_account_name);.
类/对象变量/方法的域内引用
和 Python 中的 self 类似, 我们可以在 C++ 的类中使用 this 指代本类, 进而直接通过形如 this -> class_variable, this -> class_method(some_variable) 的方式应用类中的变量和方法.

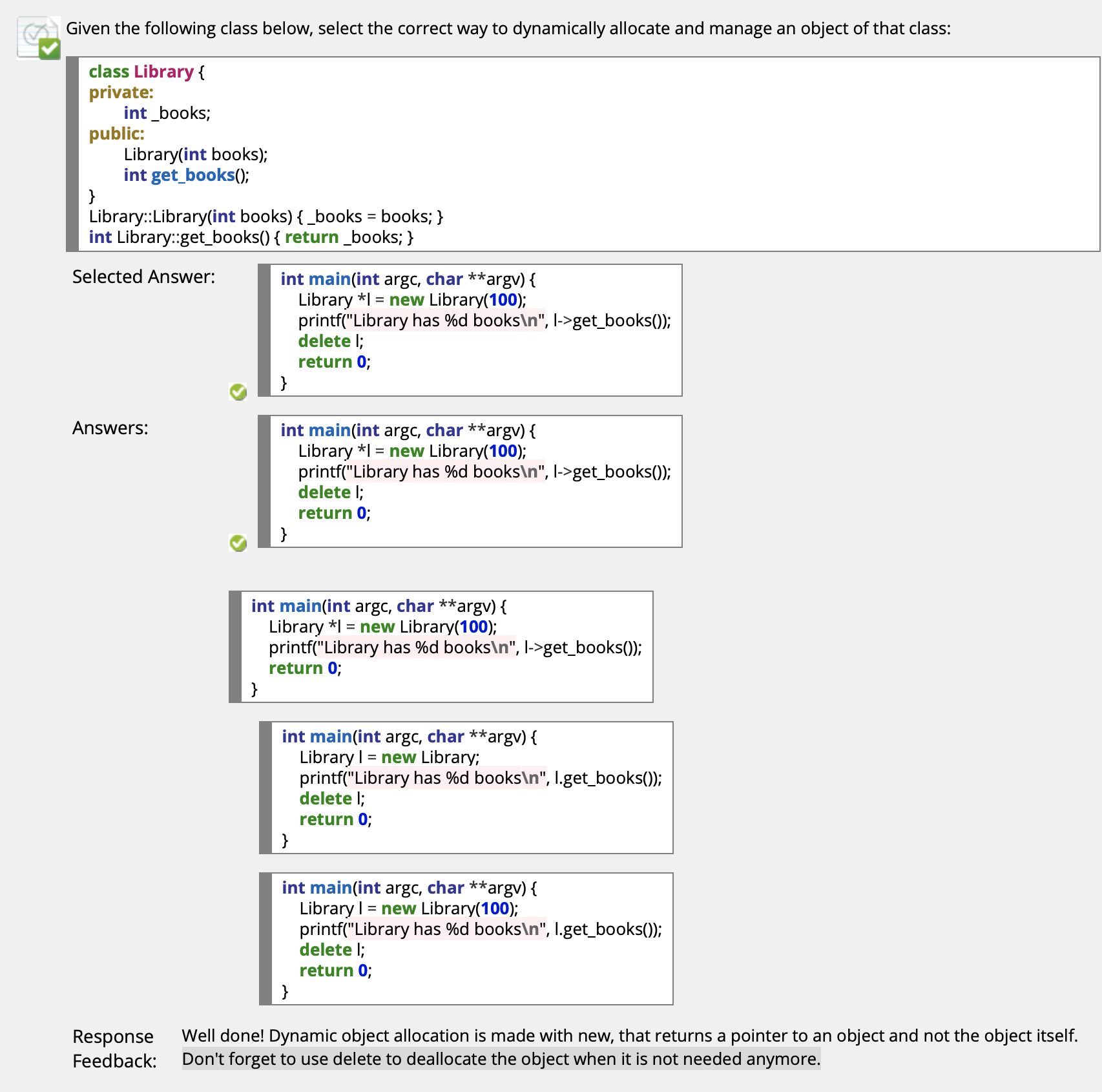
动态对象分配
和 C 一样, C++ 同样支持通过 malloc 和 free 的, 面向 变量 的动态内存分配.
进一步地, C++ 还支持面向 对象 的动态内存分配, 这通过 new 和 delete 实现:

注意动态对象分配的底层实现还是基于动态变量内存分配的.

在上面的例子中, 我们使用 new 用动态对象分配的方式为数个 BankAccount 实例 在堆中分配了内存, 栈中保存的只是 指向这些对应对象的指针. 在使用完这些对象后, 我们使用了 delete 将堆中属于这些实例的内存空间释放.
动态数组
C++ 中引入了类名为 vector 的动态数组, 其大小不再是固定的, 且其数据的存储位置在 堆 上, 内存分配由程序语言负责.
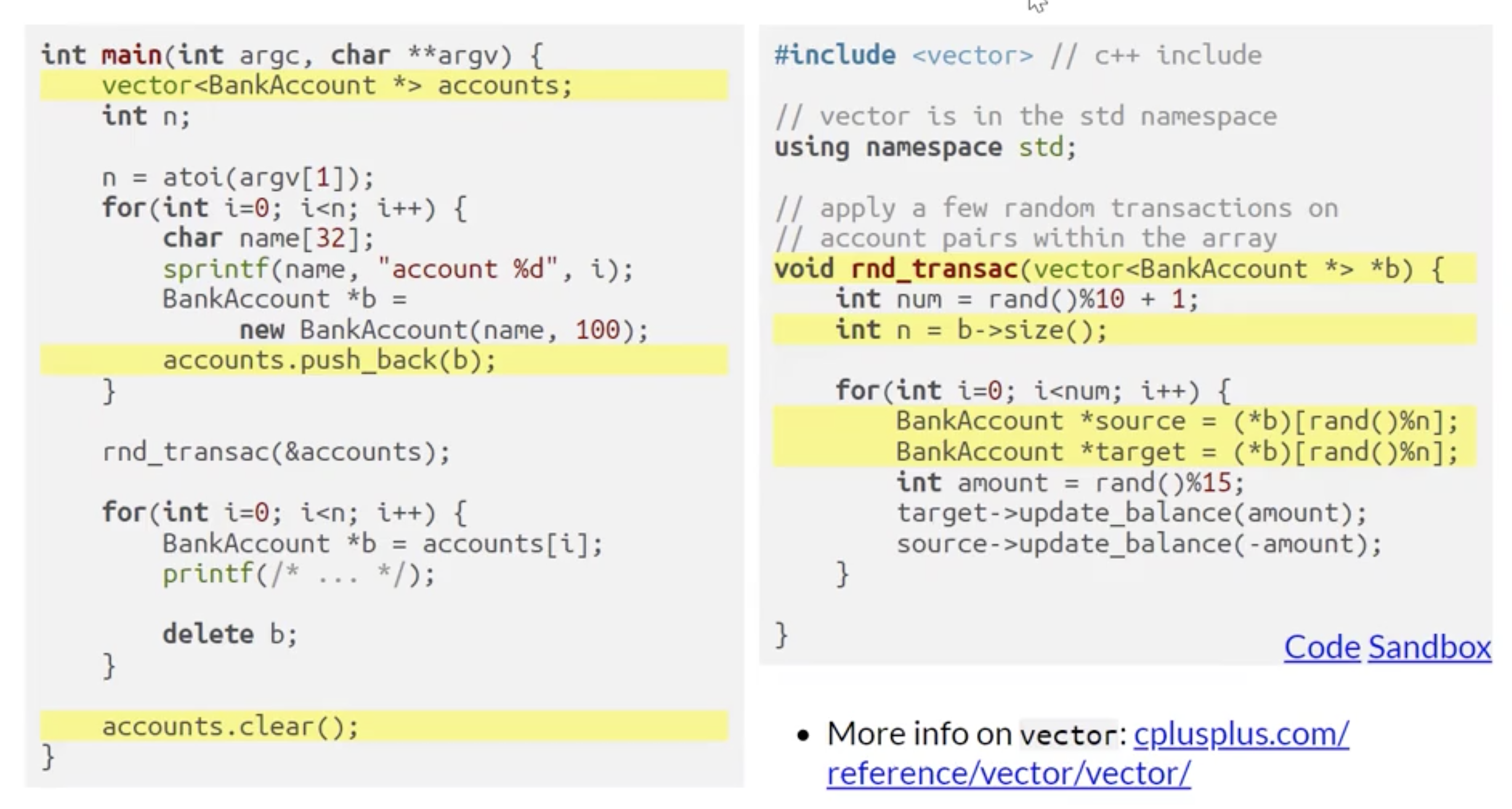
从上面的例子中可见我们可以无需在实例化动态数组时显式声明它的大小.
继承
继承 的目标是实现功能和结构类似的类之间的 代码复用. 如下面的例子所示, 某个基类中的代码可以被它的 多个派生类 所复用:
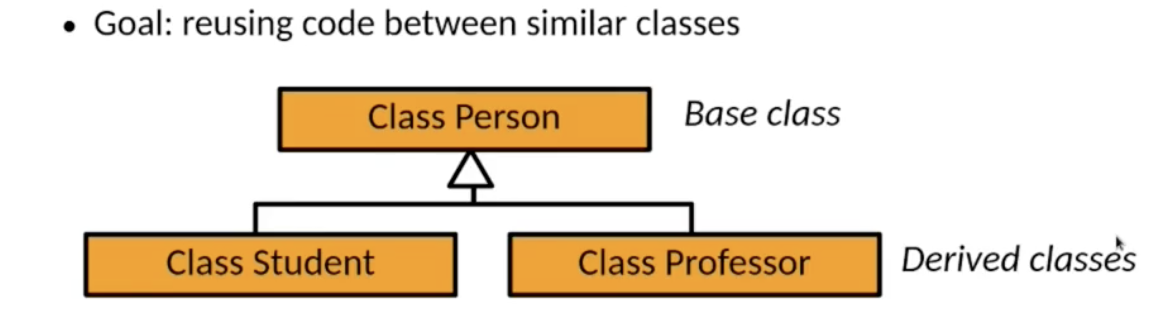
我们称这些派生类 继承 了基类:

注意: 派生类自动包含基类中具有的所有变量, 以及基类中声明的所有方法, 但是派生类也可以使用和基类不同的实现逻辑 覆盖基类的实现方式, 重新实现同名方法, 同时也可以声明基类中不具备的新方法或新变量.


同时需要注意, 只有在基类中可见性设为 public 的方法和字段 (成员) 才在派生类中可见:

In OOP, when a class C inheritates from a class D, C gets access to a subset of D’s member variables and functions. A relationship of type “is a” exists between C and D, i.e. C “is a” more specialized type of D.
多态
多态 允许程序在实现代码复用的同时具备一定的自由度, 允许某个同名函数在不同情况下具备 多种逻辑不同的实现方式.

Polymorphism is a concept in OOP in which a function with a given name can take several implementations.
函数重载 (Function Overloading)
首先解释 函数重载: 函数重载是指在同一作用域内, 可以有一组具有相同函数名, 不同参数列表的函数, 这组函数被称为重载函数.

注意函数重载不适用于 C.
可见上图中函数 print 被三次重载.
同时函数重载还可用在 类构造器上:

由于特定函数是否重载, 在什么地方重载为哪个实现完全由函数的输入数据类型决定, 因此函数重载 (Function Overload) 是 Compile-time Polymorphism.
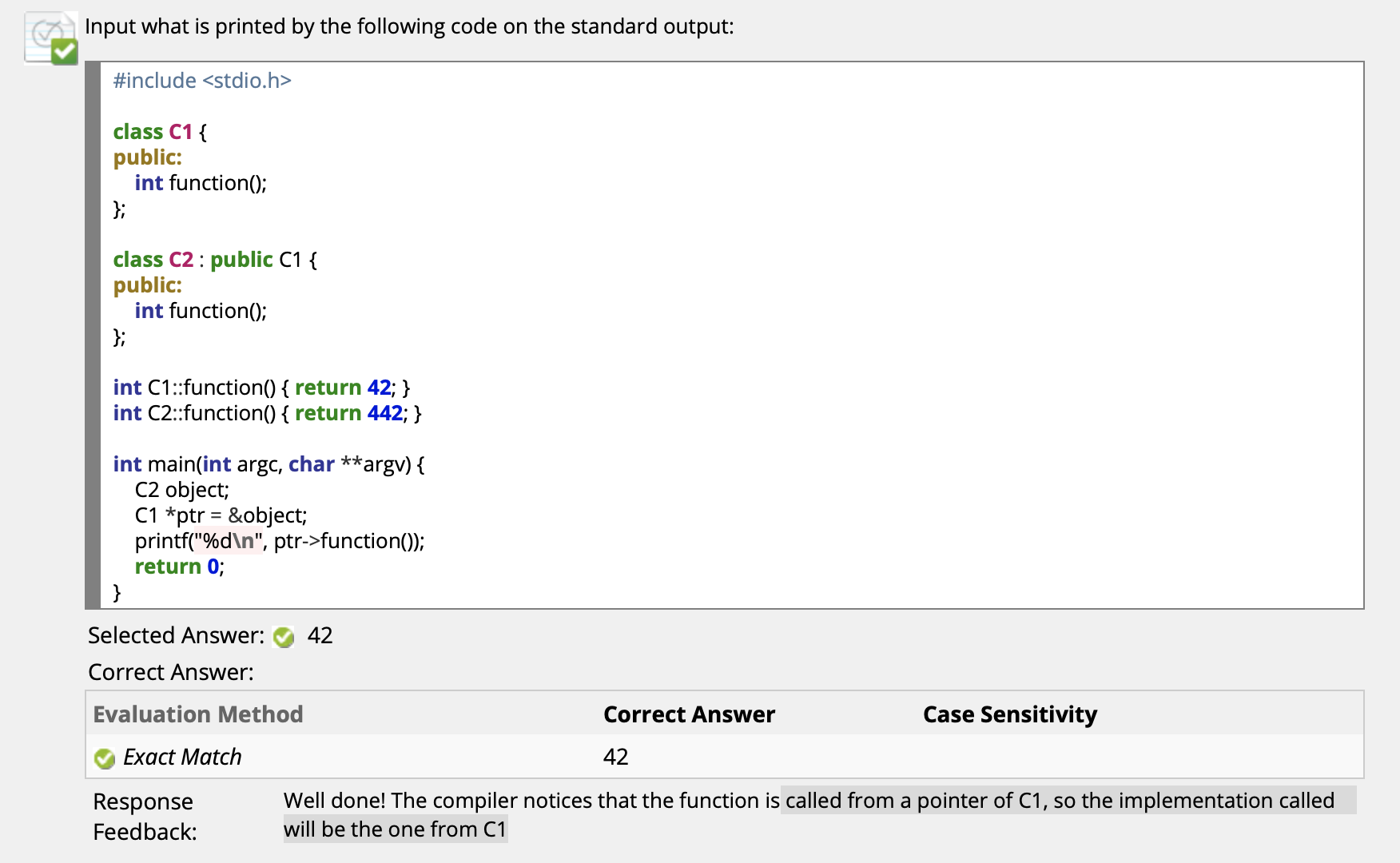
函数重写 (Function Overriding)
其次解释 函数覆盖 (函数重写): 函数覆盖是指子类重新定义父类中有相同名称和参数的 (虚) 函数, 主要在继承关系中出现.


由于函数重写是对函数逻辑的重新实现, 因此只有在函数被调用时才会发生, Function Override 是 Runtime Polymorphism.
抽象类 (Abstract Class)
称包含 至少一个纯粹的虚函数定义的类 为 抽象类.

抽象类由于包含没有实现的虚函数因此 无法被实例化, 而且由抽象类派生出来的全部子类 都需要实现抽象类中的虚函数.
相关题目解析



5. 编译
我们将在本节中讨论和 C/C++ 语言源代码编译的相关问题和技术.
预处理
我们首先介绍 C/C++ 语言编译的流水线. 源码首先需要通过 (一般被编译器静默调用的) 预处理器 (Preprocessor) 转为经过预处理的源码 (即: 输入输出都是源文件), 然后传入 编译器 (Compiler) 被编译为可执行文件. 预处理过程中主要可以执行的操作都属于 文本转换 (Textual Transformation), 具体分为:
- 向源文件中插入 头文件 从而访问外部库中的方法, 结构体, 类和其他定义.
- 将名为 宏 (
Macro) 的词素扩展为更复杂的实际代码. - 有条件地允许/禁止程序某些部分的编译.
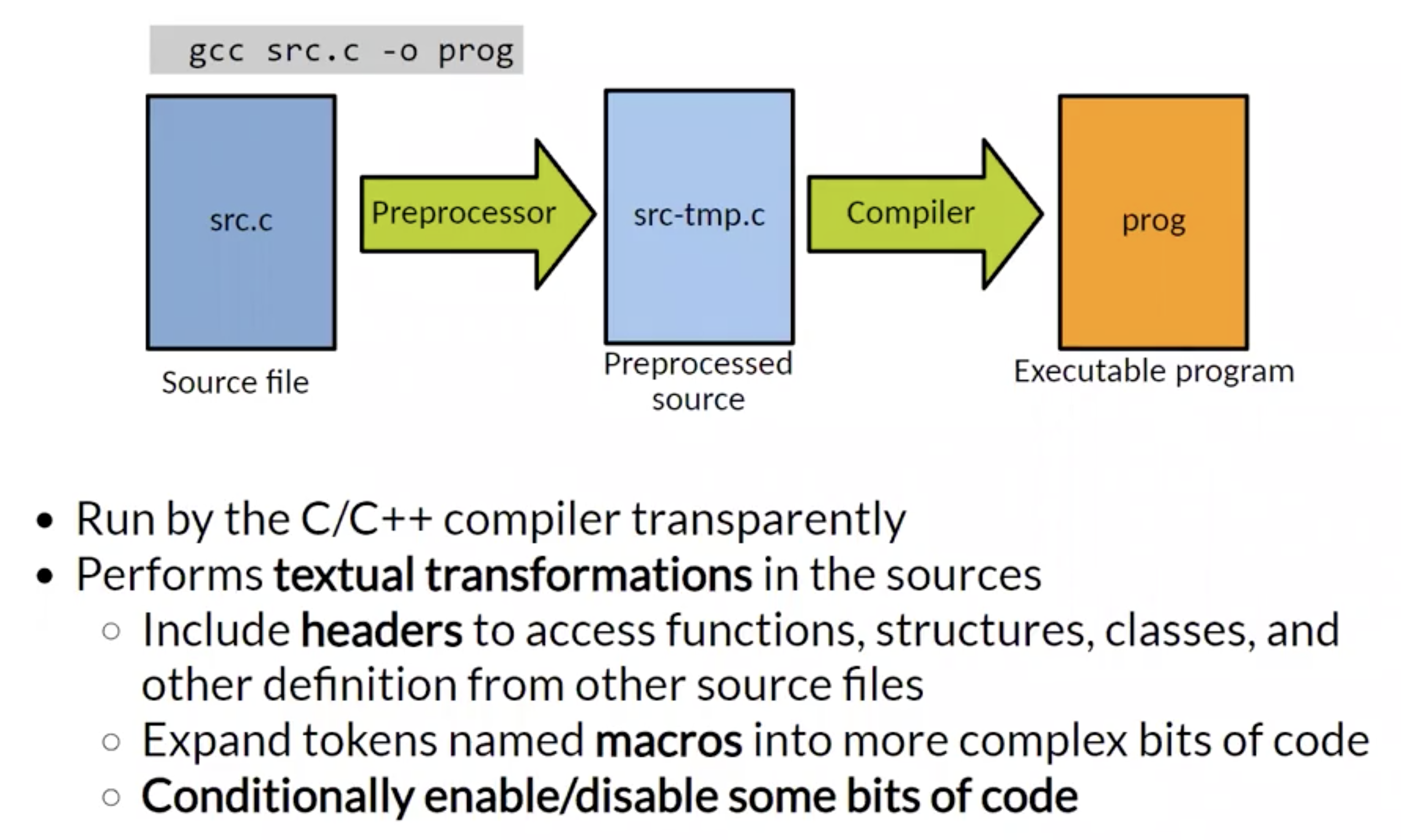
头文件 Header
头文件是以 .h 结尾的源文件, 一般包含重要的外部库或其他源文件.
头文件可以嵌套包含别的头文件, 但文件中应只包括 对方法, 类, 结构体等的 声明或骨架 而 不能包含具体的实现.
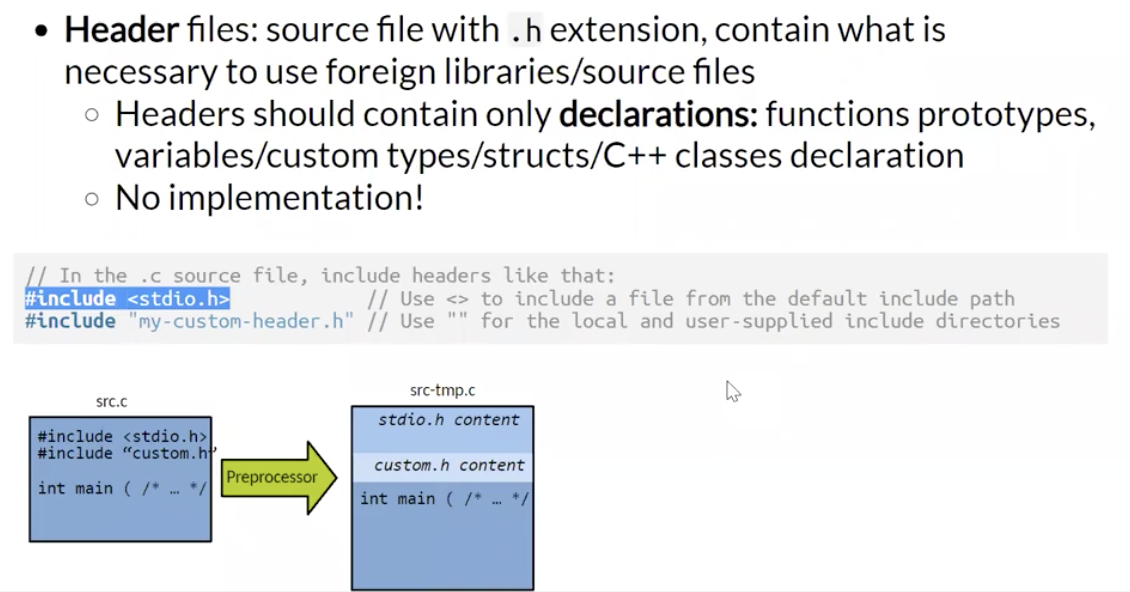
注意如果头文件包含在了源文件中, 则在编译时 不应作为参数传给编译器!
宏扩展 Macro Expansion
宏扩展允许我们进行自定义文本替换, 其最为常见的一个应用场景是声明一些在编译过程中使用的常量.

如上图中, 表示数组大小的常量被定义为宏.
总而言之, 利用宏可以让我们 尽可能少地在程序中声明 “硬编码” 的数值常量, 从而增加程序的可读性. 宏还有更高级的应用. 在此我们不再对其详细介绍, 但需要注意一点: 声明宏变量时如果涉及运算, 一定要注意运算符顺序, 最好使用括号确保运算顺序无误.
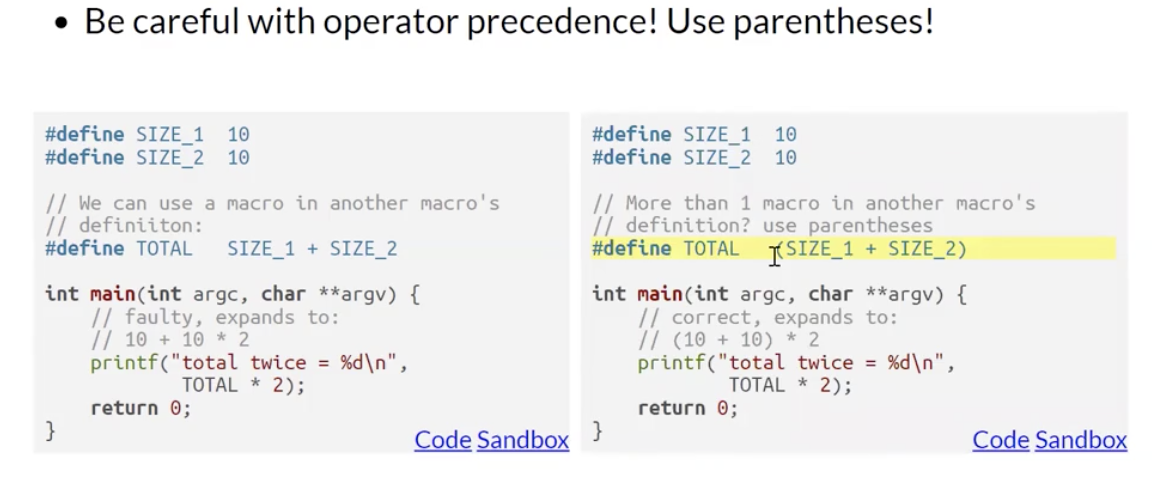
如果去掉括号的话, TOTAL 的值就会变成 10+10, 在执行运算的时候就不会是 20 * 2, 而是会变成 10 + 10*2! 宏不会执行运算, 它所做的可以近似的认为是文本替换!
有条件编译 Conditional Compilation
我们还可以结合代码头定义的宏变量和穿插在程序特定位置中的 #ifdef, #endif 控制特定代码片段能否被编译.
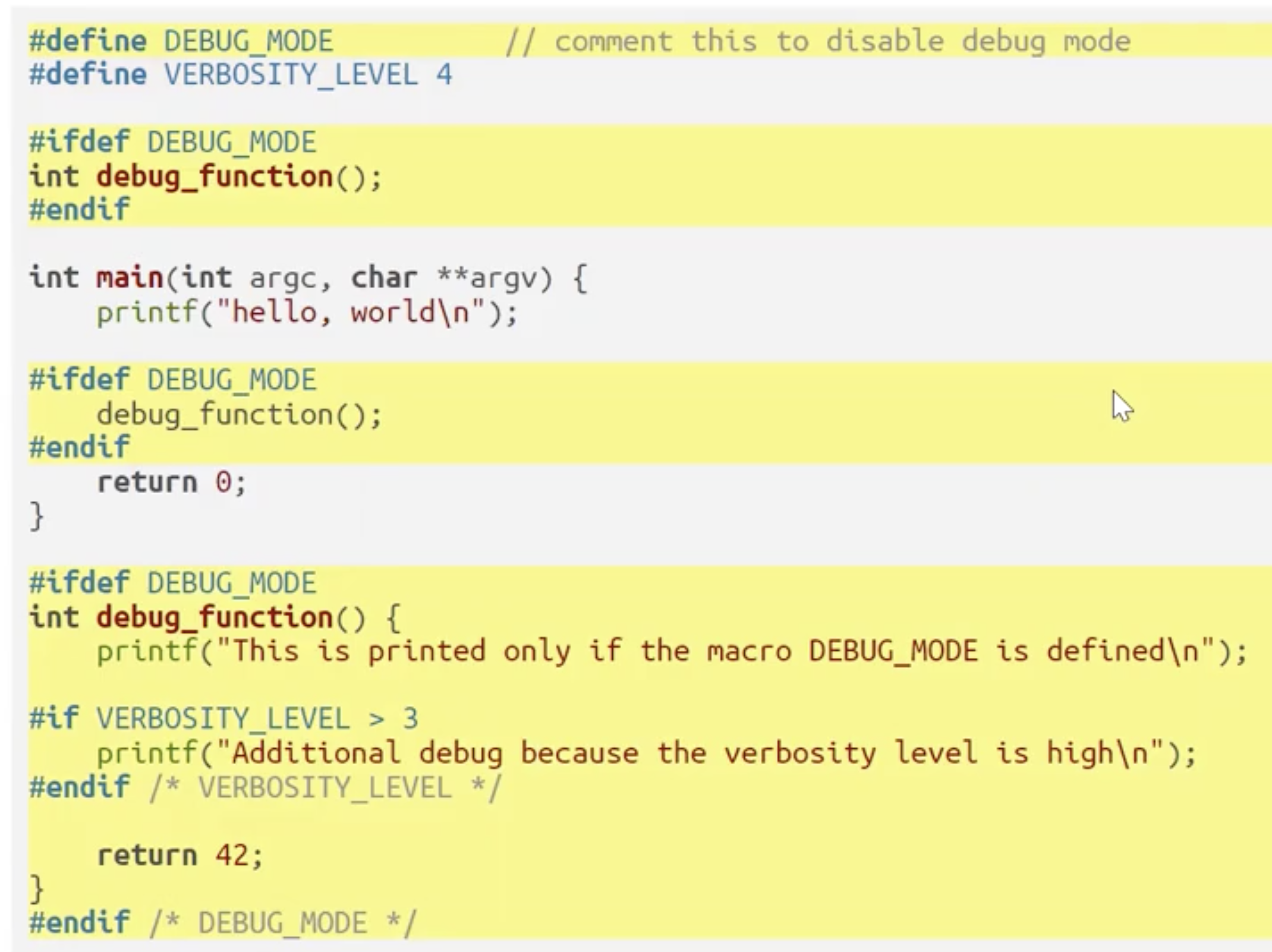
可见, 在上面的例子中, 通过控制是否定义宏变量 DEBUG_MODE, 我们就可以控制高亮部分程序编译与否.
模块化编译
复杂程序往往包含同样复杂的外部文件/库依赖和调用关系. 通过将编译 模块化, 就可以选择性地编译特定的组件, 从而避免 “牵一发而动全身, 被迫因为某个小组件的变动而重新编译整个程序库” 这一现象的发生.

在上面的学习中, 我们已经知道典型的 C/C++ 程序编译主要分为两步: 预处理和实际编译.
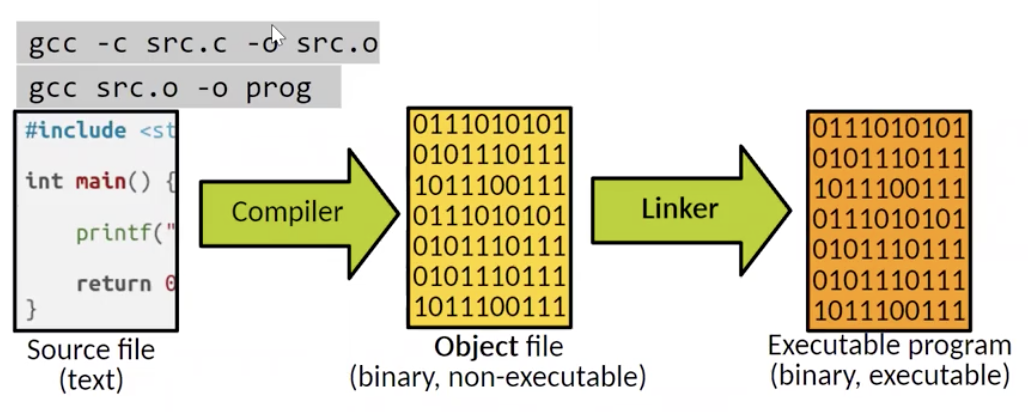
为了实现模块化编译, 编译这一步又被进一步地拆分为 编译 和 链接 两个部分:
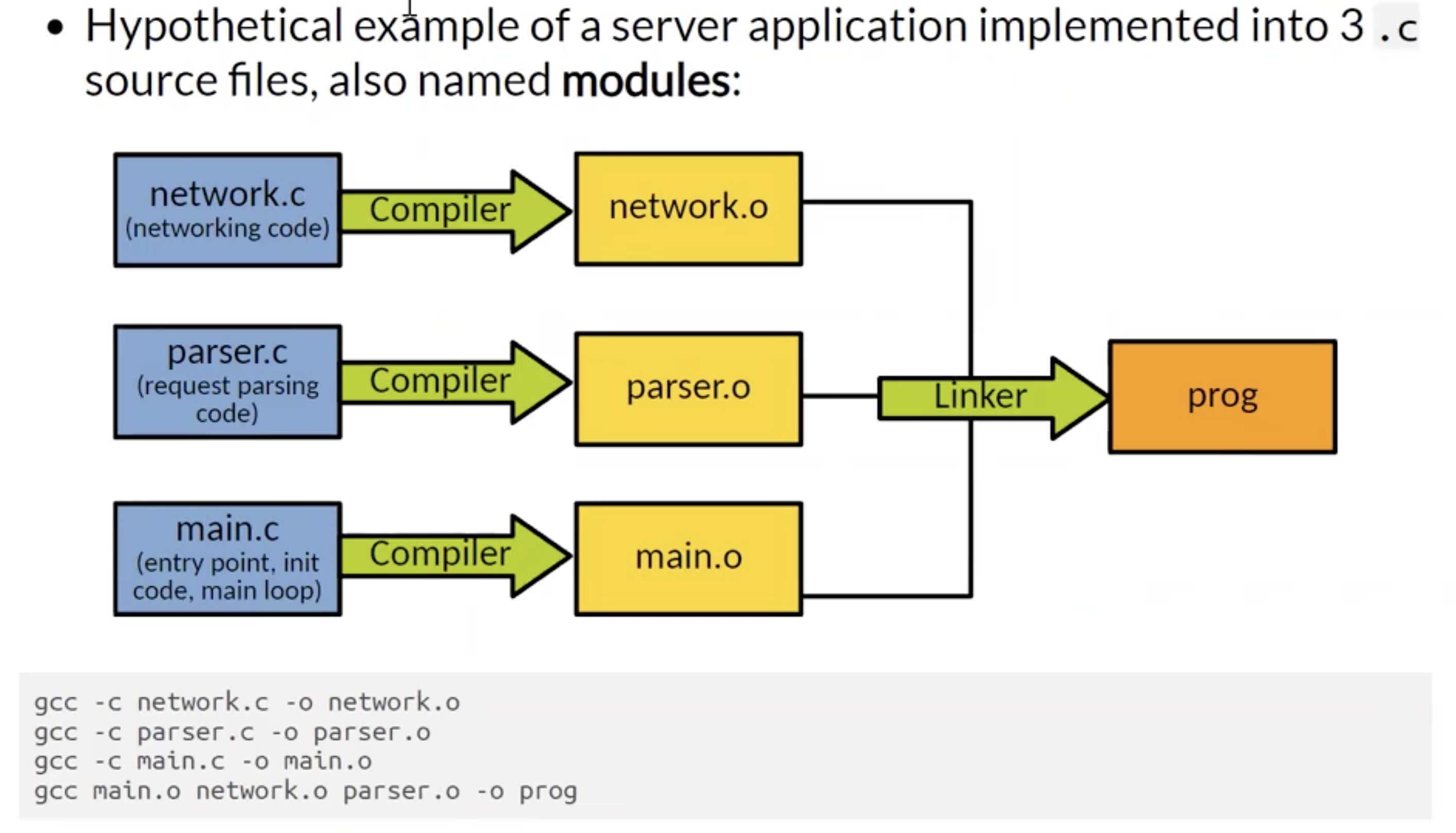
注意如果模块之间没有依赖关系的话, 在进行模块化编译时编译各个模块的顺序无需明确规定.
我们考虑下面所示的例子:
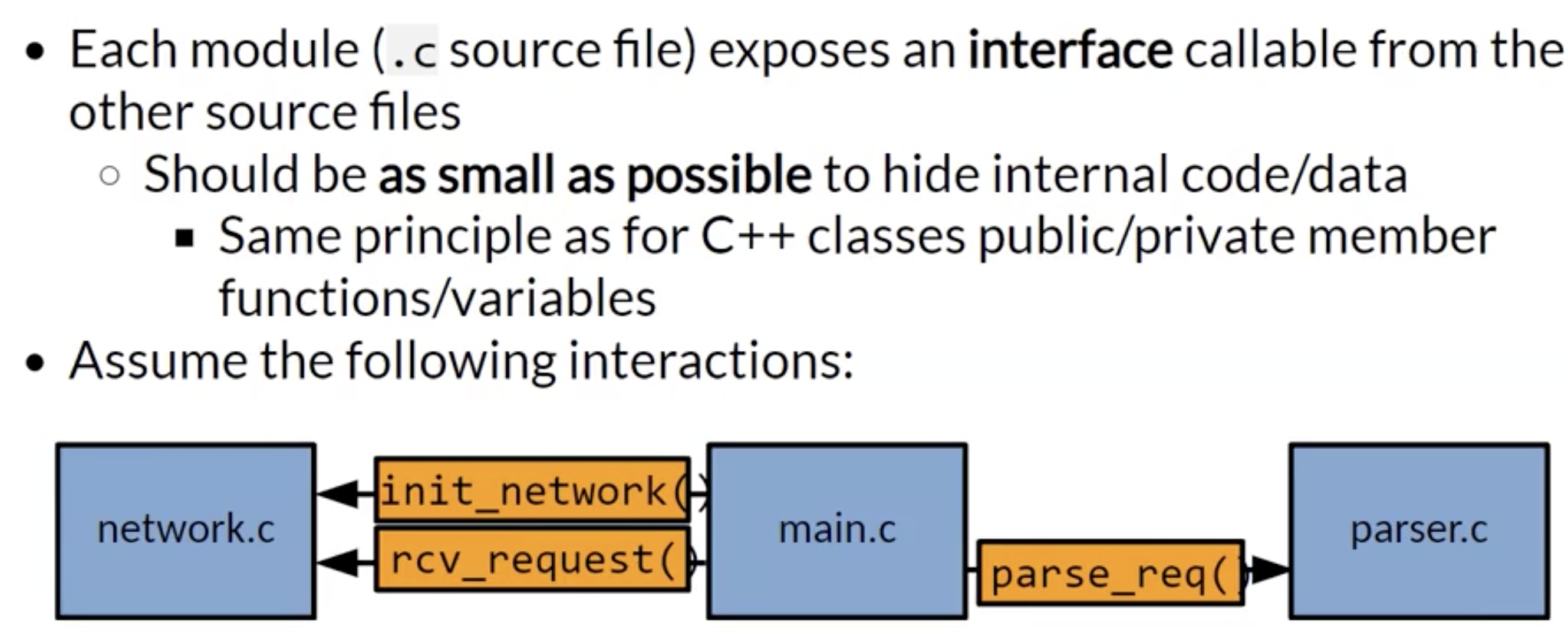
注意在将程序拆分为模块时, 需要确保被拆分的每个模块都暴露了合适的接口, 并且完整地做到了对内部数据和逻辑的隐藏.
模块的接口需要被定义在该模块对应的模块头文件中, 头文件里包含的接口声明的具体实现在模块本体中; 模块本体中自然也要包含模块对应的头文件.
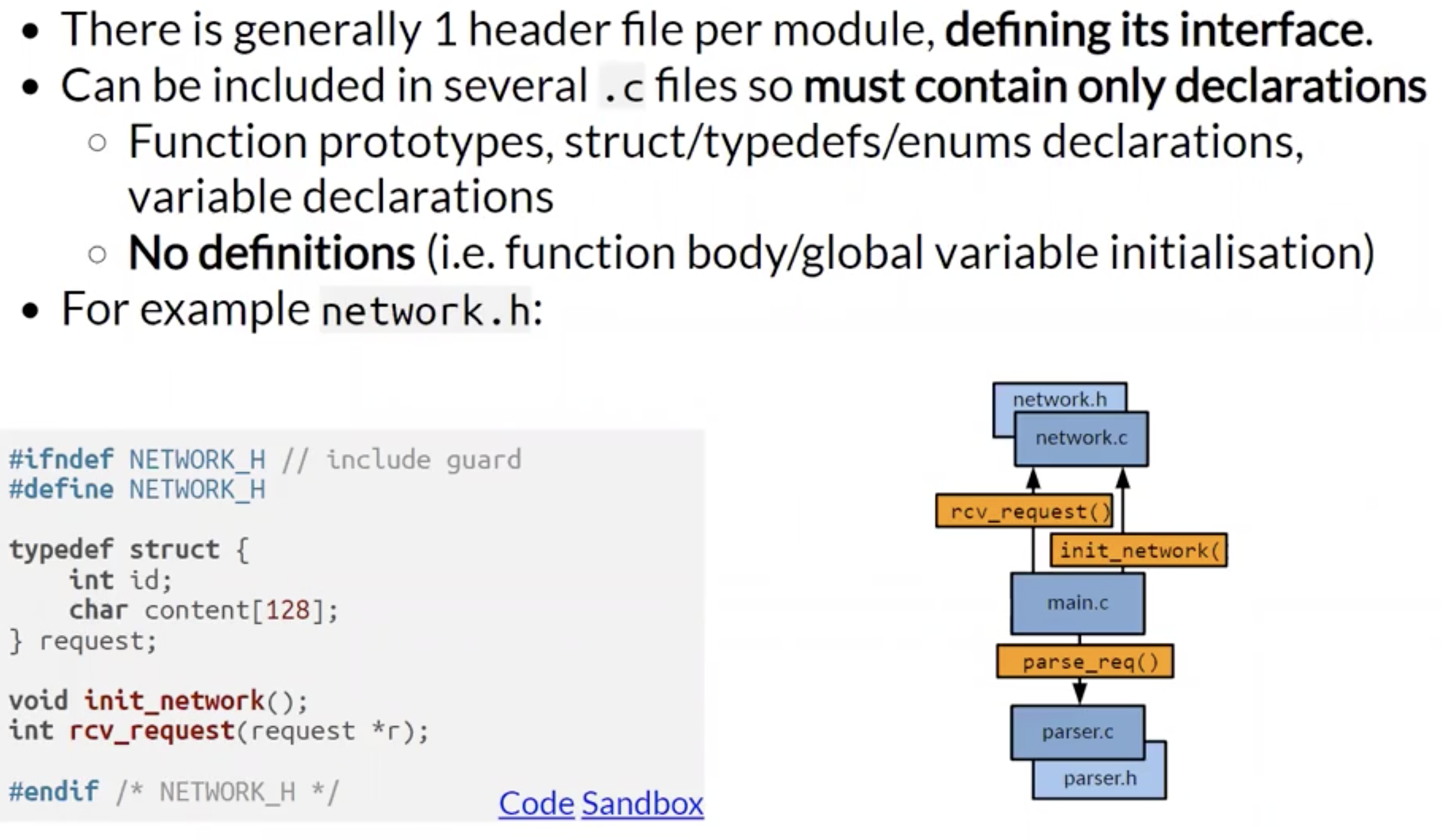
上面例子中两个模块的头文件和本体的定义如下:
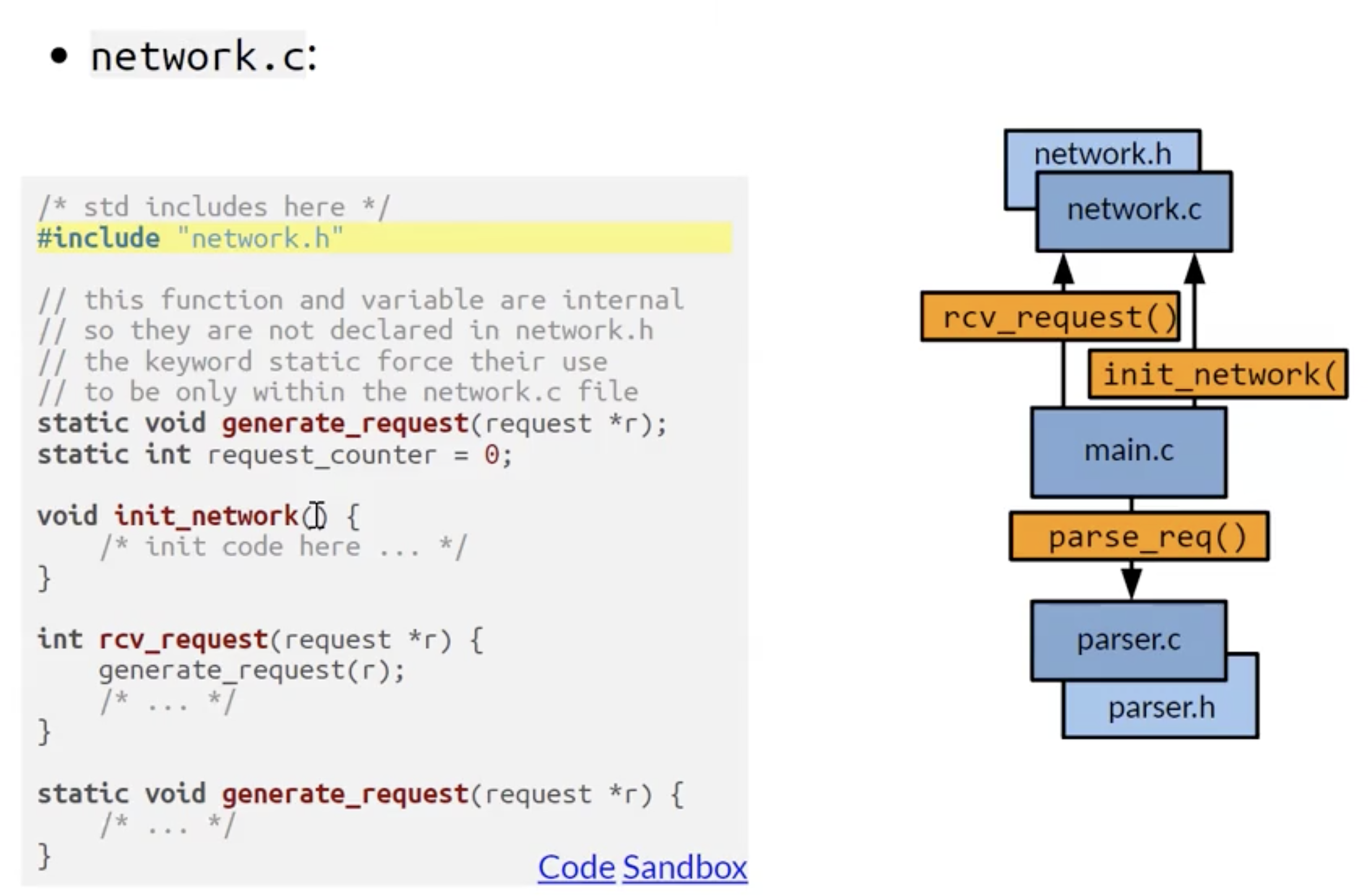
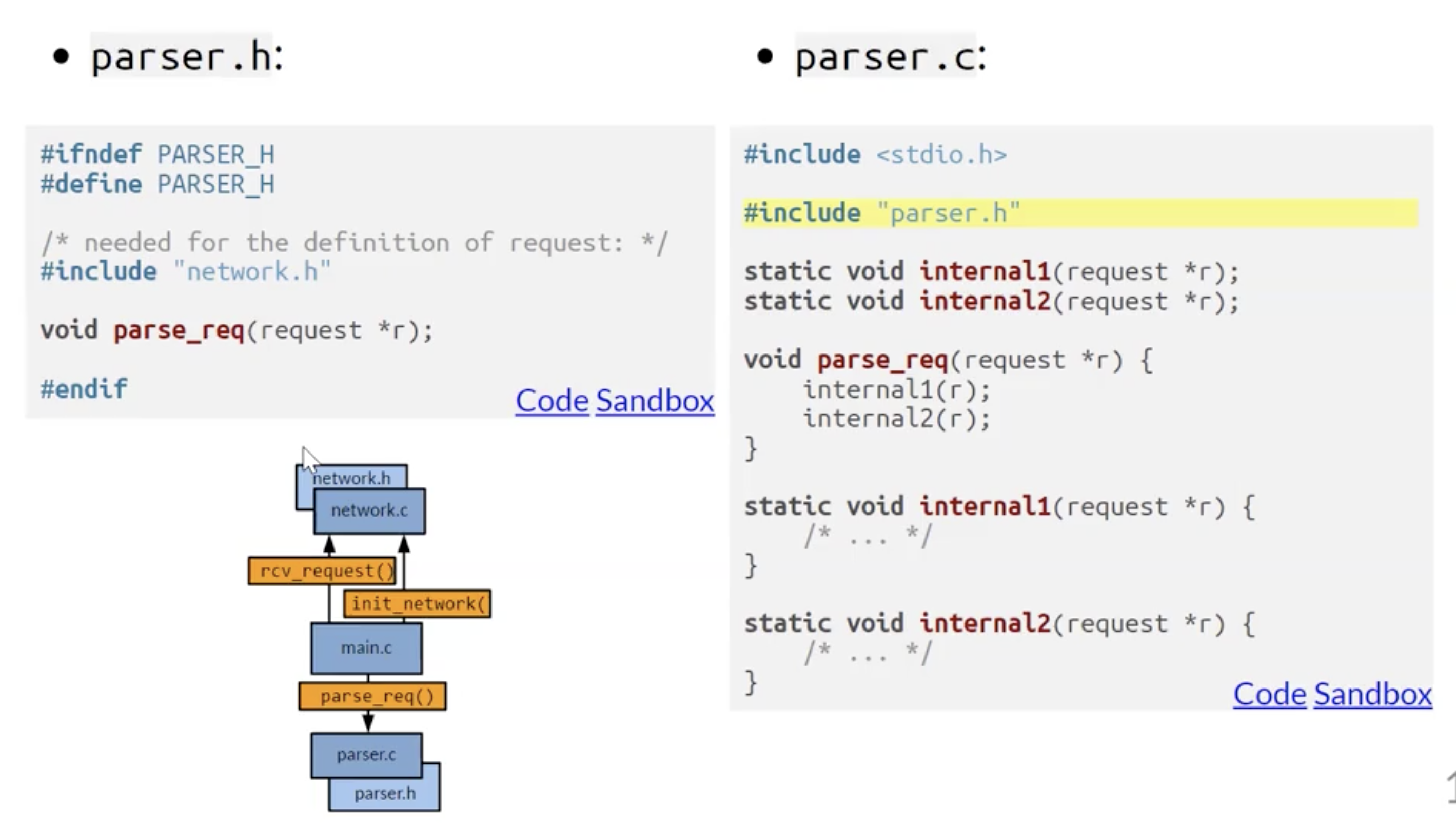
C++ 源文件管理
而在 C++ 中我们同样要处理源文件管理的问题.
一般地, 每个类或一组相关类对应一个头文件 .h, 只包含它们的 声明 (declarations).
同时, 每个类或一组相关的类对应一个源码文件 .cpp, 包含 成员方法的实现.

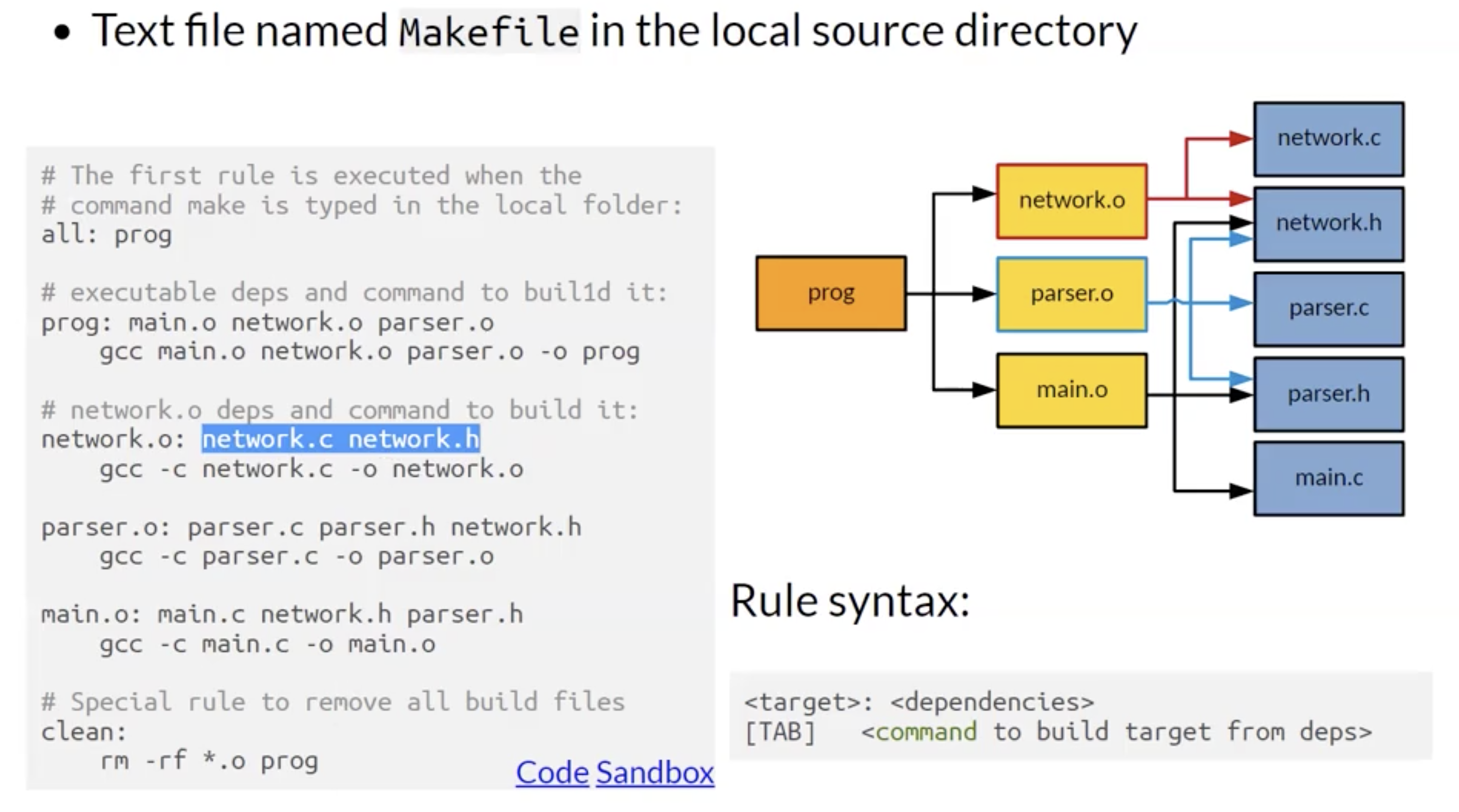
自动编译
自动编译常用于复杂程序编译行为的简化和管理. 以上面的提到过的, 由 network, main 和 parser 组成的程序库的 增量更新 为例: 我们可以通过设定自动化规则确保由多个模块组成的程序在某个组成模块被更新时只重新编译新模块的代码, 而其他没有更新的模块则 不被重新编译, 直接参加链接, 节约编译时间, 节省资源.
我们可以使用 makefile 自定义编译规则. 首先考虑该程序库的组成结构和依赖关系:

随后就可以通过使用下面的语法在 makefile 声明每个组件的编译依赖关系的方式实现自动化编译:
C的类型转换
在本节中, 我们将讨论 C/C++ 中的 类型转换 和 强制类型转换.
隐式类型转换
首先讨论 (最常见于数值运算中的) 隐式类型转换 (Impcilit Type Conversion) 问题. 举例而言, 在下面的例子中, 我们将三种类型不同的数值型数据: char, int, long long 相加. 显然, 在这一过程中, 由于在三个不同类型中可表示整数位数最多的 long long 可以表示其他两种数据类型所表示的数据, 因此在执行计算时执行了 隐式类型转换: 位数较小的 char 和 int 被首先转换为 long long, 然后和第三个变量执行加法最终得到类型为 long long 的计算结果.

这一过程也被称为 Integer Promotion, 其基本思想是: 在 确保不发生任何数据丢失的前提下 确保计算中涉及的所有变量类型 保持一致. (回顾整形数据的基本表示法, 含符号整数的补码表示法) 显然, 自然地存在如下图所示的 Integer Promotion 位次图:
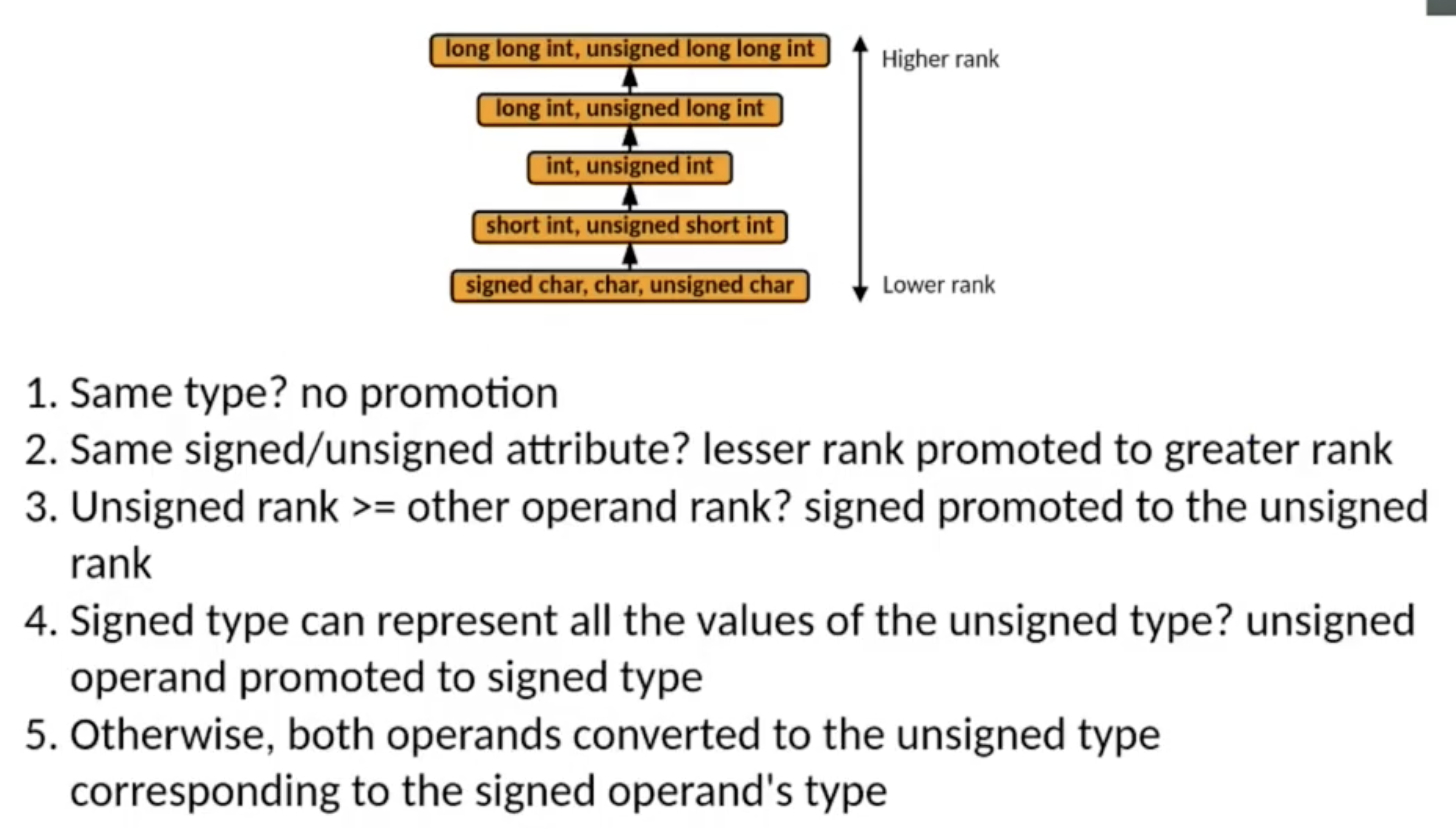
具体地, 隐式类型转换的原则如下:
- 若算式中变量 类型一致, 则不执行任何类型转换.
- 若算式中变量 类型不一致:
- 若在是否有符号性质上保持一致, 则 低阶类型的变量类型被转换为高阶类型.
- 若算式中存在比 其他的有符号数据类型都高阶的 无符号数据类型, 则有符号数据类型被转换为那个无符号数据类型.
- 若存在某个有符号数据类型 可以表示所有无符号数据类型表示的数据, 则这些无符号数据类型统一被提升为这个有符号数据类型.
- 在其他情况下, 所有参与计算的变量都被转为无符号类型.
需要注意 C/C++ 在大部分情况下试图将有符号数据类型转为无符号数据类型的原因: 如果不考虑负数, 同级别的无符号数据类型所能存储的非负整数的范围是有符号数据类型的两倍.
C/C++ 中的隐式类型转换在一些特定情况下可能会出现问题:
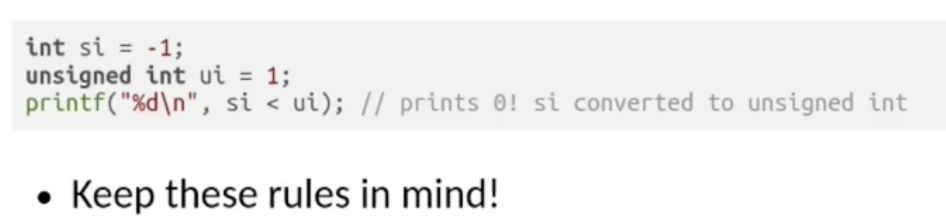
同时隐式类型转换还可以结合变量数据存储位数溢出问题共同在一些特定情况下对计算结果产生更恶劣的影响:

在上面的例子中, 基于隐式类型转换规则, 一个有符号整数和一个无符号整数的加法中, 参与运算的两个变量i 的类型会被隐式转换为无符号整数. 而由于被当成无符号整数的 i 和 ui 相加后结果溢出无符号整数的表示范围: $4$ 字节 $4*8 = 32$ 位, 因此由于 现代计算机使用小端序解析数据, 左侧视为高位, 右侧视为低位, 因此只会取实际二进制加法结果 从右往左数 的总共 $32$ 位, 溢出的位被丢弃, 因此得到的结果是错误的.
同时隐式类型转换在格式化输出中也可能存在:

整数相除的结果会被向下取整, 注意 *.5 会被取整为 * 而非 *+1. 此外, 将浮点数解释为整数会生成毫无疑义的数据.
注意在函数传参时, 不要将和函数规定不符的, 错误的参数类型传入函数, 无论传入的参数实际类型是什么, 函数都只会将该参数按照函数所定义的类型解释, 如下图所示的例子一样:

强制类型转换
除了不受控制的隐式类型转换外, C/C++ 还提供了 强制类型转换 方法, 关键字为 (type)expression.

再来看一个指针巧妙应用的例子: 我们还可以使用 通用指针 void * 向函数中传入 任何类型 的数据:

在上面的例子中, 函数 print() 三次被调用时都被传入了通用类型指针 ((void *)&c 实际上执行的是强制类型转换, 得到的是一个存储变量 c 内存地址的通用指针), 而在函数体内输出时通用指针会在被强制类型转换为对应类型的指针后, 再被间接引用得到需要输出的真实数据.
案例: 高性能计算
我们首先以 高性能计算 为例展示 C/C++ 的一个应用场景:
由于 C/C++:
- 高度贴近硬件底层, 调用系统功能时需要途径的中间层更少
- 不存在任何会延长程序执行时间的内存垃圾回收机制 (这是好事, 也是坏事…)
- 可以高效轻松地和汇编语言集成
- 为程序员提供了直接控制内存布局的方法和手段
因此它们非常适合应用于高性能计算领域:

首先回顾基本的计算机存储架构层级:

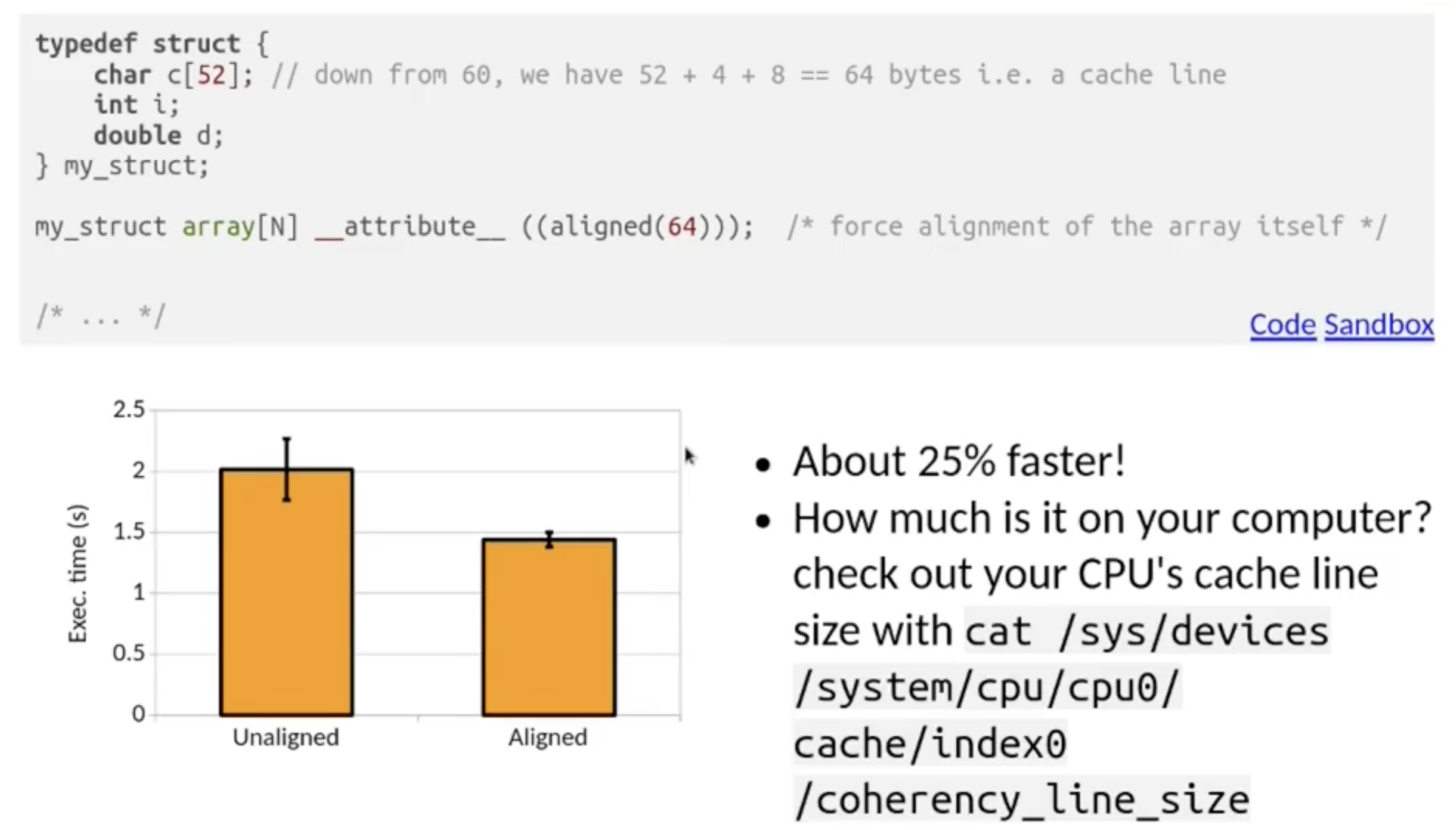
在下面的初始例子中, 使用如下图所示的结构体定义会导致每个结构体实例的大小为 72 位, 大于计算机缓存位数 64 位, 而且不是它的整数倍, 因此在调用结构体内数据时往往需要从主存中获取两个缓存位.

而在 C/C++ 中, 我们可以通过控制结构体占用内存大小为 64 的整数倍的方式通过减少调用它时所需获取的缓存位数来提升性能.
案例: LibC
我们再来讨论 C 标准库.
C/C++ 标准库提供了 stdio.h, stdlib.h 等声明和定义了各种提供基础功能的方法和类的 实现. (回顾头文件 .h 的定义)
标准库的主流实现是 libc, 但有一种更简单的实现: Musl.

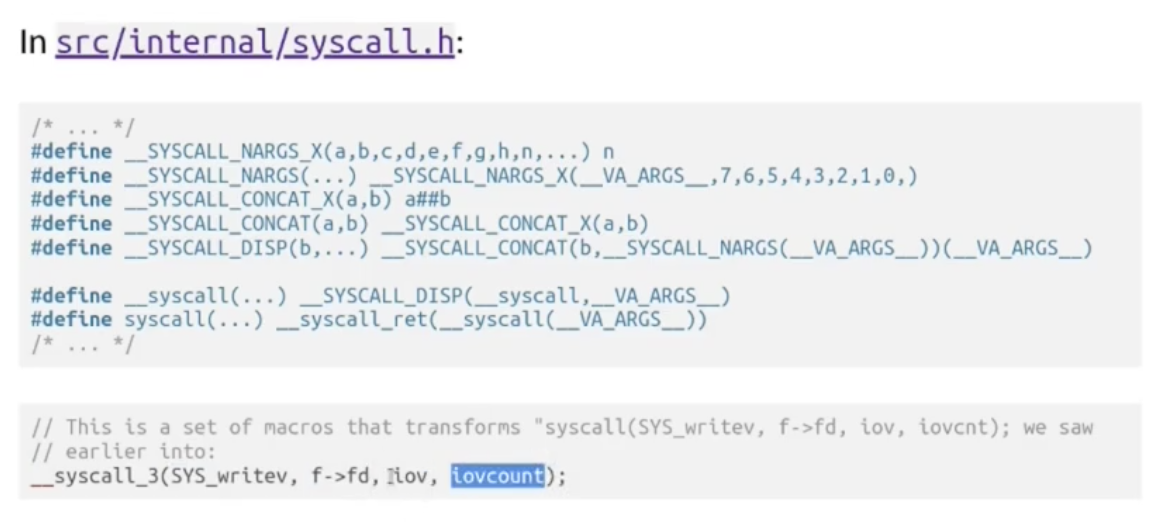
在下面的例子中我们简要观察 Musl 中对标准格式化输出函数 printf 的实现:
任何需要调用操作系统提供的服务的程序都需要通过 System Call 调用它们. 一般 System Call 是被 C/C++ 标准库所直接调用的.




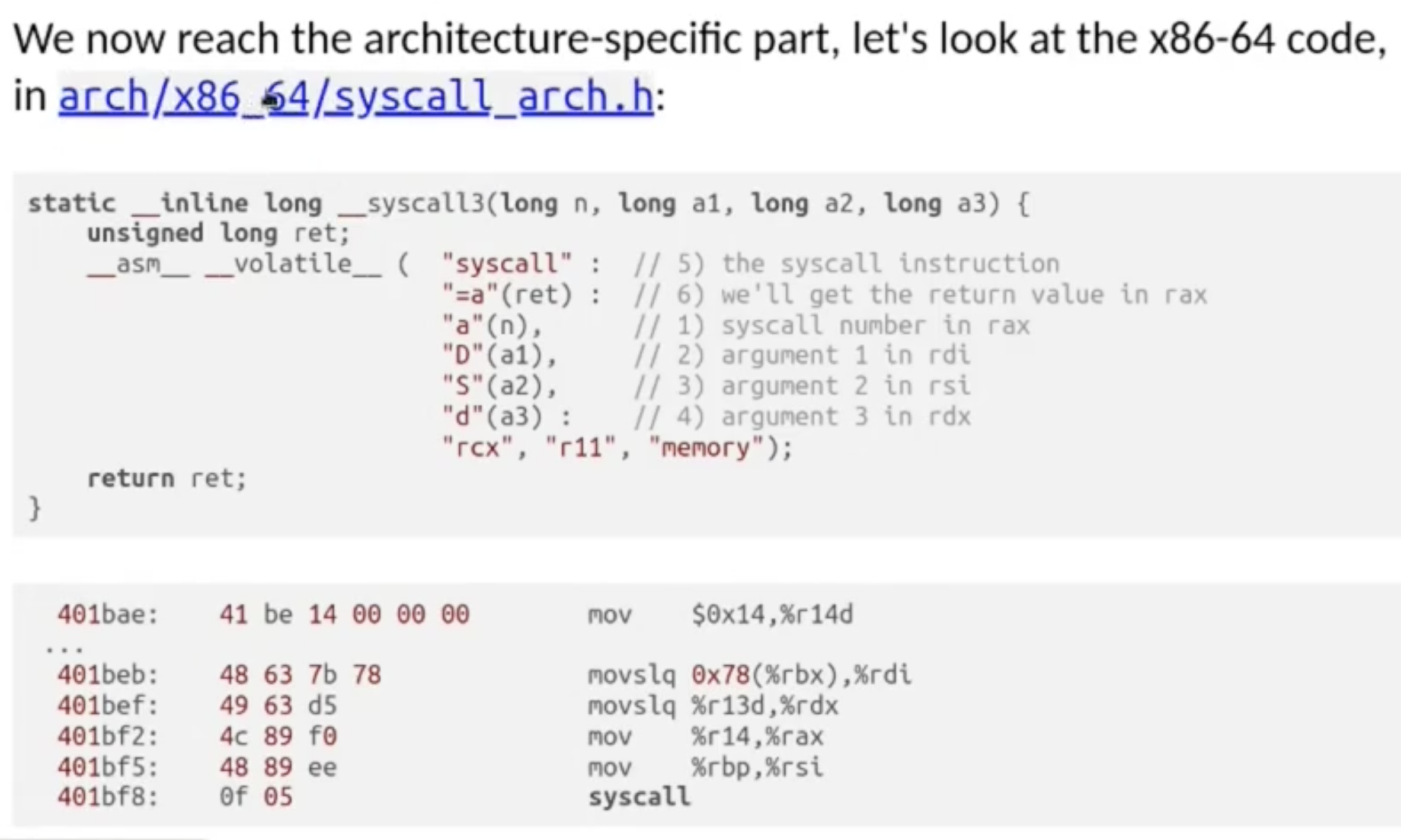
实际上也可以编写程序直接调用 System Call 执行输出:

(这个部分应该不考…)
注意:
-
During the execution of printf, Musl uses writev to write to the file descriptor corresponding to the standard output.
-
On x86-64, when we invoke a system call with 3 arguments, the registers used to pass these parameters and in order:
%rdi, %rsi, then %rdx. -
By convention, up to 6 arguments for system calls are passed in order in
%rdi, %rsi, %rdx, %r10, %r8, and %r9.
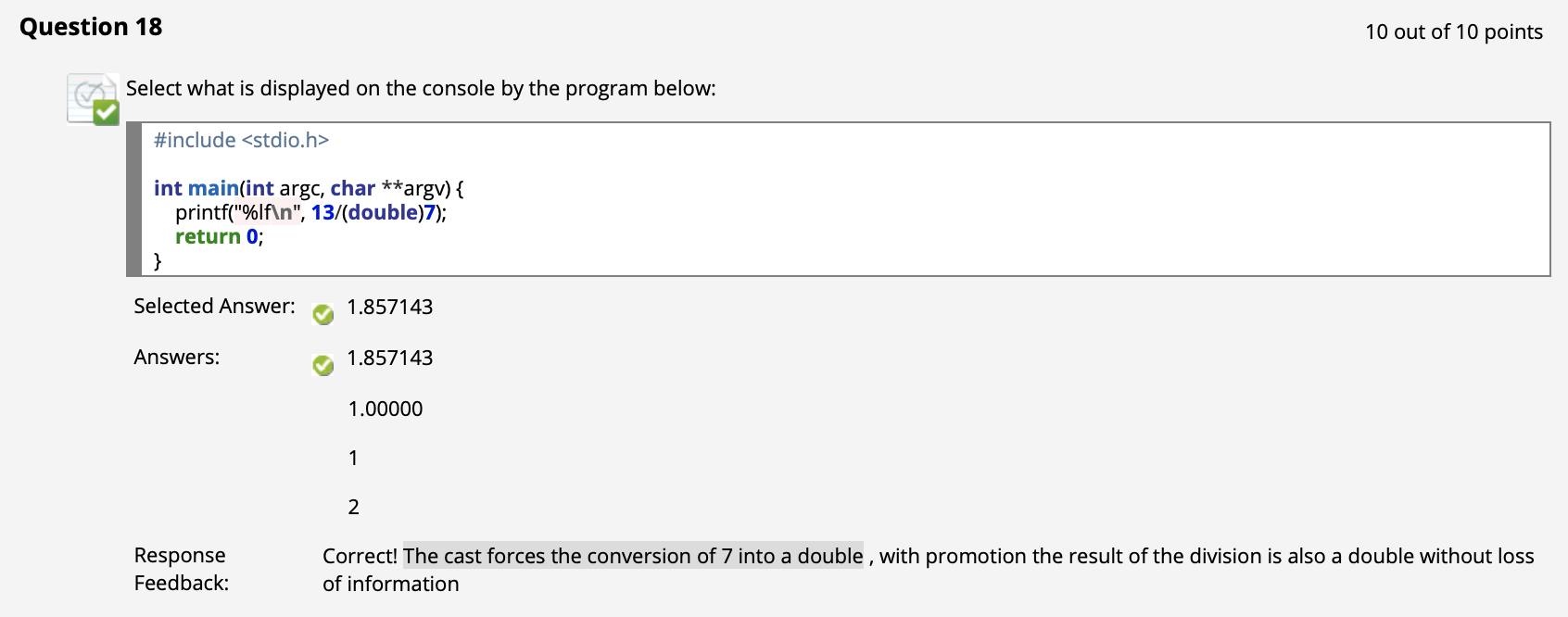
相关题目解析
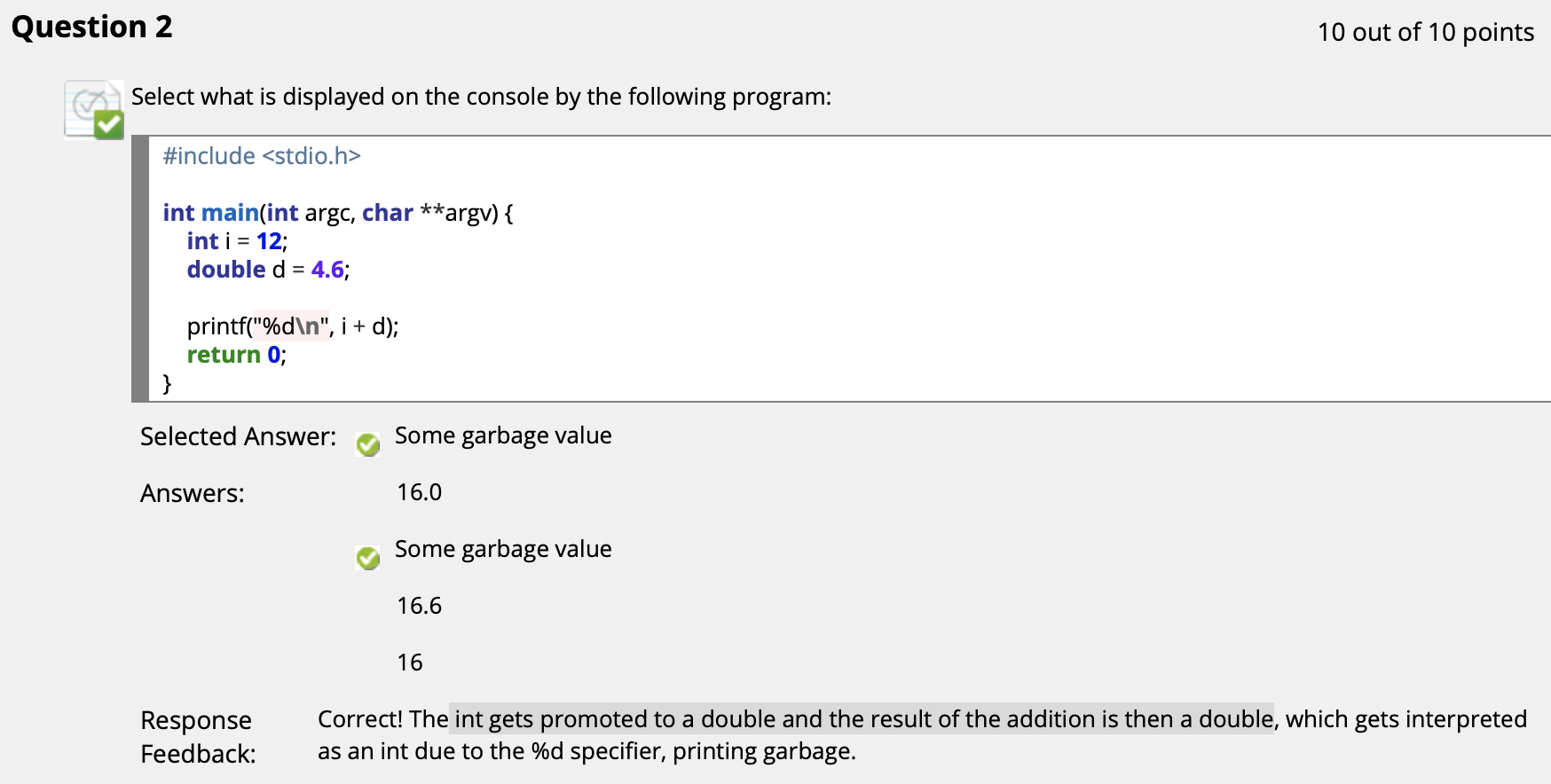
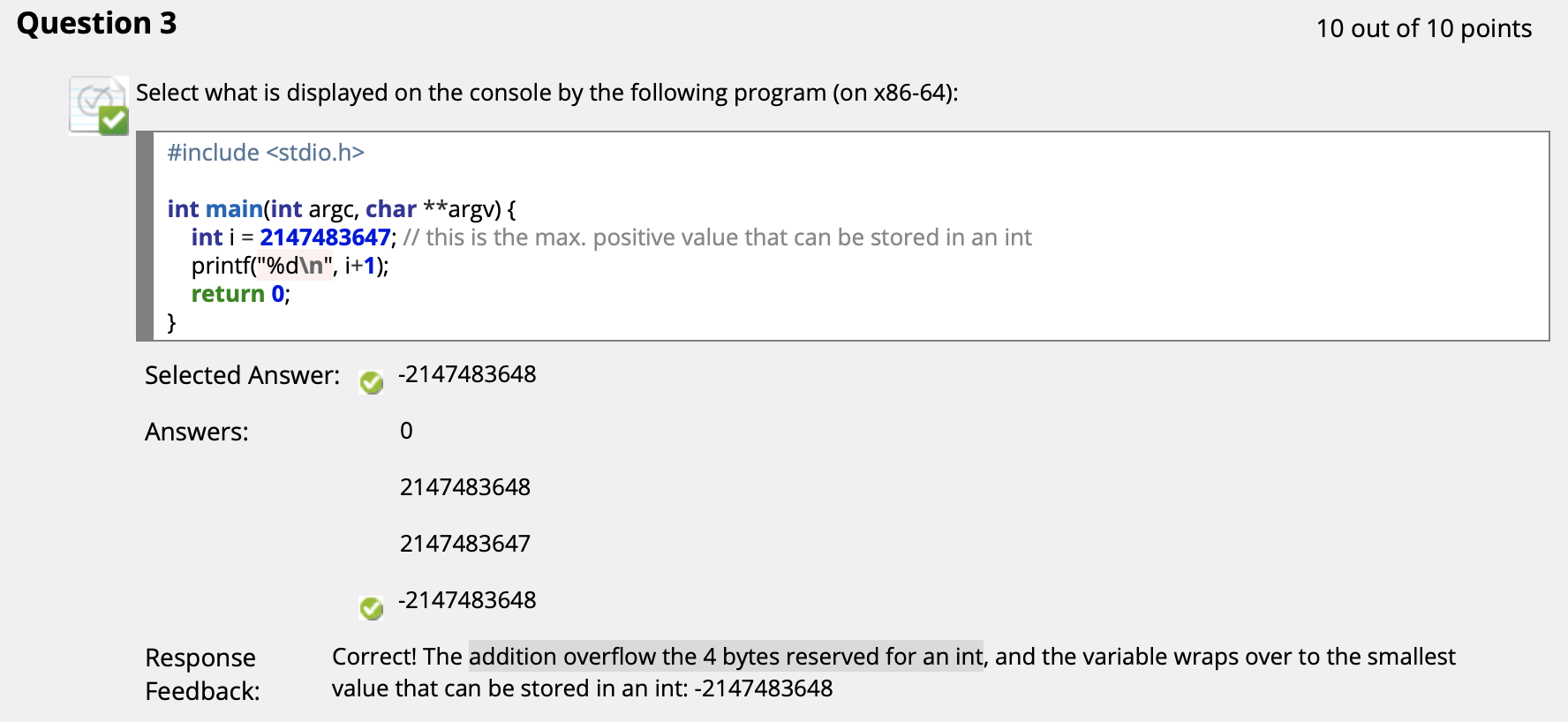
($\uparrow$ 补码表示法决定这个数是 $-2147483648$)
($\uparrow$ 只是单纯的小端序 + 溢出)




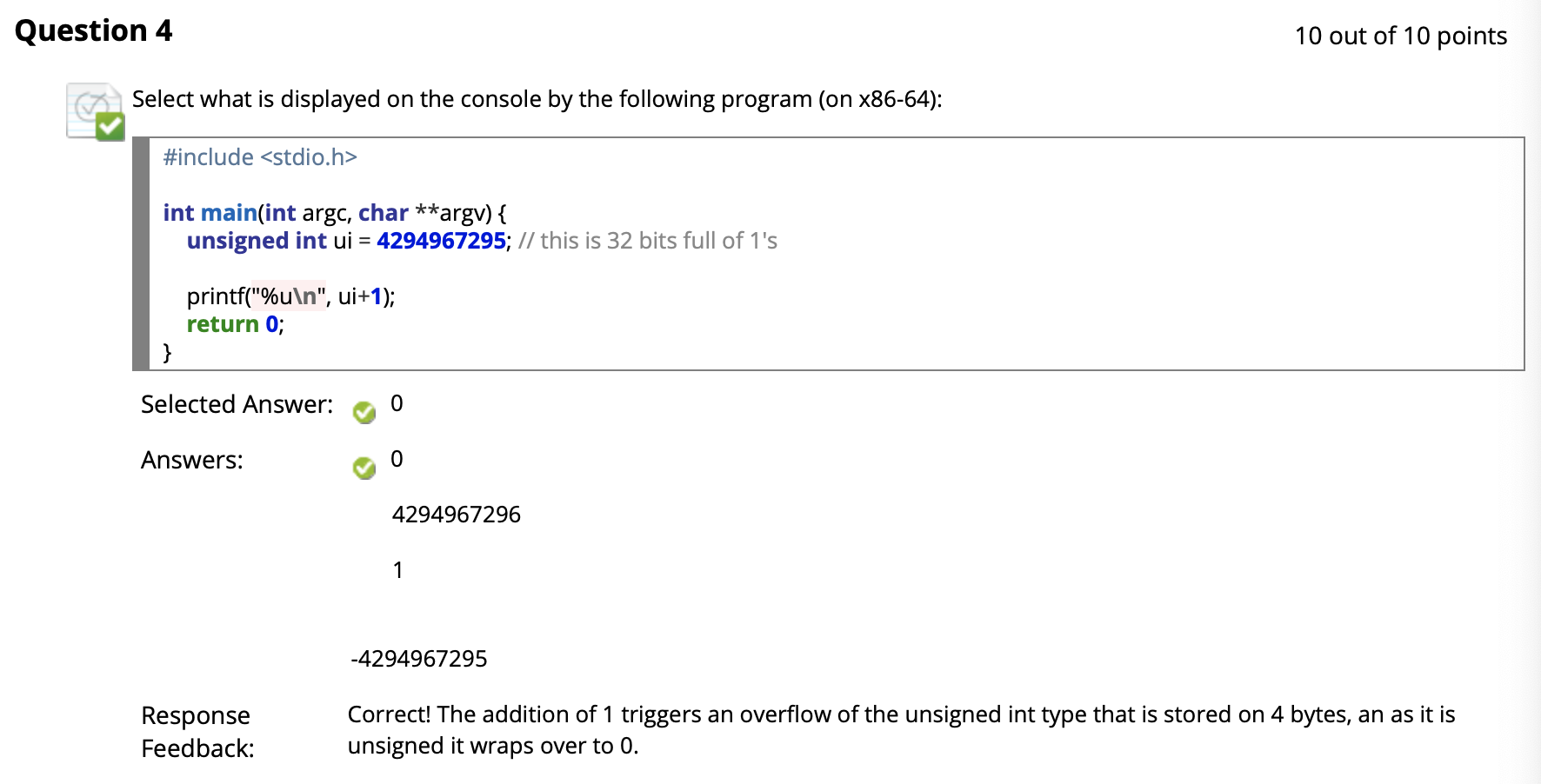
($\uparrow$ 这个应该全选)
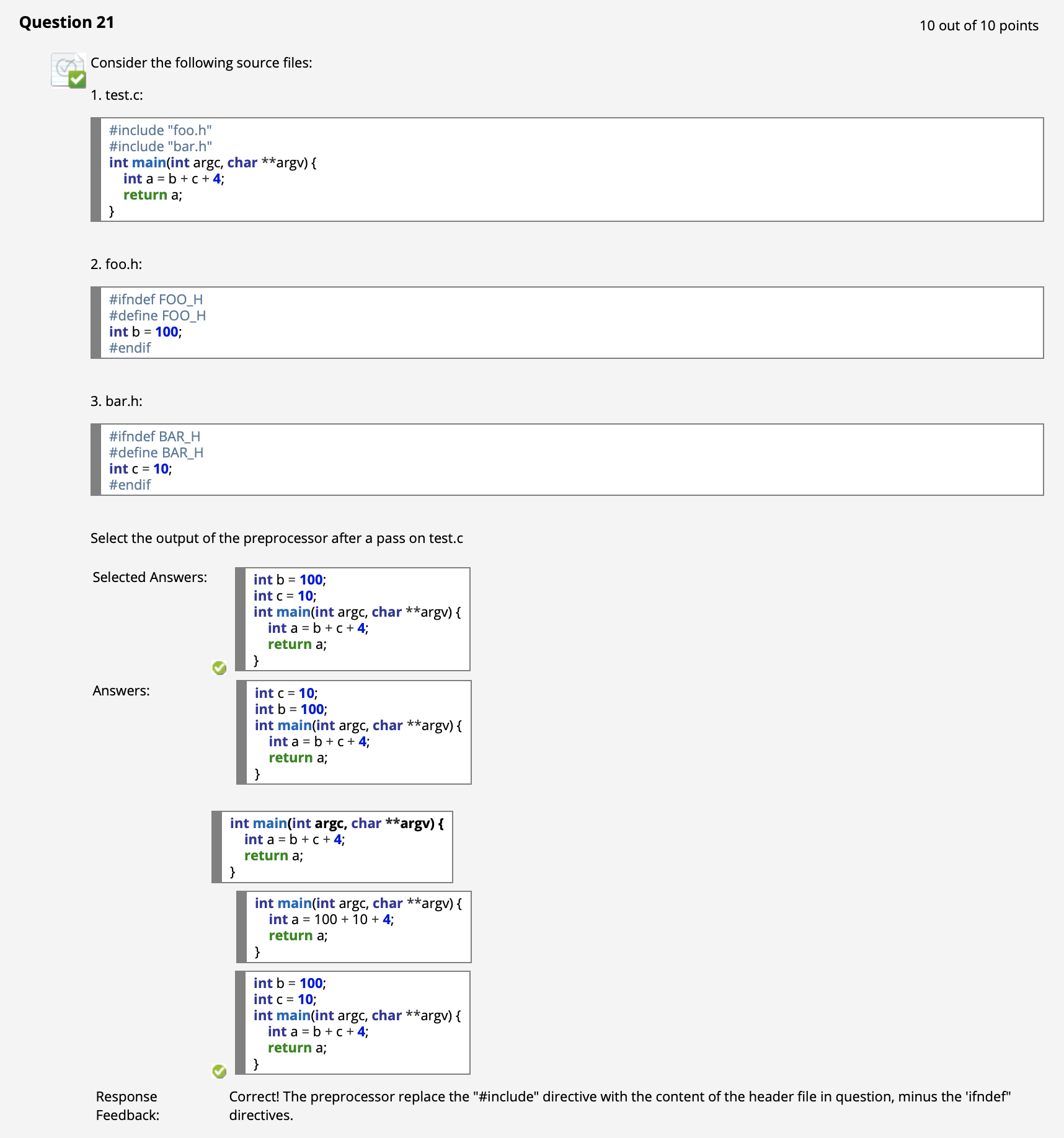
( $\uparrow$ 注意得到的源文件中对应宏变量的定义和处理头文件的顺序一致)
6. 其他课题
操作系统内核
C 语言是编写 操作系统内核 的主流语言. 下面简要了解对 handling system call 和 context switch 的实现:

下面考虑一个简单的操作系统 (HermiTux) 中对 System Call 和 Context Switch 的实现:
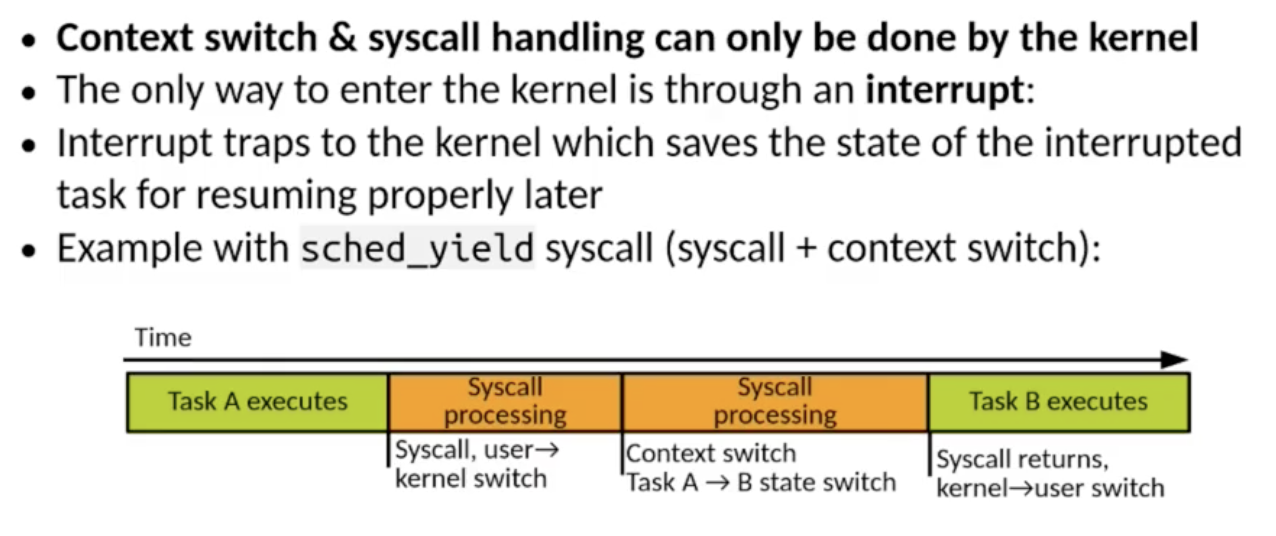
Context Switch 和 System Call Handling: 只能由内核完成
进入内核的唯一方式: 中断 (Interrupt)
(保存当前工作状态 - user2kernel - then do the context switching - kernel2user - 恢复原先工作状态)

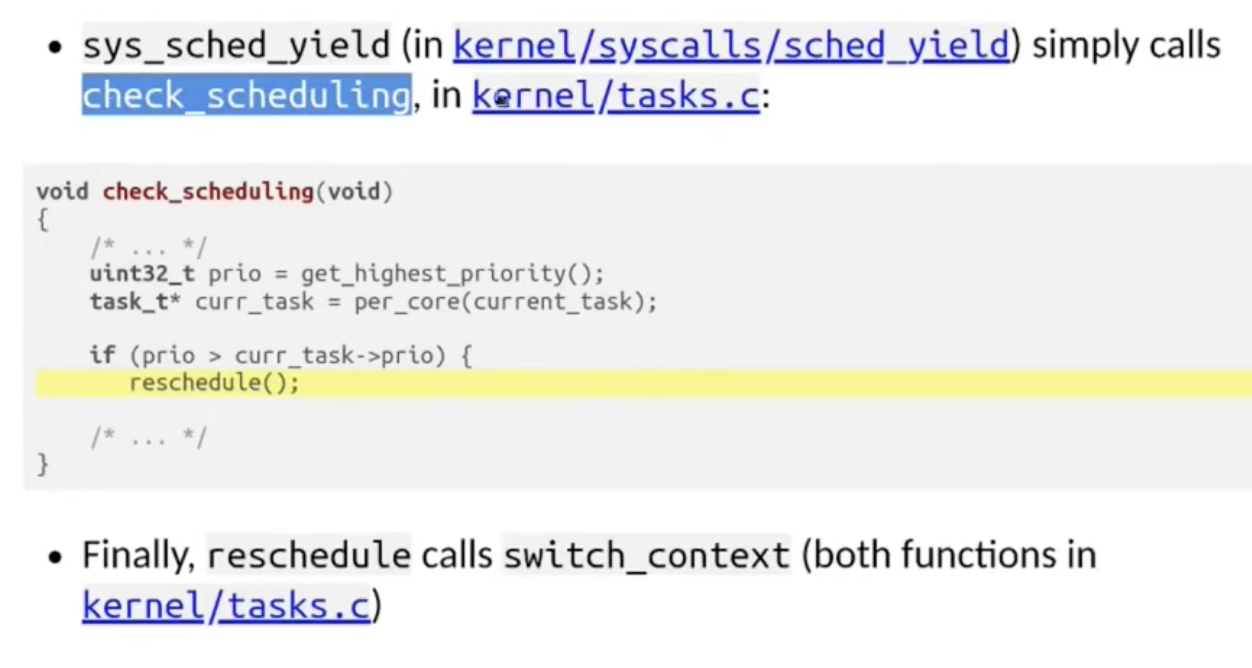

内存安全
C/C++ 天生就是 内存不安全 的, 这是其贯彻高效和接近底层的设计思想带来的代价. 由于内存中存储信息的改变会直接影响程序的运行行为, 且程序在运行时不存在任何类型的内存检查机制, 我们需要格外注意 C/C++ 中的内存安全问题.

案例: 信息泄露 (Infoleak)
Infoleak 的实质是 意外访问到不该访问的内存空间从而导致了信息泄露. 其触发条件是:
无关信息 a 和机密信息 b 先后连续定义, 由此它们在栈中被分配的内存空间是 连续 的.
因此, 若尝试以访问数组的方式访问无关信息, 并且 访问的数组长度超过了无关信息本身的长度, 此时对数组的访问 实际上就变成了对本不该暴露的机密信息的访问.
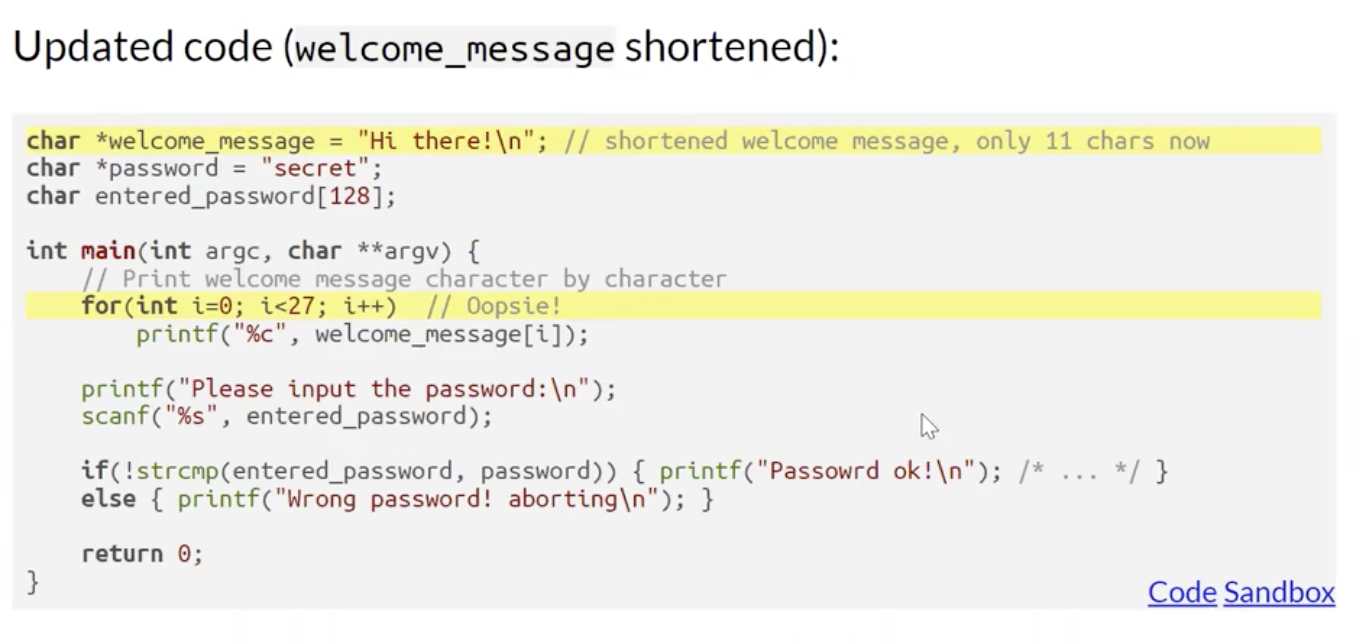

案例: 篡改敏感数据 (Sensitive Data Tampering)
Sensitive Data Tampering 的实质是 利用内存不安全方法 (如 strcpy 等) 的内存溢出漏洞, 使用特殊构造的用户输入利用程序中对内存不安全方法的调用, 让用户输入溢出的那一部分 覆盖掉程序中存储的敏感数据 (如登陆凭证), 从而达到敏感数据篡改的目的.
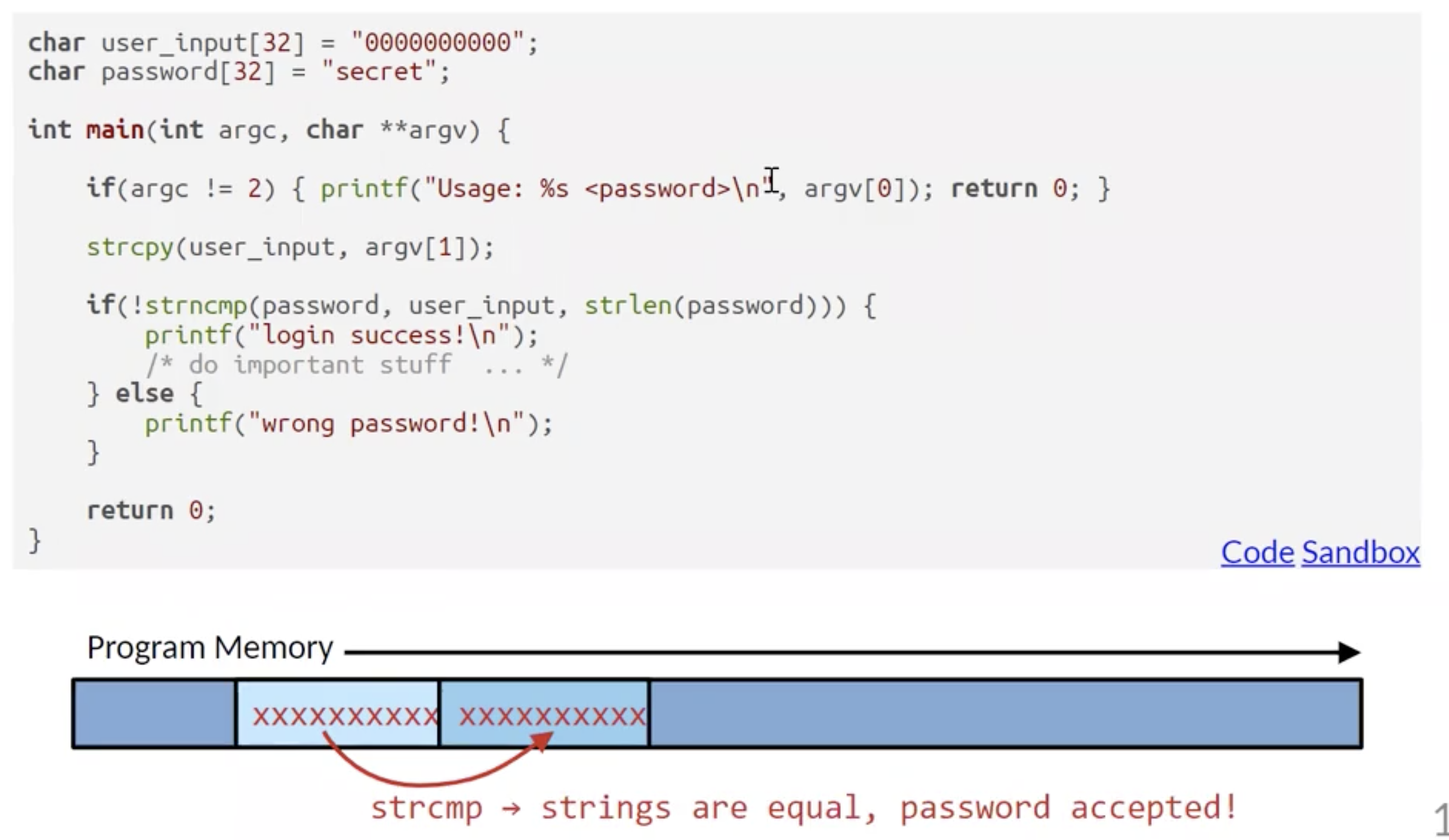
如在上面的例子中, 因为在拷贝用户输入并进行处理时使用了内存不安全的 strcpy(), 程序在尝试将过长的用户输入拷贝到变量 user_input 中时就会溢出并覆盖 内存空间紧随其后的 password, 把登陆凭证彻底橄榄, 爆破登录系统.
案例: 堆栈爆破 (Stack Smashing)
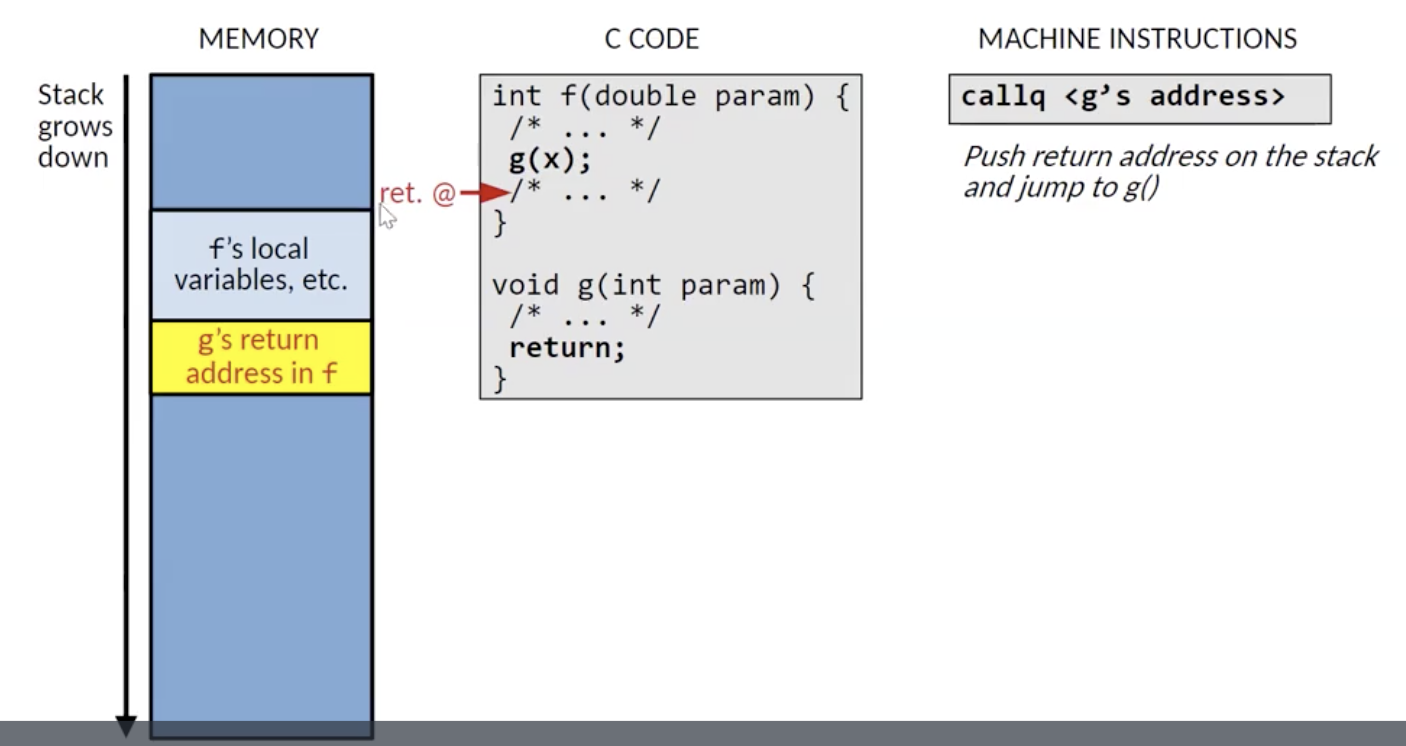
堆栈爆破是经典的 控制流劫持攻击 (Control-flow Hijacking Attack), 其实质是利用处理器执行分支跳转时在栈内先推入函数对应数据, 再推入原来要执行的下一条指令的内存地址的特性, 通过在 被跳转到的函数 中构造/利用内存溢出篡改原来要执行的下一条指令的内存地址, 从而干预程序的执行.

如下图所示, 在执行从 f() 到 g() 的跳转时, 计算机首先会将 f() 当前使用的所有数据全部推入栈中, 然后存入在 g() 执行完后要跳转回来继续执行的下一条指令的内存地址:
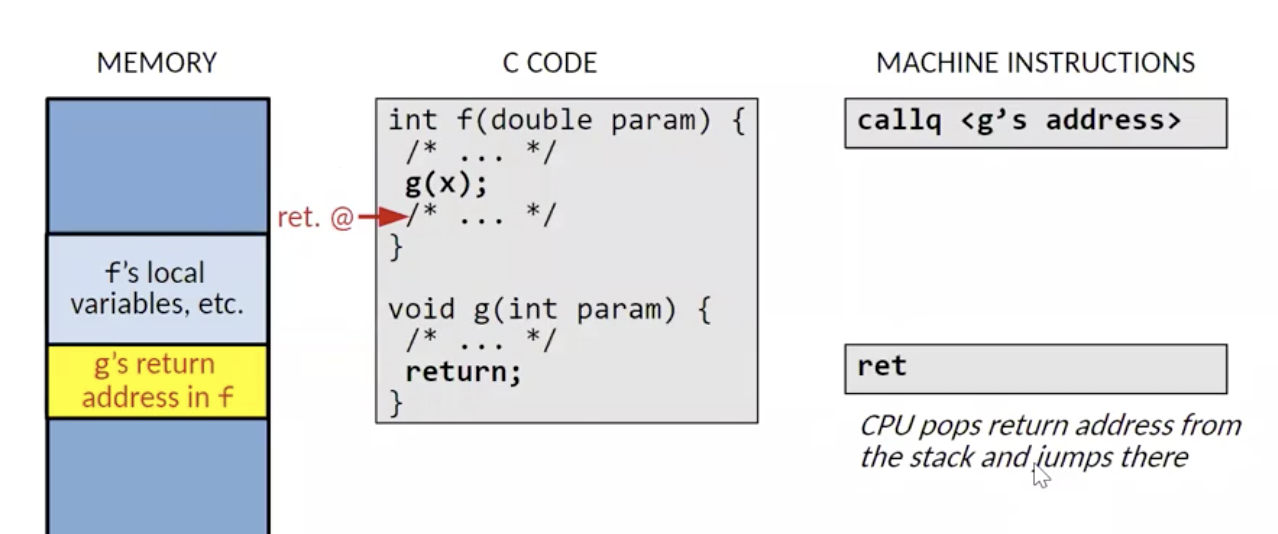
然后处理器就会跳转执行关于 g() 的指令, 在这过程中和 g() 相关的数据使用会利用堆栈的剩余部分.
在 g() 执行完了之后, 与它相关的数据会从堆栈中被清除, 此时处理器会从栈中弹出原来推入的分支返回地址, 然后跳转执行该内存地址对应的指令.
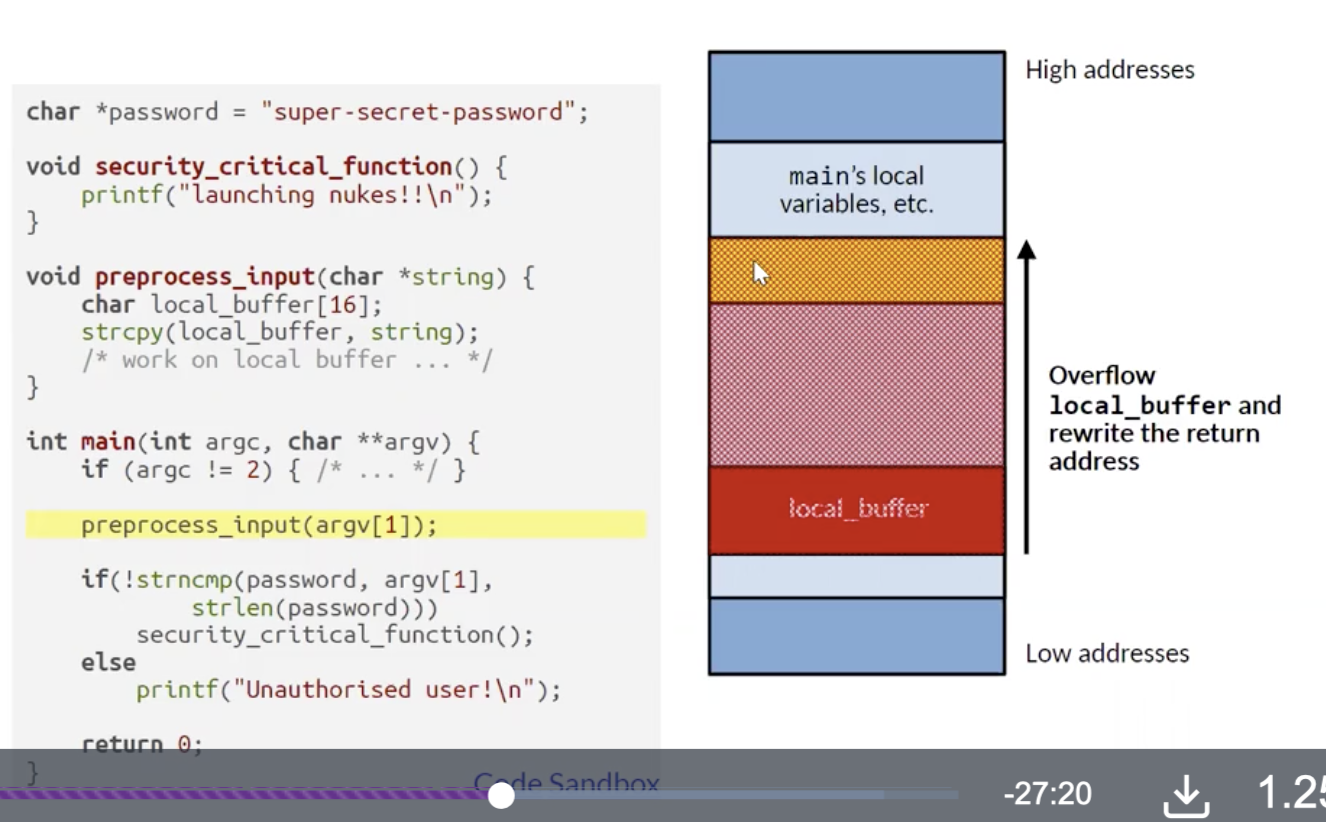
考虑下面的例子:

首先执行 main, 可知 main 相关的变量全部存储在栈的顶端.
然后执行跳转到 preprocess_input(), 由于这是函数跳转, 处理器会在保存全 main() 当前所使用的数据后推入跳转回来对应的下一条指令的内存地址.
然后计算机就会跳转到 preprocess_input(), 在这一过程中该函数内声明的局部变量就会被存储在栈中. 而此处由于我们使用了内存不安全的方法 strcpy(), 如果函数输入 足够长的话, 就会 导致局部变量 local_buffer 溢出, 进而导致 跳转指令的内存地址被篡改.
只要精心设计用户输入, 我们就可以任意修改 preprocess_input 执行完之后程序的行为, 比如跳转到可以造成进一步破坏的 security_critical_function.

案例: 幽灵访问 (Use After Free)
幽灵访问的实质是利用 函数指针 的特性构造溢出实现对特定函数指针的篡改, 从而达成执行任意代码的目的.
首先介绍函数指针: 函数指针是指向函数的指针, 对函数指针进行间接应用, 提供对应的参数就可以达成执行这个函数的目的.
考虑下面的例子:
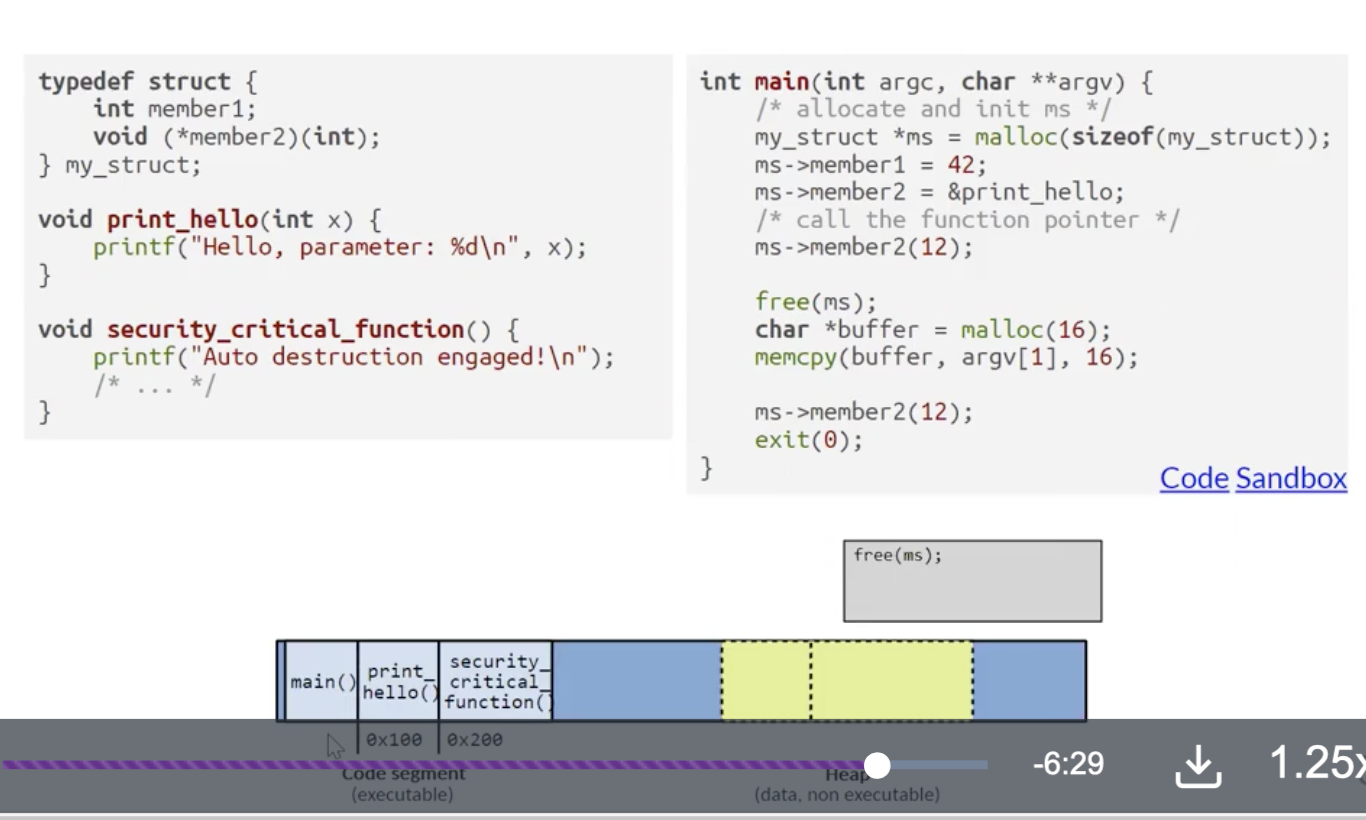
在上图所示的例子中, 我们的目的是篡改函数指针从而执行恶意代码 security_critical_function.
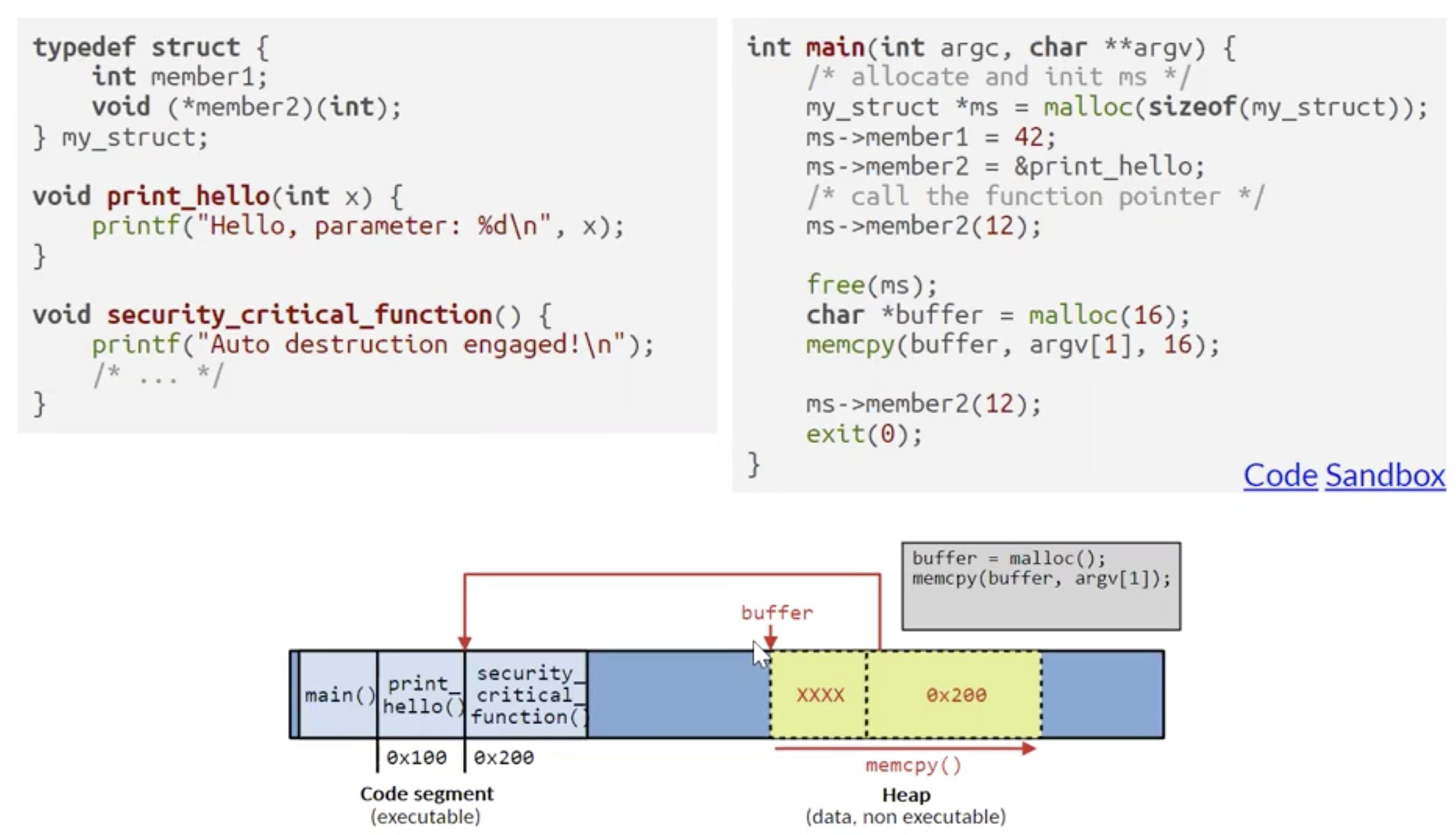
由于在右侧的代码中我们首先声明并从堆中释放了 包含函数指针的结构体 ms, 然后又在 (实际上就是结构体 ms 本来被分配的堆空间) 空闲的堆空间上存储数组 buffer, 因此通过合理构造 buffer 就可以使原来存储在结构体中的函数指针被覆盖为我们想要的恶意函数指针, 从而利用右侧代码倒数第三行对本不该再调用的结构体中的函数指针的二次调用实现跳转执行恶意代码.
C/C++ 中内存安全的合理实践
在上一节中, 我们已经了解到 C/C++ 内存不安全的特性, 我们可以通过在编程中应用 合理实践 避免常见的, 导致内存不安全的问题出现.

我们首先可以使用多种分析工具对我们的程序进行内存安全分析:

但最重要的还是使用 合理的实践和良好的风格 编程:

避免 Undefined Behavior:

- 控制数组/
Buffer的大小, 注意数据的长度和类型转换问题, 从而避免整数溢出问题:

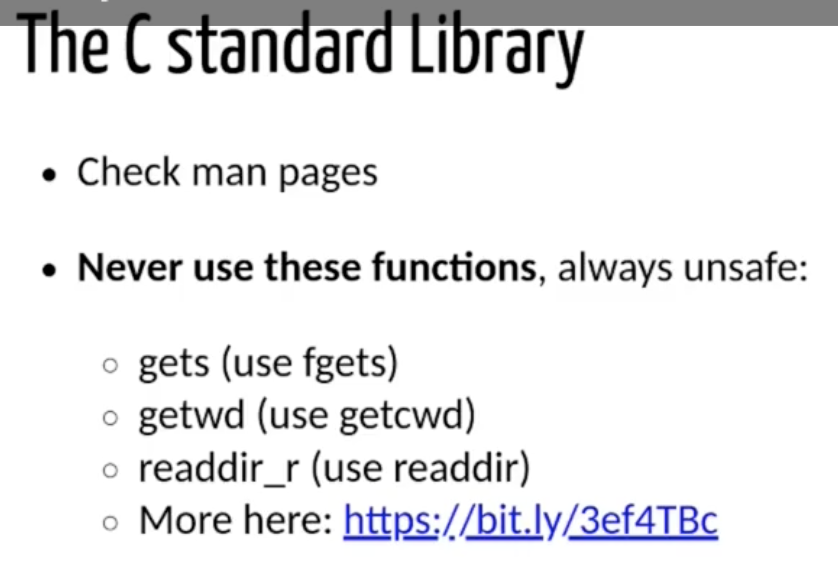
- 避免使用下列的 内存不安全 的函数:
- 使用 内存安全的字符串操作函数:

- 在动态内存分配时检查
malloc返回值, 避免间接引用或直接引用被销毁的指针, 谨慎使用 不会销毁旧指针 的realloc(ptr, new_size)方法:

相关题目解析

($\uparrow$ 被 NULL 覆写, 丢失引用, 再也无法释放指针指向的buffer)


($\uparrow$ 函数中调用函数, 被调用函数中存在内存不安全方法的调用, 典型的堆栈爆破特征)