
信息检索
本章我们将简要讨论信息检索问题.
信息检索问题是一类重要的自然语言处理问题. 其实质是一种 对文档索引, 搜索和取得的技术.
其基本定义是: 从 规模巨大的存档中 提取出 非格式化, 无组织的文档 以满足 特定的信息需求.
信息检索最常见的使用场景是: 用户使用英语在搜索引擎中查找所需要的网页信息. 但英语网络搜索引擎只是信息检索应用的一个 真子集: 信息检索的应用 不仅可以是搜索引擎, 使用的语言涵盖范围极广 绝非仅限于英语, 并且信息检索的对象也 不仅是文本信息, 比如可以是 口语问答, 音乐检索或图片检索等.
信息检索的一般结构是: 用户 使用 查询语句 向 信息检索系统 提出查询需求 (Query), 信息检索系统从 信息存档 中基于某些规则找出与查询需求 相关 的信息返回给用户.

信息检索的一般特征和分类
信息检索的一般特征是:
- 被检索的信息一般是 无组织 的: 这些信息一般包含的结构 仅能被人类所识别, 如段落结构和基于渲染目的的标签结构.
- 信息库的规模一般是 极其庞大 的: 信息库的规模往往庞大到 完全不可能人为整理和检索, 并且还可能包含 时刻在动态生成或更新 的信息.
而信息检索所需要满足的需求也是 较为模糊 的. 信息需求 (Information Need) 一般指 任何用户所想要在互联网中查询的内容.

下面讨论 信息需求 的基本分类. 我们可以大致地将用户的信息需求分为以下三类:
-
Navigational: 用户提出查询的目的是 访问和定位到某个特定网站.
-
Transactional: 用户提出查询的目的是和 行为 强相关的: 比如使用网络进行购物和沟通, 从网络上下载资源, 以及消费音视频等内容.
-
Informational: 用户提出查询的目的是从网络上 获取信息.
其中, 以 Informational 类型的查询占绝大多数: 超过 $70\%$.
信息检索的目的
信息检索的一大目的是为用户提供 和查询语句相关的信息, 以满足用户的信息需求. 因此, 我们需要对 “信息关于查询语句的相关性” 进行建模和讨论. 宽泛地说, 判断给定的信息和用户的查询是否 “相关” 是 主观的, 难以给出确定的规则. 因此, 要判断或计算信息关于查询语句的相关性, 首先需要对这个复杂的问题提出 假设, 将其简化:
此处, 我们将 信息本身 和 用户的查询语句 都统一转换为 某种表示方式 (Representation), 由此对相关性的判断就可被转化为 对者两个信息表示之间相关性的计算.
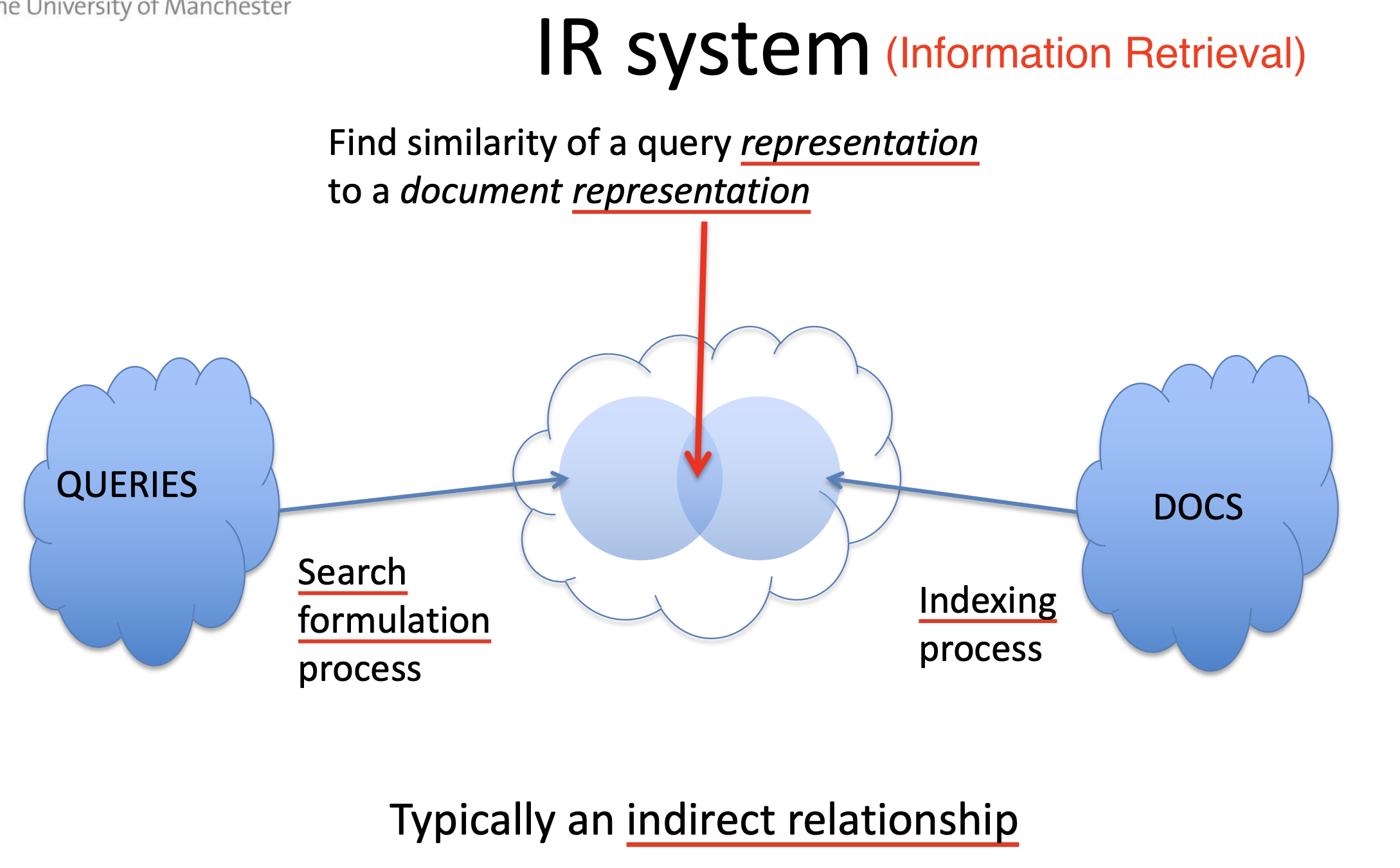
索引
下面讨论如何对信息本身和查询语句进行表示. 最简单的方法自然是定义一系列 索引项 (Index Term), 在给定信息或查询语句后, 从它当中抽取出所有索引项, 然后基于不同索引项的优先级或匹配的索引项的个数等指标衡量信息和查询语句是否相关.

基于索引定义的信息检索系统包括 索引过程 和 搜索过程.
在索引过程中, 系统需要从多种渠道中获得足够的信息文档 (Document) 存入资料库, 并为每一份文档生成 (计算出) 它对应的索引, 比如 关键字/词提取, 然后将计算出的, 一一对应的索引用某种便于搜索的方式存储.
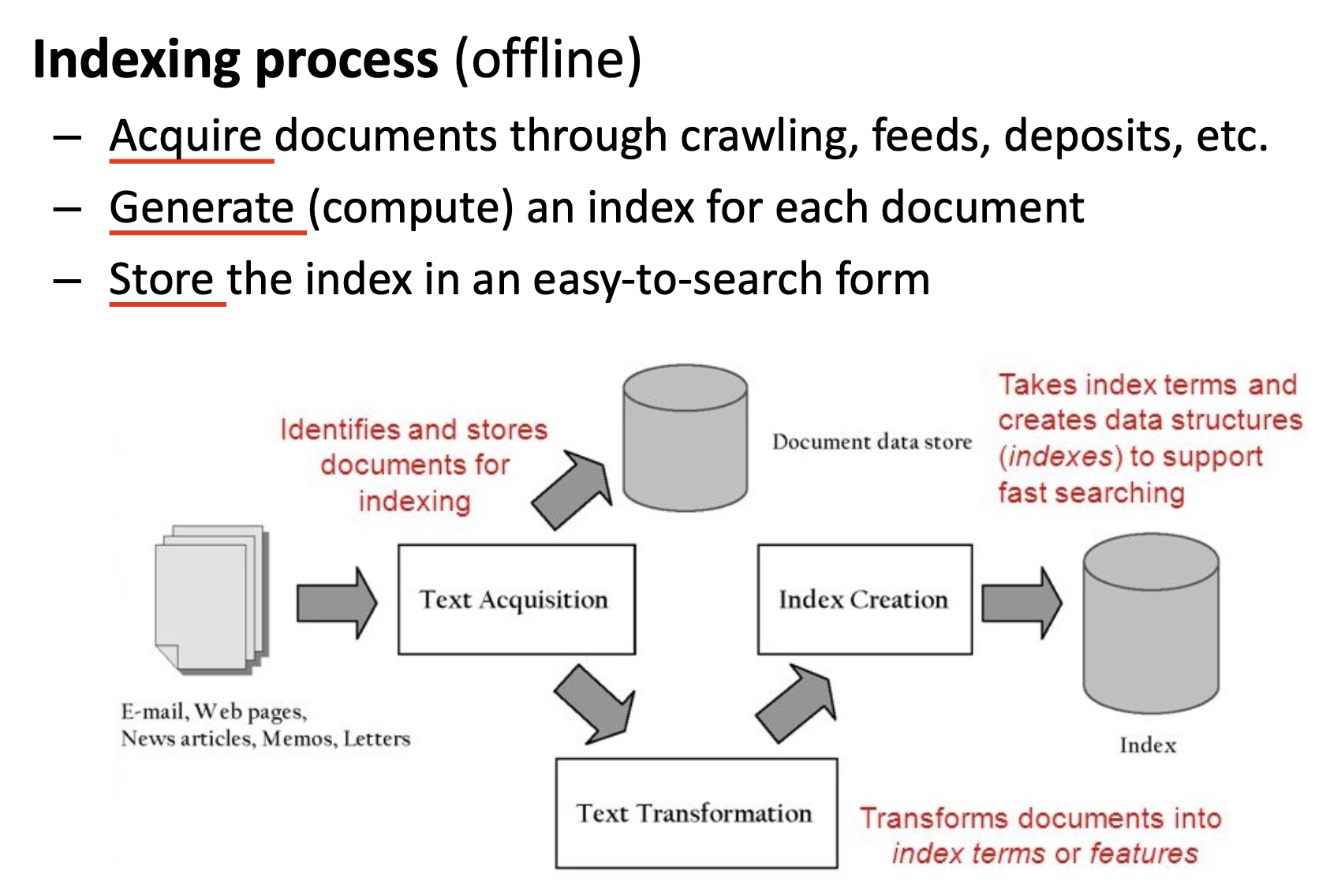
在搜索过程中, 由于整个搜索过程高度依赖一系列预先定义好的索引词, 系统需要 帮助用户完成他们的查询语句, 在需要的时候自动填充或建议和用户查询含义相近的索引词.
在形成用户查询语句后, 就需要将语句也转换为一系列索引的形式 (index the query), 然后将经过转换的用户查询语句和数据库中的 每一篇文章的索引对比, 从而完成数据库中所有相关文档的提取和优先级排序.
最后, 系统还需要协助用户浏览查询的结果, 如用户不满意, 需要允许用户重新构造查询语句; 最后依据需要对用户的行为进行 记录和存档.
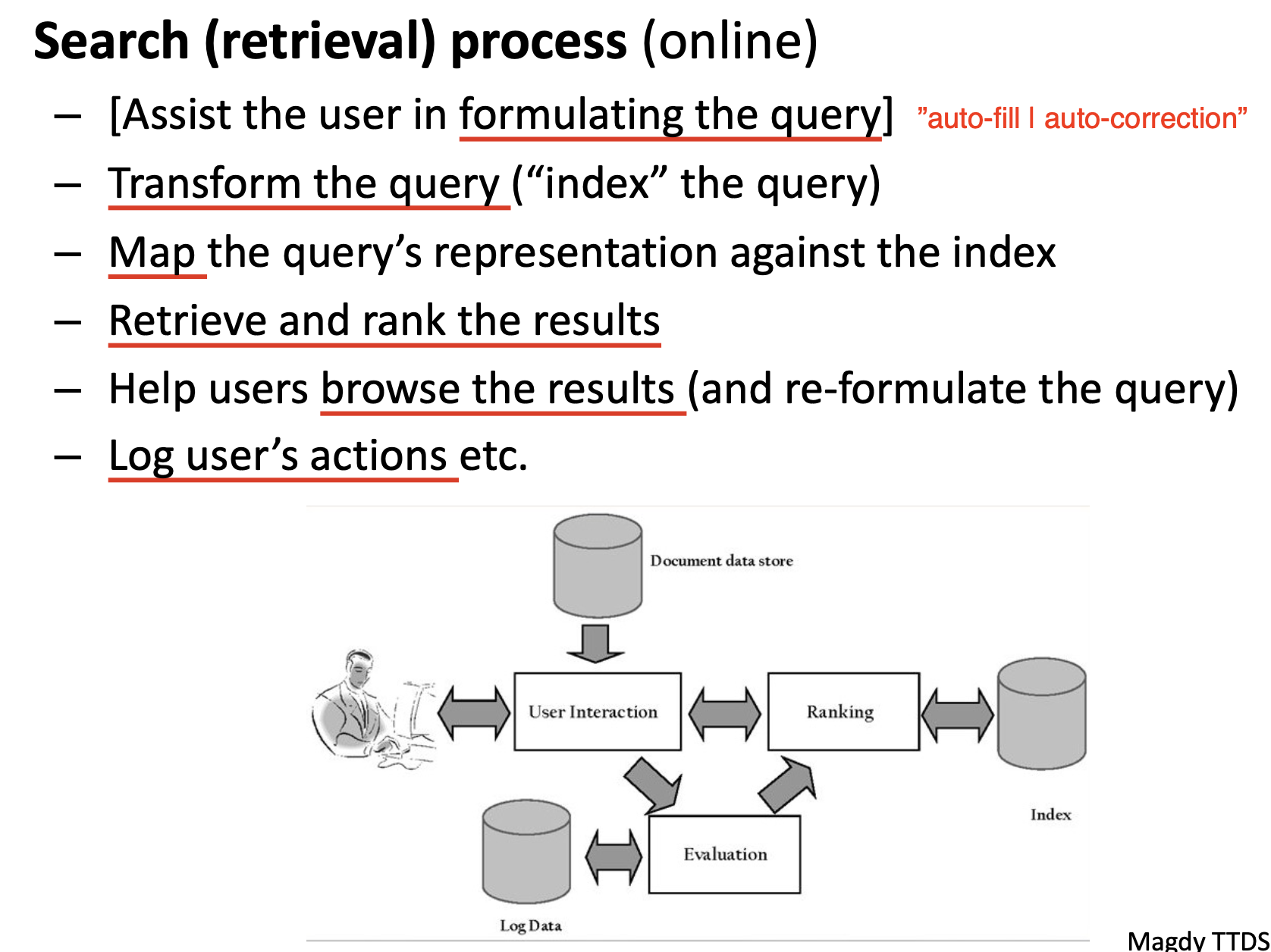
在了解了索引法定义的信息检索系统的基本结构和工作流程后, 我们自然需要考虑: 什么才能被作为合适的 索引. 在实践中, 用作索引的往往是 一系列预先定义的搜索项 (Controlled Search terms | tags) 或 关键字 (Words), 如下图所示的医学文献数据库 PubMed, 它就使用了一系列医学术语作为查询的关键字. 通过对每篇文档进行人为的标记, 手动赋予它们一系列关键字组成的索引, 用户在 基于关键字查询 时就可以非常准确地得到所需要的结果.

索引法的优势是:
- 搜索结果准确, 搜索过程便于机器处理, 存储和计算
- 若信息的索引是经过人为标注的, 往往其质量要高出平均水平.
但其显而易见的劣势是:
- 搜索语句可能有非常严格的语法限制且不支持模糊搜索, 对搜索者的要求很高;
- 由于信息索引是一个人力过程, 因此对信息的标注不可避免地会有 延迟.
- 由于限定了一系列关键词作为索引基准, 查询语句的表达力 (
Expressiveness) 同样被关键词所限制.
不难看出, 即便是索引系统, 在定义关键词时也需要遵循一系列标准: 我们如何从大量单词中选择合适的索引词? 如何对文档的相关性进行排序? 我们将在下一节中介绍一种确定合适的索引词的方法: 倒排索引 (Inverted Index).
倒排索引
下面引入 倒排索引 (Inverted Index) 的定义并讨论如何使用它寻找合适的索引词.
回顾上一章讨论语言建模和表述时介绍的内容, 我们提及了描述单词出现频率和其重要程度的 齐夫定律 (Zipf's Law) 和 卢恩假设 (Luhn's Hypothesis), 以及一种最简单的表示模型: 词袋模型.
值得注意的是, 词袋模型其实被广泛应用于多种信息检索系统中. 对于任何曾经在数据库的 任何文档 中出现过 至少一次 的词, 都可以被划入 Text-Document Matrix 中:
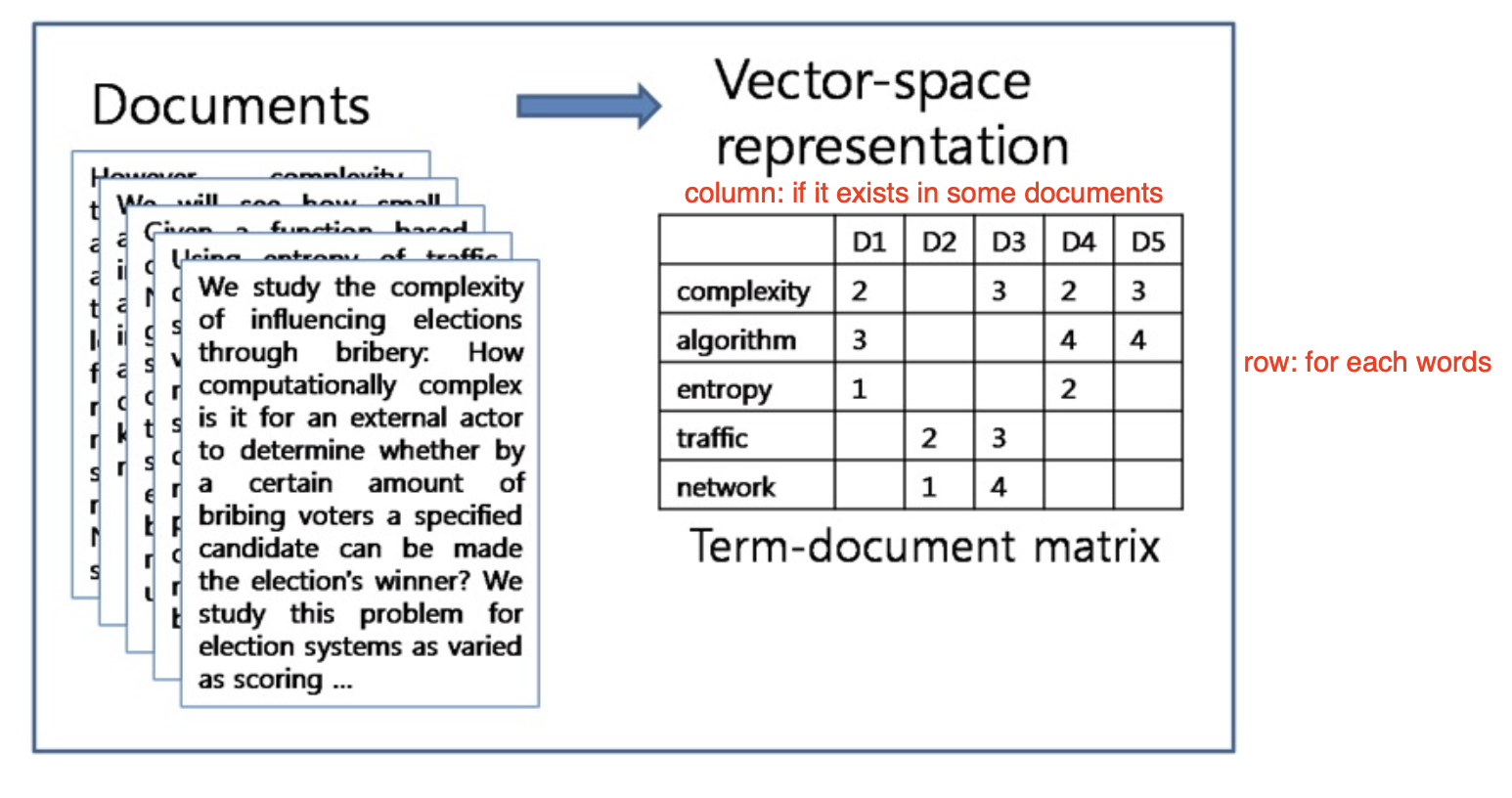
从第二行开始, 每一行表示一个单词在 每一篇文档中出现的次数, 这就是所谓的 词项-文档矩阵 (Term-Document Frequency Matrix).
相应地, 如果将词项-文档矩阵中的每一个数据项 (entry) 改为 $0$ 或 $1$, 也就是标记 这个单词在文档中是否出现, 就得到了 词项-文档关联矩阵 (Term-Document Incidence Matrix).
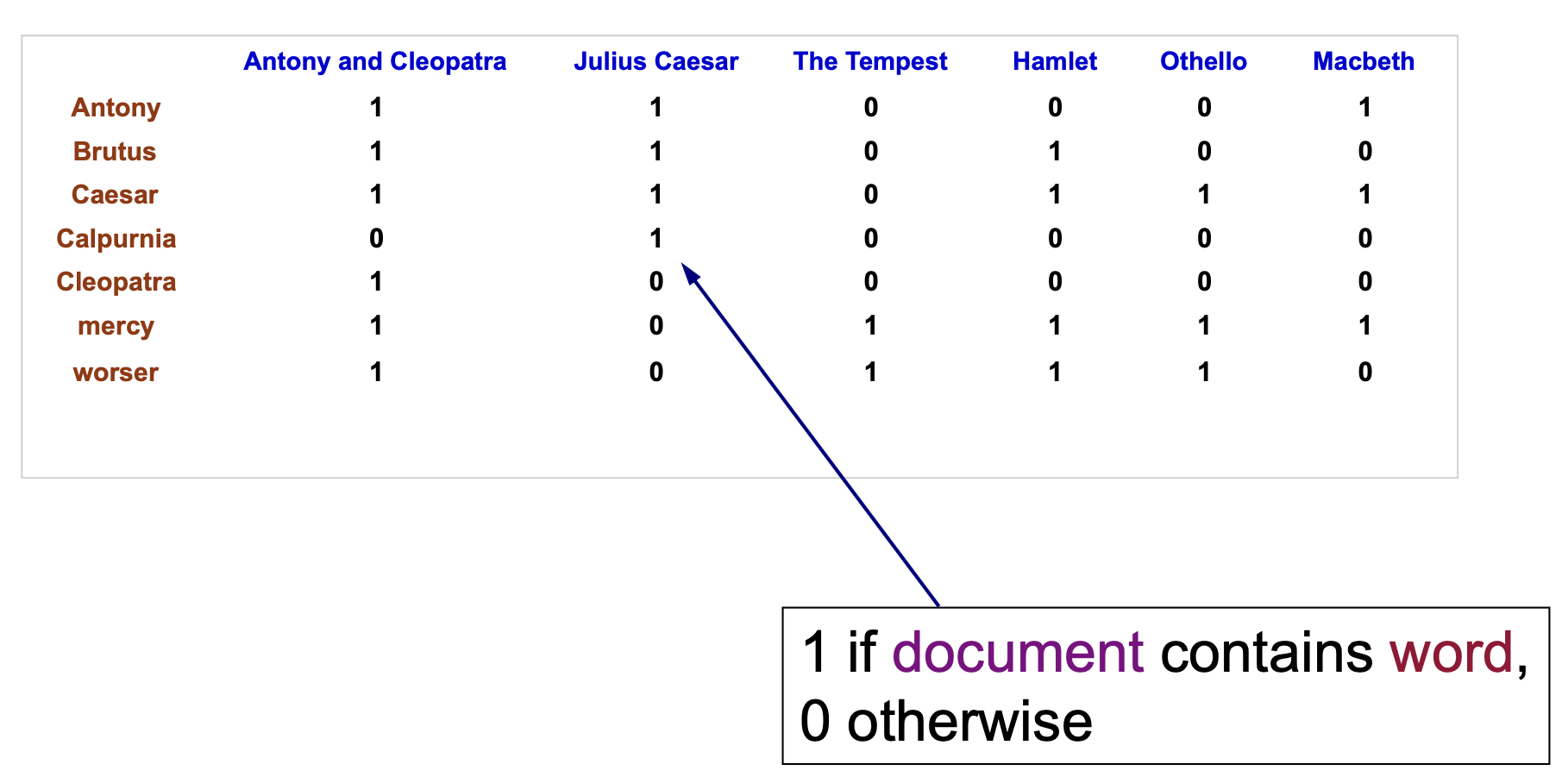
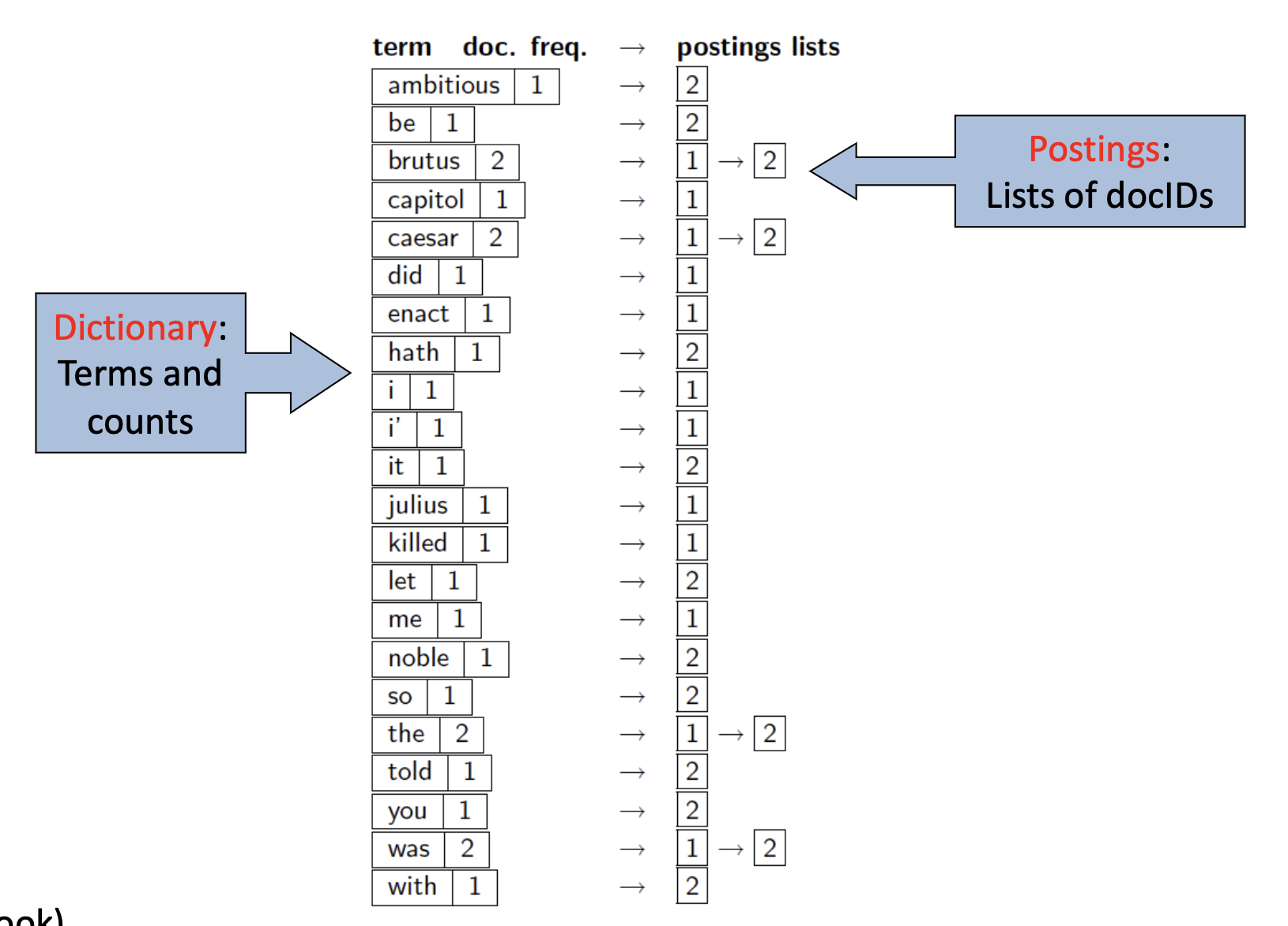
需要注意的是, 直接构造的词项-文档矩阵或词项-文档关联矩阵一般来说都是 稀疏 (Sparse) 的: 矩阵中绝大多数的项都为 $0$. 这样的数据结构如果使用普通的矩阵存储法会造成空间的严重浪费, 因此务实的做法是存储 倒排索引.
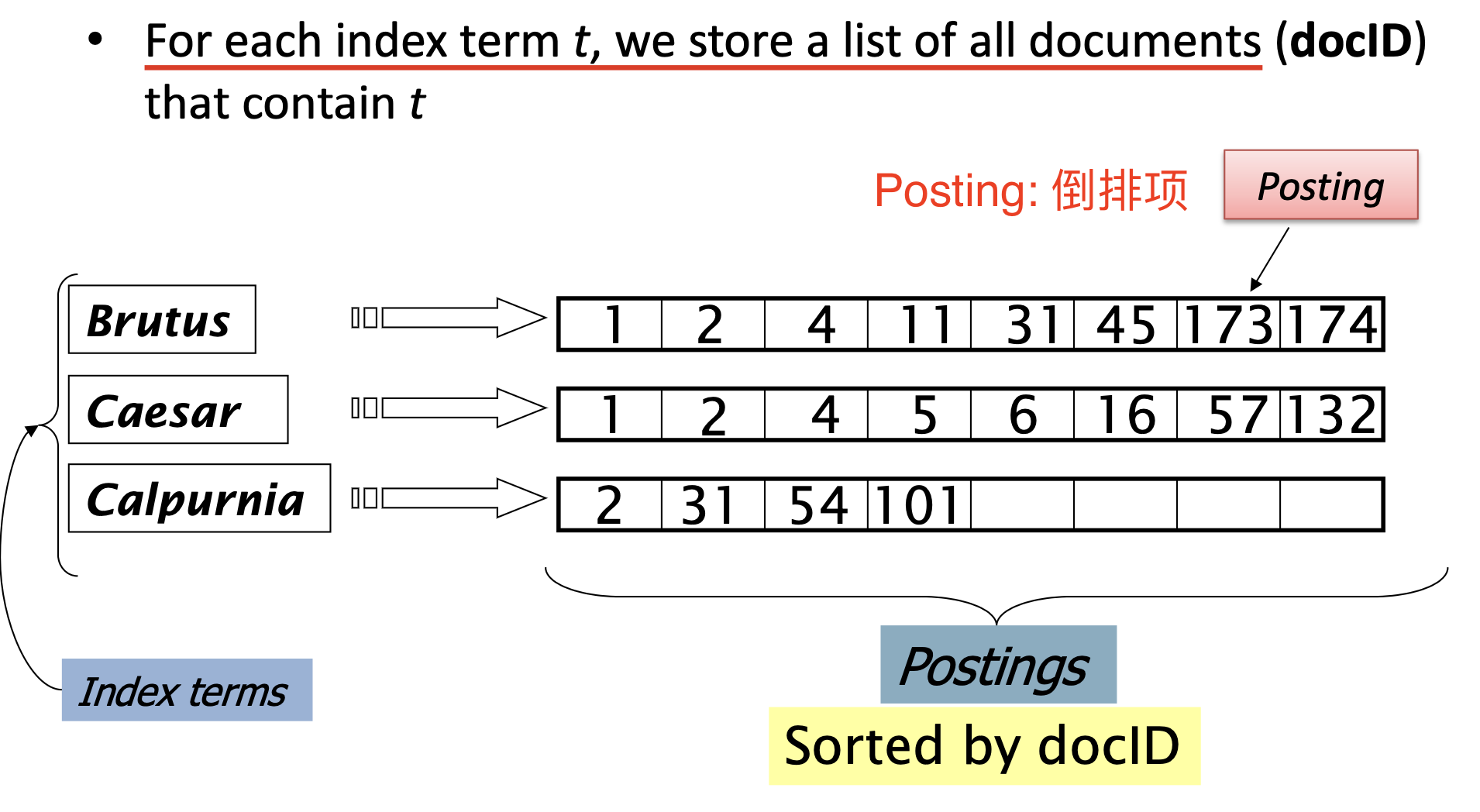
不同于给定文档, 检索文档中每一个单词项出现的次数, 我们选择 对每一个单词项存储它所出现过的文档的编号, 在搜索时 以单词而非文档编号作为索引, 如下图所示.
要构建倒排索引, 需要完成下列的几个步骤:
-
首先需要对每个文档进行索引, 记录下文档中都出现了哪些单词, 生成一系列 词项序列:
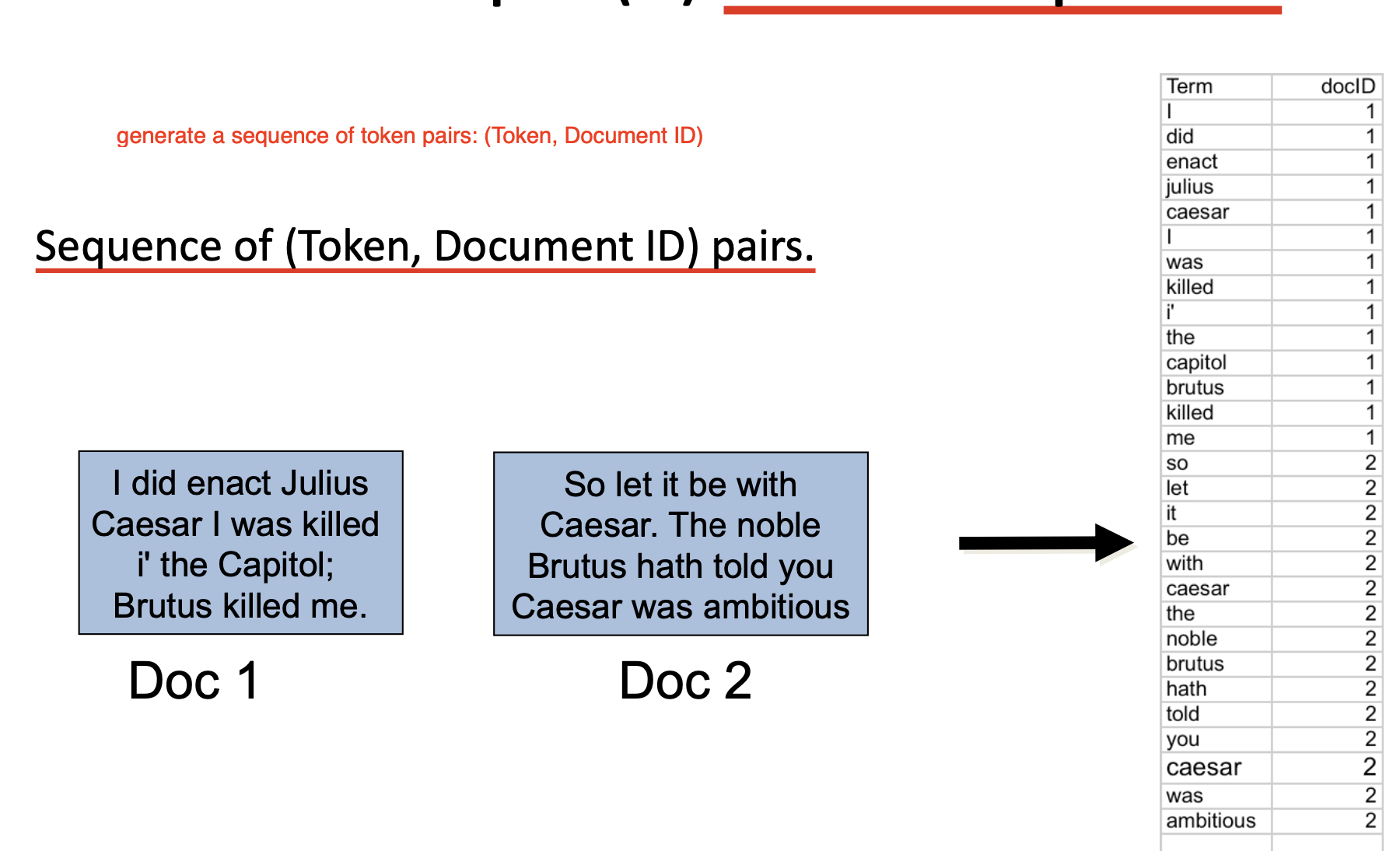
-
随后需要对词项序列进行 两步排序: 优先基于词项排序 (在英文中也就是按照首字母顺序排序), 然后再根据词项序列中每一项纪录的 文档编号 进行排序.
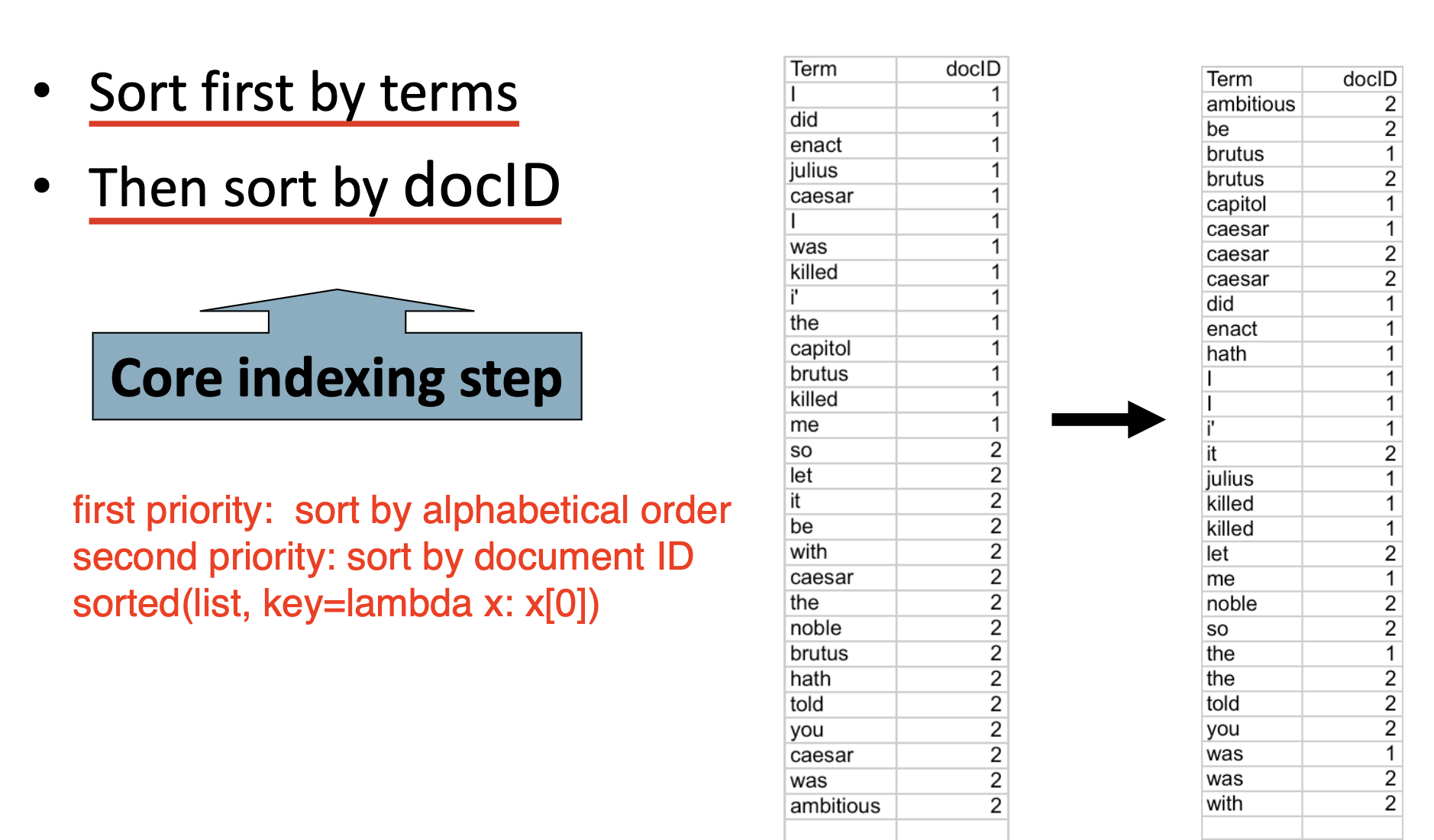
-
最后基于经过排序的索引构造 字典 (
Dictionary) 和 倒排文件 (Postings): 如果某个字词在单个文档中出现了多次, 则将它们 整合 (Merge), 记录下字词在文档中出现的次数; 并将索引拆分为存储 字词本身 和它的 文档频率 的 字典, 以及倒排文件.

经过这两步就完成了倒排索引的构建.
查询和结果排名
在本节中, 我们将继续介绍如何进行 查询, 并引入数种计算 结果排名 的方法.
布尔表示
最简单的查询模型是: 寻找所有 完全与查询语句匹配 的文档. 因此对每篇文档而言, 它的状态只有两种; 匹配查询 (True), 或 不匹配 (False).
要实现这种查询, 就可以结合 布尔算符: AND, OR 和 NOT, 如下面的例子所示:

下面依次讨论查询语句中可能出现的三种布尔算符的处理方法:
-
AND:结合倒排索引, 假设查询语句是
Brutus AND Caesar, 则首先从字典中定位这两个单词Brutus和Caesar, 并获取它们的倒排文件 (Postings).然后依次遍历它们倒排文件中存储的文档编号, 对两个倒排文件进行 合并: 找到所有同时出现在两个倒排文件中的文档编号即可, 这就是
AND的查询结果.
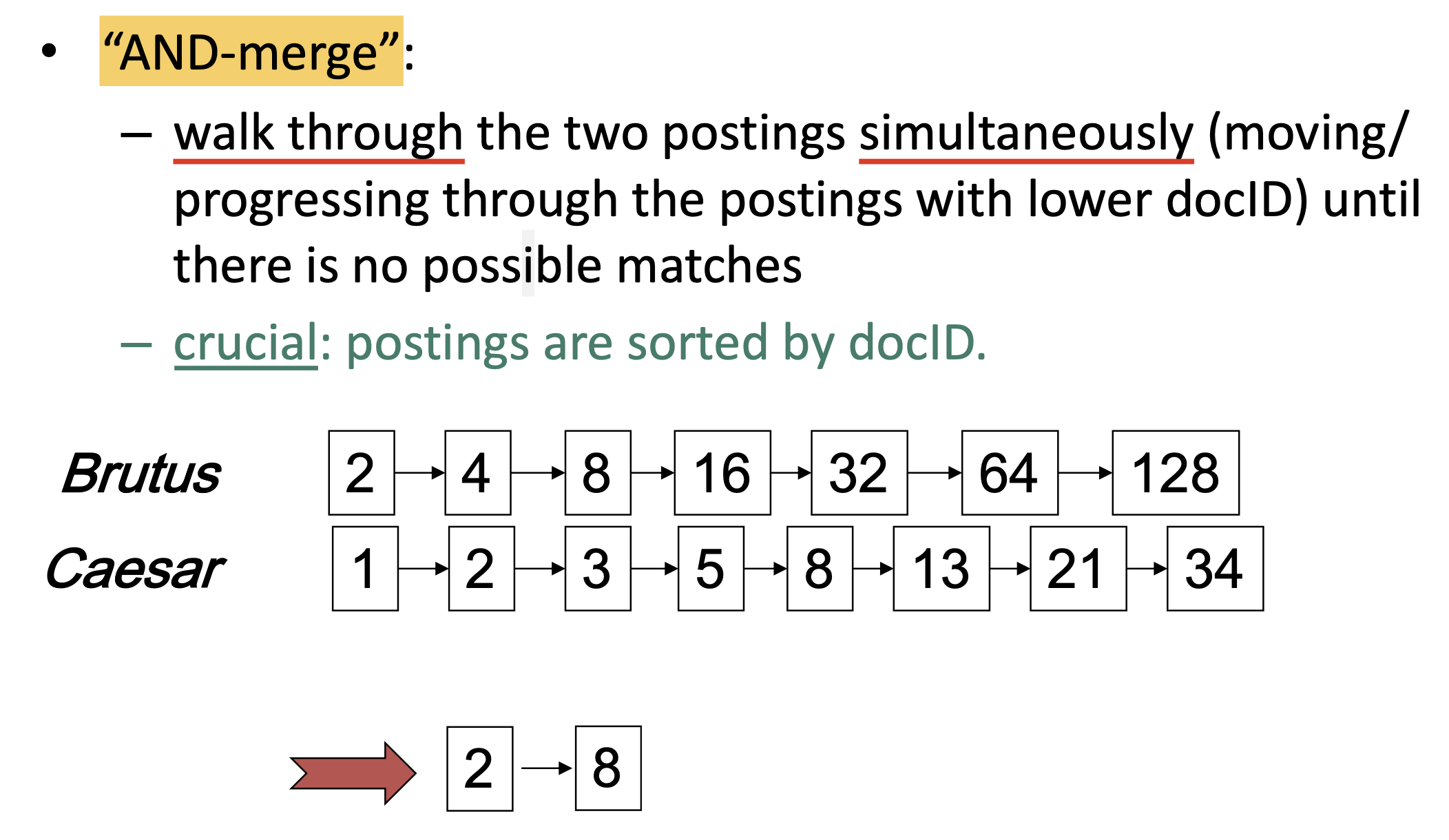
需要注意, 对于
AND语句的搜索, 最重要的前提是: 倒排文件中的文档编号都是按顺序排列的. -
OR:相应地, 对于
OR, 任何倒排文件中出现的任何文档编号都是一个合法的查询结果. -
NOT: 和AND类似, 只不过在合并倒排文件的过程中关注的是 剔除所有同时出现过的序号.
可见, 布尔查询模型结构简单, 将任何文档和查询语句都简化为了一系列字词 (Terms). 布尔查询模型实现简单, 并且具有精确的特点, 可对查询语句进行精准控制, 但构成合适的查询语句非常困难, 不具备任何模糊搜索的能力, 其表达能力具有很大的局限性, 只适用于专业领域; 同时, 它的检索结果也无法排序.



一种优化布尔排序的方法称为 扩展布尔模型 (Extended Boolean Model): 它在倒排文件的生成过程中, 对于每个字词不仅记录了它在哪篇文章中出现过, 还 记录了它在这篇文章中出现的位置, 每次出现 (Occurrence) 都会被作为一个单独的项记录在对应的倒排文件中.

由此, 用户可以在查询语句中加入更多的约束条件, 如规定特定字词的 出现次数 和限定多个字词之间的 相对出现顺序.
但即使是扩展布尔模型也无法解决布尔查询 过于严格, 不具备模糊搜索和联想能力 的问题. 要解决这一问题, 就需要为和查询语句匹配的文章引入 相似性 或 排名 的概念. 也就是说, 对于每一篇被认定为匹配查询语句的文章, 我们都需要用某种方式计算出 它和查询语句的匹配程度.

向量表示 (Vector Representation) 就很好地将 文本表示为向量, 并通过计算向量之间的相似度 解决了这个问题.
向量表示
向量表示的基本思想是: 将文档和查询语句都统一表示为 在相同线性空间中 的 向量, 而文档和查询语句之间的相似程度通过 文档向量和查询语句向量之间的距离 标定.

将文本材料表示为向量的方式是, 为每个出现在文本中的词项都赋予一个 权重. 为了实现这一目的, 我们需要首先引入一系列概念.
词频 (Term Frequency)
词频的定义是: 给定文档 $d$, 词项 $t$ 在 文档 $d$ 中的词频 定义为它在该文档中 出现的次数.
词频不能被直接用于计算文档和查询语句之间的匹配程度, 因为不难看出: 在同一篇文章中出现 $10$ 次的字词显然比只出现了一次的要更重要, 但重要程度 并不和词项的出现次数线性相关.

文档频率 (Document Frequency)
文档频率的定义是: 给定字词, 它在 整个文档库范围内, 出现在多少篇文档中.
我们不妨从一个例子中体会考虑文档频率的意义. 如果查询语句中的某个项在文档库中的 文档频率 极低, 换言之它 非常罕见, 则可近似认为, 在文档库中, 包含这个词项的文档应该非常可能与查询语句相关.
也就是说: 对于信息检索系统而言, 罕见的词项相比常见词项而言, 更有 区分度 (Discriminative) 和 信息性 (Informative).

同时, 如果查询语句中的某个项在文档库中的 文档频率 很高, 换言之它是常见词, 则可近似认为, 在文档库中包含这个词项的文档也是和查询语句相关的. 也就是说:
对 高频字词, 我们希望给它分配 数值较高的, 正的权重, 而对 罕见字词, 我们希望给它分配的是 数值较低的权重.
而文档频率并不能完美地做到这一点. 从下面的例子可以看出, 即便是 集合频率 (Collection Frequency) 也可以得到比文档频率更好的权重.

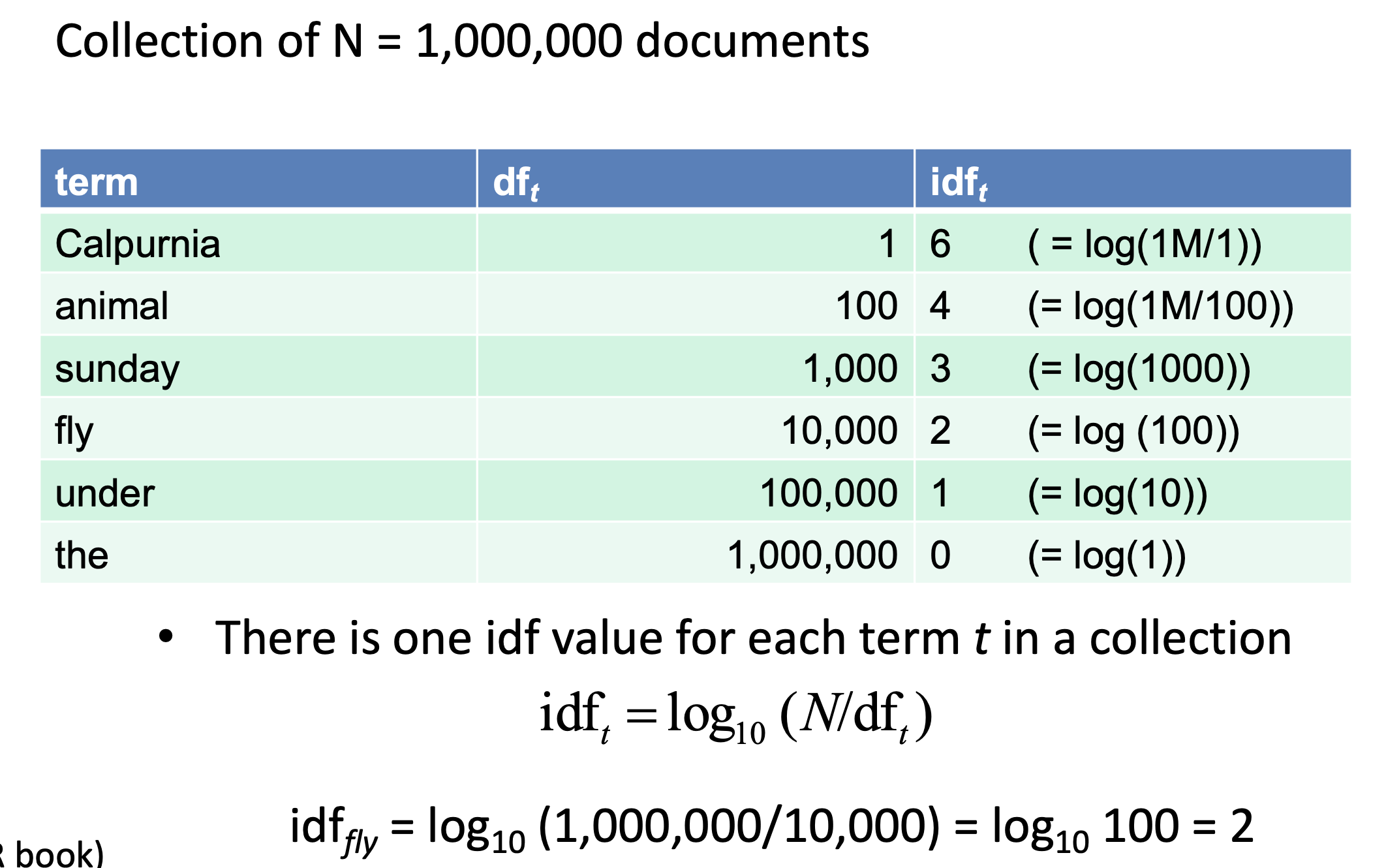
逆文档频率
为了解决这一问题, 我们又引入了 逆文档频率 (Inverse Document Frequency). 它被如下定义:

不难看出, 逆文档频率得到的结果明显好于文档频率:
TF-IDF 频率
TF-IDF 频率结合了文档频率和词频. 其定义如下:

它可以同时建模 字词的罕见程度 和 字词的出现频率, 因此被公认为最合适的权重计算方式之一.
对向量距离的计算
现在我们已经知道, 向量表示中每个字词的权重可以通过 TF-IDF 计算. 下面我们讨论如何定义和计算 向量之间的距离.
一般地, 对向量之间距离的定义有两种方式: 欧几里得距离 和 余弦距离, 我们一般使用 余弦距离.

需要注意, 为了摒除 文本长度 的影响, 在计算两个文本的向量表示之间的余弦距离时, 需要首先 将这两个向量归一化为单位向量:

而对归一化后得到的两个单位向量执行 向量点积 得到的就是所需要的余弦距离. 可见, 余弦距离具有定义和计算简便, 方便快捷的特点.

打分计算和排名
在了解了不同的文本语料表示方法和权重计算方法后, 我们最终得以确定, 在具有模糊查询功能的信息检索系统中, 我们需要使用 文本的向量表示 并应用 TF-IDF 作为权重计算的方式. 下面介绍如何计算给定文本在全体查询结果中的 相对排名:
我们将文本的排名定义为 所有在该文本中找到的, 同样在查询语句中出现过的字词的权重和:
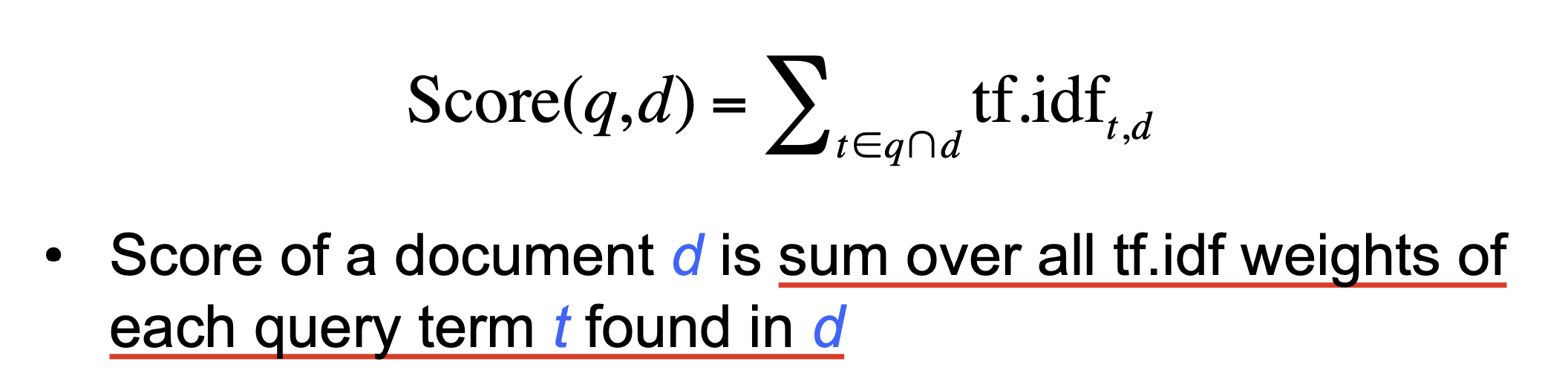
自然, 在这种定义下, 检索这一步所需要进行的工作就是 基于给定词项和文档, 计算该词项关于该文档的 TF-IDF 权重.
而计算结果一般可以表示为一列 按照打分高低排序的文档列表, 我们只需从中选出前数个结果返回给用户就完成了文档的全部检索工作.

总结
最后, 我们将基于向量表示, 使用 TF-IDF 权重的信息检索系统的工作流程总结如下:
