Ch7 函数和方法
Motivation:
- 了解汇编语言实现函数调用和函数嵌套调用的基本原理
- 堆栈的实现原理和一些与堆栈相关的
ARM汇编指令 - 使用堆栈对函数嵌套调用行为进行优化, 使用堆栈在函数和方法之间执行数据传递
1. 使用汇编语言实现函数调用和嵌套调用
要实现汇编语言中的函数调用和嵌套调用, 首先需要对函数调用的流程有足够的了解. 高级程序语言中的函数调用过程相对简化, 便于我们观察和理解函数调用的流程.
1.1 高级程序设计语言中的函数调用和嵌套调用
我们以 Python 为例:

通过观察我们可知, 对函数进行调用就是传递参数, 存储函数执行完毕后将要跳转回的位置, 跳转至函数执行相应的数据处理, 最后从函数体跳转回原代码并利用函数的返回值或函数处理数据的成果的过程.
而相应的, 在函数内, 函数要使用传递进来的参数, 在函数体内执行基于这些参数的相关数据处理, 并存储数据处理的成果, 最后跳转回原代码.
1.2 汇编语言中的函数定义
高级程序设计语言下的函数定义包含了函数名, 参数列表和函数体. 函数名是在调用函数时, 将它与其他函数区隔开的依据; 参数列表表明在对该函数进行调用时需要传递给函数哪些参数, 函数体包含了函数的数据处理逻辑, 是函数的核心.
相应地, 汇编语言中的函数定义也包含了这三个部分, 只是略有细微不同:
- 在汇编语言中, 我们通过定义位于函数体头部的跳转标识符来对该函数进行声明.
- 在汇编语言中, 我们无法直接声明函数的参数列表, 它被集成在了函数体内部: 该函数所需要的数据就是该函数的参数列表.
- 汇编语言下所定义的函数必须具备返回值的功能: 即使是一个最简单的函数, 也必须能够在函数体执行完毕后跳转回原代码处.
- 汇编语言下所定义的函数必须能够控制其内部的数据流动并妥善定义并处理在函数内部所使用的寄存器, 确保函数对主程序和其他函数所使用的寄存器不造成任何影响, 防止造成数据损坏和数据污染.
下面, 简要介绍一下汇编语言下所定义的函数跳转回主程序处的实现方法和原理:
一个函数在主程序内可能被多次从不同的位置调用, 因此该函数每一次返回主程序时不能返回到相同的地址, 其跳转目标地址必须按照实际情况而定. 因此, 我们需要在函数跳转时 (更确切地说, 是跳转前) 将程序计数器的当前值, 也就是该函数对应的返回位置 (Returning Point) 存储下来. 在 ARM 架构中, 寄存器 R14 被指定为存储这样的返回位置的特化寄存器: Link Register-LR 链接寄存器.
1
2
3
4
5
6
7
8
ADR LR, next_address ;LR: return address
B function
next_address STR R0, data ;then use the result proessed by the method (function)
;the method declared:
function ... ;do some calculations
... ;data is calculated inside the method
MOV PC, LR ;branch back to where the function came from
1.3 汇编语言中的函数调用
在上面的例子中, 我们了解了汇编语言中函数调用的特点和性质. 不过实际上, 在实际编程中我们执行函数跳转时所使用的是 BL 指令:
上述例子中涉及的跳转方法使用了 ADR 指令 将一个内存位置存储到链接寄存器中, 再调用分支指令 B 执行跳转. 该方法存在两种缺陷. 首先, ADR 实际上是一个伪指令, 这导致了从主程序体跳转到函数头的过程就需要执行两条指令, 执行时间上有优化空间; 其次, 在采用该方法时, 从函数体跳转到的主程序中的那条语句必须被标示 (labeled).
为解决这一问题而提出的解决方法即为: 改用更先进的 BL (Branch and Link) 指令:
在执行该指令时, 它通过增加程序计数器中的值可确定函数跳转回主程序体时的目标地址, 将该目标地址存入链接寄存器中, 随后跳转到被调用的函数头地址处.
可以看出, BL 指令封装了一个标准的函数跳转流程, 可以起到 “以一抵三” 的效果.
1
2
BL function ; it is one instruction
STR R0, data ; then use the result processed by the method, and no need to label this!
至此, 单次调用函数的问题得到了完整的解决. 但是, 如果我们需要考虑函数的嵌套调用, 则会立刻发现一个新的问题: 存储目标地址的链接寄存器容量不够用了, 它只能存储一条地址.
1.3 汇编语言中的函数嵌套调用
我们下面考虑进行函数嵌套调用时如何对目标地址进行妥善保存. 在对函数进行嵌套调用时, 被调用的函数, 调用的位置和调用的次数都是未知的, 并且我们需要注意, 被调用的函数不能对原函数和主程序所生成/使用的, 存储在寄存器内的数据进行我们所不希望的修改.
这些行为都涉及对数据的存储和保护. 因此, 我们需要一个 “缓存区域”, 用于暂时存储这些需要被保护的关键数据, 而在它们无需再被保护时, 再从缓存区域中将它们销毁.
我们可以在内存空间内预留出一段, 用于缓存区域的数据存储. 下面是一个在内存空间中预留出一个寄存器大小的缓存区域的例子:
1
2
3
4
5
6
7
8
STR R4, temp ;store R4 to variable: temp
...
;then the method body can use R4 safely
...
LDR R4, temp ;recover the original value of R4
MOV PC, LR
temp DEFW 0
在实现了缓存区域的定义和使用后, 我们现在可以正式地考虑函数嵌套调用的问题:
- 一个函数有可能对自身进行嵌套调用, 因此我们可能需要更大的缓存区域
- 在内存中预留的, 固定大小的缓存空间可能根本不会被使用, 或者只有部分被使用而其余部分始终空置, 由此造成了存储空间的浪费.
因此, 我们需要用一种新的方法在内存空间中定义一种动态可变的缓存区域.
2. 堆栈
堆栈的出现解决了上述的问题.
2.1 堆栈模型
我们可以将堆栈想象为一个无限容量的单列弹夹中所有子弹所组成的集合. 在这样的数据结构中, 我们能且只能从顶端将新的子弹 “弹入” (“Push”) 弹夹或从弹夹中 “弹出” (“Pop”).
2.2 堆栈实现
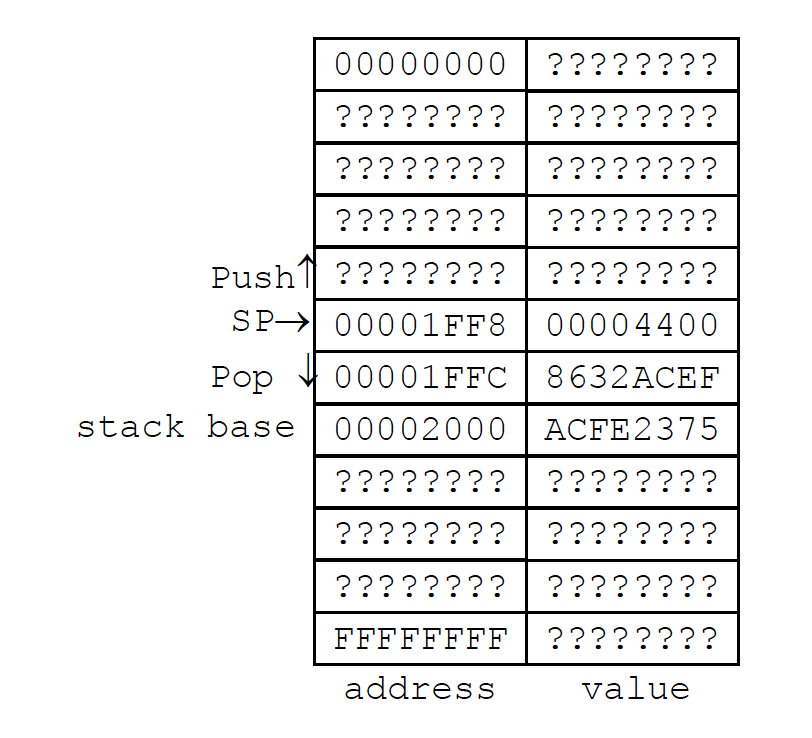
在绝大多数的计算机架构中, 通常以一个很大的内存地址为栈头, 并随着栈长的增加, 栈头所在位置依次向前递减.
ARM 架构定义了一个特化寄存器 R13 作为 栈指针寄存器 (Stack Pointer Register), 简称为 SP, 它始终指向栈头.
2.3 堆栈相关的 ARM 汇编指令
在 ARM 架构中, 我们使用和绝大多数的计算机架构相同的栈定义方法: 栈头从一个较大的内存地址开始, 并随着新元素不断入栈, 栈指针向低内存地址递减.
可以看出, 栈指针位置的变换是和入栈/出栈操作相等价的: 我们无法在高于栈指针的内存地址处修改数据 (入栈), 但是可以对栈指针指向的内存地址处存储的数据进行修改, 也就是入栈.
对栈指针位置的修改是通过增减栈指针寄存器内的值实现的:
1
2
PUSH: STR R0, [SP, #-4]! ;pre-indexed
POP: LDR R0, [SP], #4 ;post-indexed
我们顺便补充一下 前变址 (Pre-Indexed) 和 后变址 (Post-Indexed) 的基本概念:
- 前变址: 指执行指令时, 先进行变址运算, 再传递数据的实现方式.
- 后变址: 指执行指令时, 先传递地址, 再进行变址运算的方式, 用变址运算的结果更新了相关寄存器, 实现了所谓的 “回写”.
当我们需要将多个寄存器入栈或出栈时, 我们可以使用 PUSH 和 POP 指令的队列形式:
1
2
PUSH {R0, R1, R3-R6} ;we can push several regs using one instruction
POP {R0, R1, R3-R6} ;we can pop several regs using one instruction
需要注意的是:
- 中括号内的寄存器是按照 降序顺序 先后入栈的, 也就是说,
R6最先入栈,R1最后. - 相应地, 数字最小的寄存器
R1由于最后入栈, 它被存在最低的内存地址处. - 中括号内的寄存器是按照 升序顺序 先后出栈的, 这和他们的入栈顺序恰好相反.
- 使用这样的指令先后入栈/出栈的寄存器数据最终都会依序回到它们原来所处的地方而不会发生交换.
为了更好地理解第四点, 我们来观察一个例子:
1
2
3
4
5
6
7
8
9
10
11
PUSH R0 ;push R0 first
PUSH R1 ;then push R1, now the SP is headed at the data of R1 instead of R0 in the stack
POP R0 ;pop data to R0. clearly now R1's data is stored into R0
POP R1 ;pop data to R1. clearly now R0's data is stored into R1
;conclusion: unexpected data exchange happened!
PUSH {R0, R1} ;push R0, R1 to the stack following decending numeric order
POP {R0, R1} ;pop R0, R1 from the stack following ascending numeric order
;conclusion: no data exchange happens, R0 is R0, R1 is R1.
实际上, PUSH 和 POP 都是伪指令: 编译器实际上会将它们转译为 Store/Load Multiple 指令. ARM 架构定义了 Store/Load Multiple 指令以在单条指令中将多个寄存器中的内容向/从内存中进行转移. 这样的指令具有更强的效率, 但不支持偏移位寻址模式.
在 STM/LDM 指令中, 我们可以使用任何寄存器作为寻址寄存器:
1
2
3
4
5
PUSH {R0, R1, R3-R6} ; == STMFD SP!, {R0, R1, R3-R6}
;"STMFD" stands for "STore Multiple Full Decrease" 即: “以递减, 满堆栈方式存储多个寄存器”
POP {R0, R1, R3-R6} ; == LDMFD SP!, {R0, R1, R3-R6}
;"LDMFD" stands for "LoaD Multiple Full Decrease" 即: “以递减, 满堆栈方式读取读个寄存器”
其余的相关命令:
| 寻址方式 | 说明 | POP | PUSH |
|---|---|---|---|
| FA | 递增满 | LDMFA | STMFA |
| FD | 递减满 | LDMFD | STMFD |
| EA | 递增空 | LDMEA | STMEA |
| ED | 递减空 | LDMED | STMED |
其指令结构如下:

3. 优化函数的嵌套调用
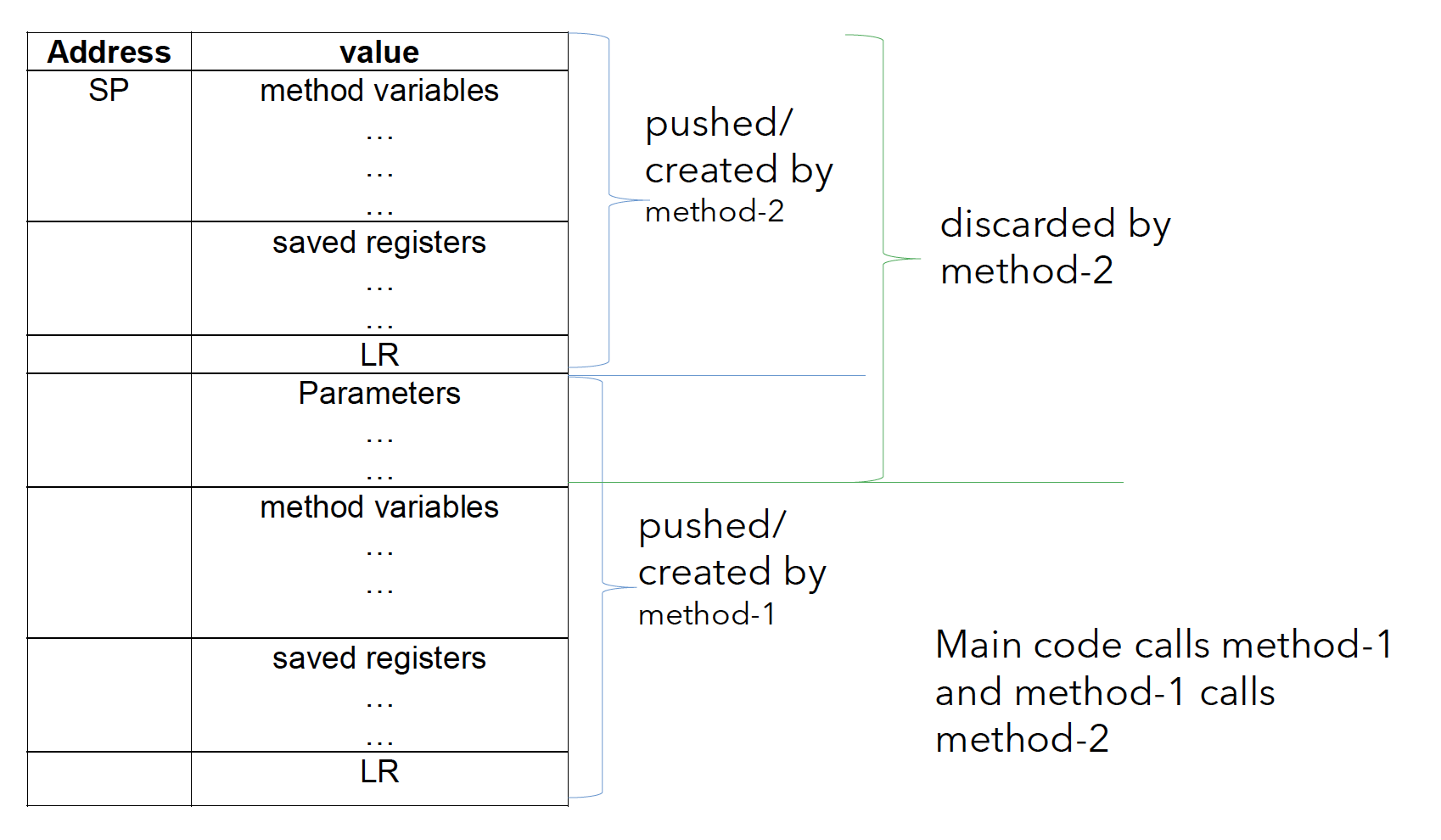
在第二章内我们可以看出, 堆栈是一个大小动态变化的临时存储空间, 可以用于存储包括但不限于链接寄存器数据, 参数, 函数执行结果等具有临时性的内容, 因为在这些数据被使用后, 它们在栈内占用的空间需要被回收. 基于栈这样的特点, 它可被用于函数调用或嵌套调用过程中的数据保护和数据传递.
栈是一种有序的数据结构, 不能被随机访问. 因此, 在使用栈存储函数调用过程中所涉及的各种数据: 函数参数, 跳转返回位置, 函数执行结果, 被保护的寄存器 时, 我们需要明确这些不同类型数据存储的先后顺序.
1
2
3
4
5
6
7
8
9
10
11
12
Method Call:
1. Process Method Arguments
2. Remember where to restart
3. branch to the method
8. use the result
Inside The Method:
4. Use the method body parameters
5. Perform body of the method to process the result
6. Put the result to somewhere accessable by the main program
7. branch back to the restart point
3.1 嵌套调用中涉及的寄存器数据传递
如果我们仅仅使用寄存器进行数据传递的话, 我们需要为每一个参数或者数据指定一个寄存器. 显而易见, 该方法在函数所需要的参数过多或涉及到较深层级的嵌套调用时会立刻变得不切实际. 我们需要使用栈进行数据传递, 在跳转到目标函数头之前, 将该函数所需要的数据和参数先后入栈供其取用. 下面是一个极其简单的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
;senpai = get_senpai(name, age, occupation, height, weight)
LDR R0, senpai_name
PUSH {R0}
LDR R0, senpai_age
PUSH {R0}
LDR R0, senpai_occupation
PUSH {R0}
LDR R0, senpai_height
PUSH {R0}
LDR R0, senpai_weight
PUSH {R0}
BL get_senpai
STR R0, senpai ;we assume the method return R0
senpai_name DEFB "Tadokoro Koji"
senpai_age DEFB #24
senpai_occupation DEFB "student"
senpai_height DEFB "170 cm"
senpai_weight DEFB "74 kg"
......
栈中存储的数据排列如下:
| address | value |
|---|---|
| SP | senpai_weight |
| SP+4 | senpai_height |
| SP+8 | senpai_occupation |
| SP+12 | senpai_age |
| SP+16 | senpai_name |
我们可以基于已知的栈指针位置和数据排列顺序, 在方法中对我们需要的, 栈中的数据进行访问:
1
2
3
4
5
6
7
8
;def get_senpai(senpai_name, senpai_age, senpai_occupation):
get_senpai ;parameters: use [SP, #16], [SP, #12] and [SP, #8]
...
...
ADD SP, SP, #20 ;discard all 5 parameters
MOV PC, LR ;return
3.2 嵌套调用中的链接寄存器数据保护
由于 BL 指令会更改链接寄存器 LR 的值, 我们在执行函数的嵌套调用, 在某个函数内跳转到下一个目标函数前必须妥善保存对当前函数而言的返回目标地址, 以免在下一个目标函数执行完毕, 跳转回该函数之后, 由于链接寄存器的值在执行嵌套调用时已被重定向至该函数本身, 从而导致因返回目标地址迷向而形成的自跳转死循环.
1
2
3
4
5
6
7
8
9
10
;def get_senpai(senpai_name, senpai_age, senpai_occupation):
get_senpai ;parameters: use [SP, #16], [SP, #12] and [SP, #8]
STR LR, [SP, #-4]!
; SP DECREASES by 4, params are now:
;[SP, #20](name), [SP, #16](age) and [SP, #12](occupation)
...
BL get_senpai_bodysensor ;branch to another method, this OVERWRITES LR!
...
LDR PC, [SP], #24 ;Return, puts the LR into PC, then discard these 5 params and the LR data in the stack
3.3 嵌套调用中的寄存器数据保护
寄存器的数据保护有两种实现方式. 其核心逻辑完全相同, 区别仅仅在执行数据保护的对象上.
-
由调用函数者执行的寄存器数据保护 (
Caller Saved): 调用函数的程序在执行跳转前保护所有此前该程序涉及的寄存器数据, 以防这些寄存器被 被调用的函数 覆写而造成数据污染或数据丢失. -
由被调用函数执行的寄存器数据保护 (
Callee Saved): 被调用的函数在执行寄存器写操作前, 先保护本程序内将要用到的所有寄存器数据, 以防在向这些寄存器写入数据时覆写原函数可能用到或保存的数据, 造成数据污染或数据丢失.
这两种实现方式各有其劣势: 前者需要存储所有主程序涉及的寄存器, 无论它们会不会被所调用的函数所使用; 而后者同样也要存储所有自身所涉及的寄存器, 无论主程序有没有使用它. 但是, 总的来说, 由于主程序规模往往远大于被嵌套调用的函数, 因此采用 “由被调用函数执行的寄存器数据保护” 更加经济合理.
一个完善的函数嵌套调用的寄存器数据保护框架如下所示: