
Ch7 输入/输出设备
在本章中,我们将对输入/输出设备和处理器之间的通讯方式进行部分的解释和介绍, 包括 I/O 内存映射,串/并口通讯和 USB 协议,以及简介使用中断和直接内存访问 (DMA)方法,通过程序控制的数据传输方法。
I/O设备和处理器间的数据传输方法I/O内存映射 (MMIO)- 串/并口通讯方式和
USB协议 - 硬件中断方法和直接内存访问 (
DMA)
1. I/O 设备和处理器间的数据传输方法
I/O 设备和处理器间的信息交互方法主要有两种:
1.1 数字信号传输
数字信号传输是现今最为广泛使用的数据传输方式. 在数字信号传输系统中, 数据经过二进制编码被转换为只具备两种状态的信号 (如高电压/低电压, 开/闭等) 并被发送/接收. 由于信号不存在中间态, 使用这样的方式传输的信号抗干扰能力极强, 适合远距离传输. 在使用数字信号传输方法的基础上, 我们既可以在单个时间跨度内仅仅传递一个二进制位, 也可以同时传递多个二进制位. 这也就是所谓的 串行通讯 (Serial) 和 并行通讯 (Parallel).
1.2 模拟信号传输
模拟信号就是使用连续变化的物理量承载信息的信号. 其信号波形的幅度 / 频率 / 相位随时间连续变化. 在电学意义上, 模拟信号主要指其幅度和相位均连续的电信号. 模拟信号的抗干扰能力不强, 容易受到传输途中的噪声的干扰, 并且安全性较差. 但是, 若需要被传递的信息本身就是模拟信号的话, 若要使用数字信号传输方法, 就需要对其进行采样, 量化和编码, 并且在量化过程中会不可避免地损失信息.
1.3 带宽和延迟
延迟 (Latency) 指信息从被发送到被对方接收之间所经过的时间.
带宽 (bandwidth) 指给定的信息传递通道在同一时间内可以传输的信息的量, 单位为 Bit/s.
不同情形下的单向信息传递延迟情况如下:
| 距离 | 耗时 |
|---|---|
| 在集成电路内部 | $0.2$ ns |
在 PCB 上跨板传输 |
$1$ ns |
| 地月传输 | $1.3$ s |
| 地日传输 | $8$ mins |
2. I/O 内存映射 (MMIO)
2.1 I/O 设备界面
处理器和 I/O 设备之间的数据传输由 I/O 设备界面 处理: 它负责将处理器提供的数字信号转换为 I/O 设备能理解的模拟信号. 从抽象的角度而言, 设备界面提供了一种或多种标准化的通讯协议, 将处理器与 I/O 设备连接起来.
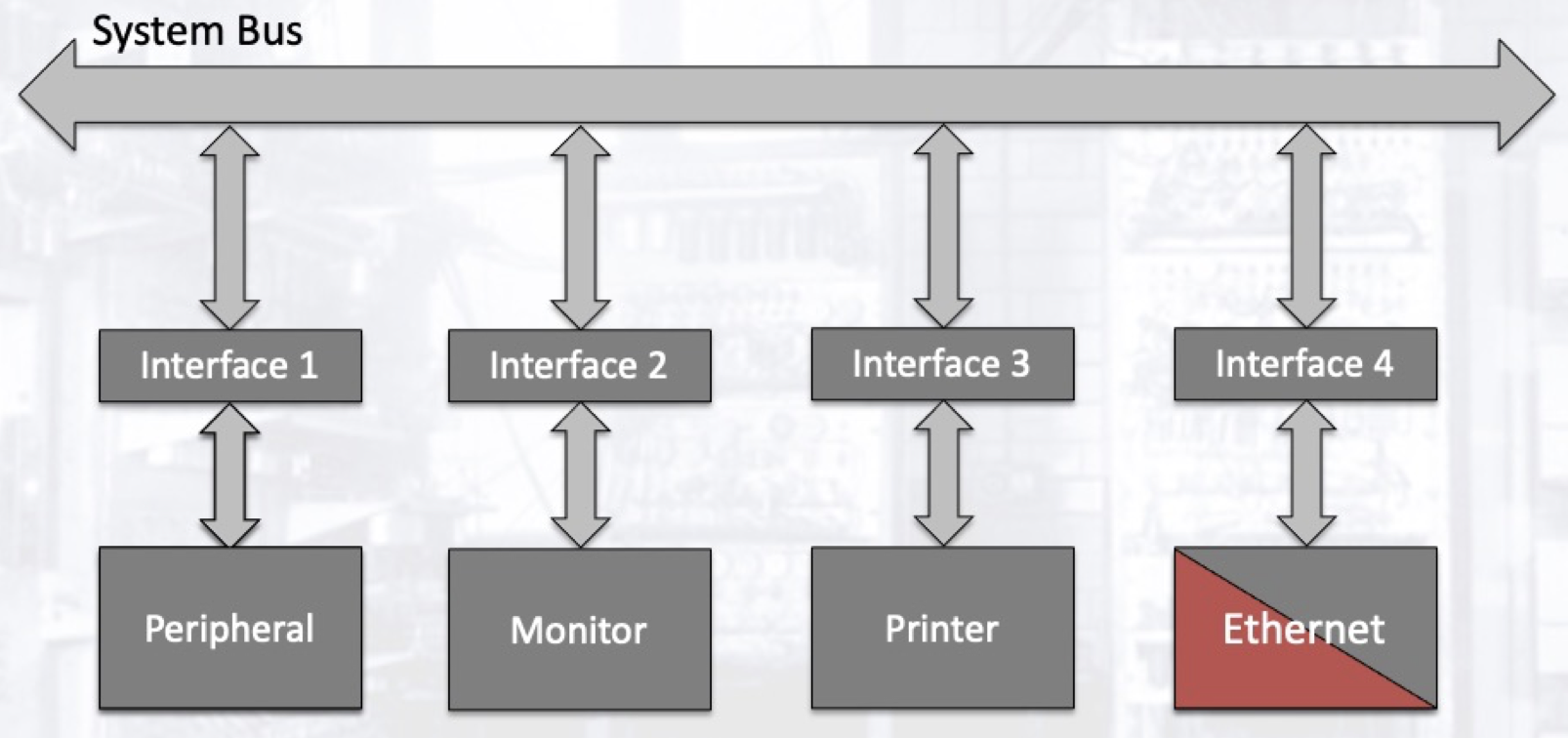
2.2 MMIO
在讨论 I/O 内存映射前, 我们先解释一下何为内存映射:
内存映射将 ROM, RAM 等存储设备或具备提供/接收信息能力的硬件中的物理存储地址映射为逻辑内存地址, 将复杂的数据写入/读取操作简化为对某个逻辑内存地址的操作, 抹平了它们在物理意义上的性质差异.
I/O 设备也可以被抽象为逻辑内存地址: 每一个 I/O 设备依其需要占用一定大小的逻辑内存地址, 但被它们占用的逻辑内存地址位于物理内存所占用的逻辑内存地址外, 不造成冲突. 通过对这些物理意义上并不存在的逻辑内存地址和内存空间的访问或写入, 处理器可以和 I/O 设备进行交互, 但复杂的信号转换和协议解读过程实际上由 I/O 设备界面的复杂电路负责. 相应地, I/O 设备也有自己的地址链路, 数据链路以及控制信号, 而它们的这些输入/输出信号线路接入总线的方式和内存相似.
I/O 设备的使能与否由处理器控制, 经过 I/O 设备界面对信号进行翻译. 和常识所不同的是, 当且仅当 I/O 设备界面中的解码单元检测到内存地址总线上传输了特定的内存地址时, 和这个内存地址对应的 I/O 设备才会被启用 (即: 该设备被连接到数据总线上, 允许在总线上与处理器产生数据交互). 这样的逻辑电路可以使用 三态缓冲器 实现.
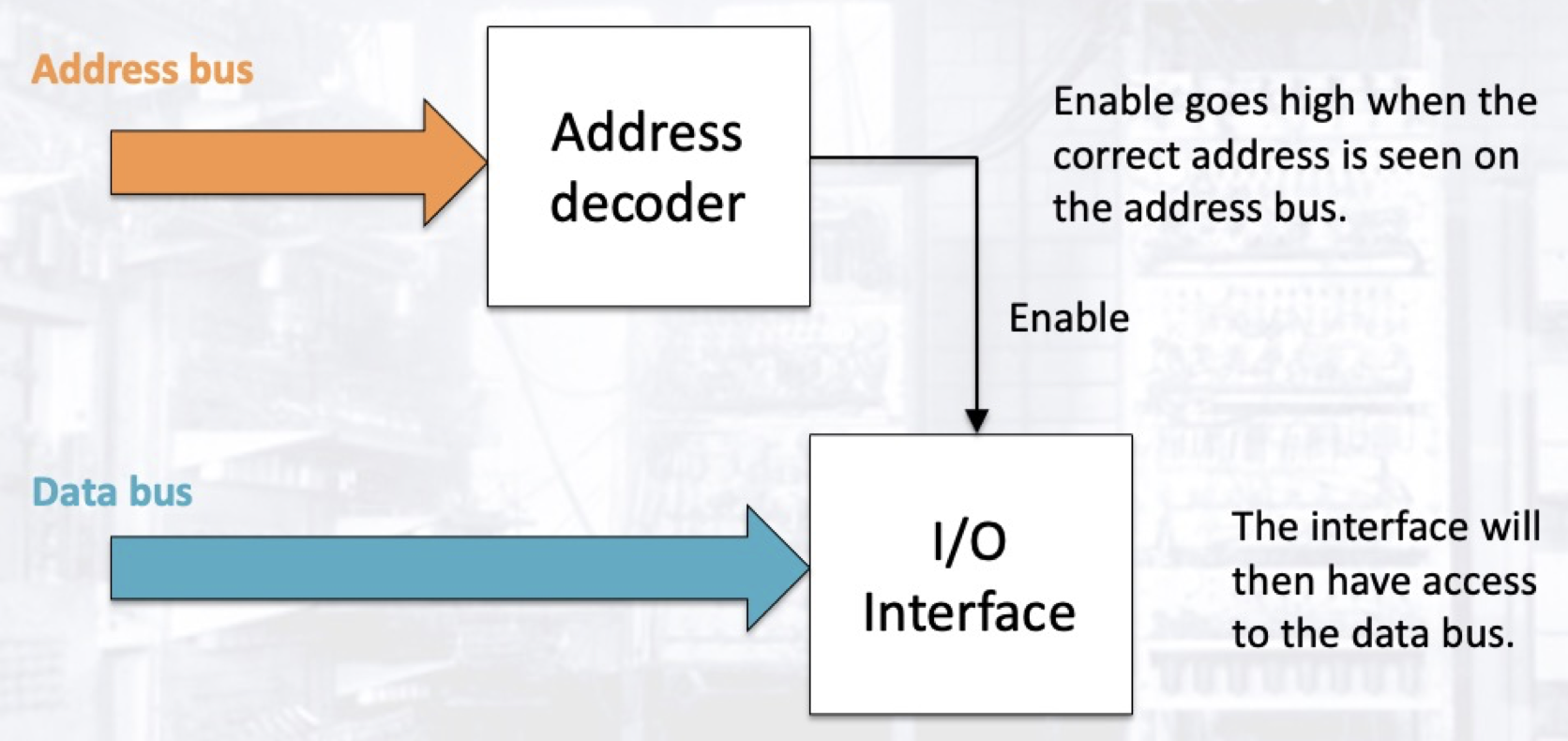
下面我们以一个简单的串行显示输出界面为例:

在这个例子中, 显示数据将被处理器写入一个容量为 $n$ 位的寄存器, 该寄存器的使能信号 En 由一个 I/O 设备界面的内存地址解码器输出; 而寄存器中的内容将被另一个解码器转换为串行型号输出至 I/O 设备.
3. 串/并口通讯方式和 USB 协议
3.1 抖动 (Storbing)
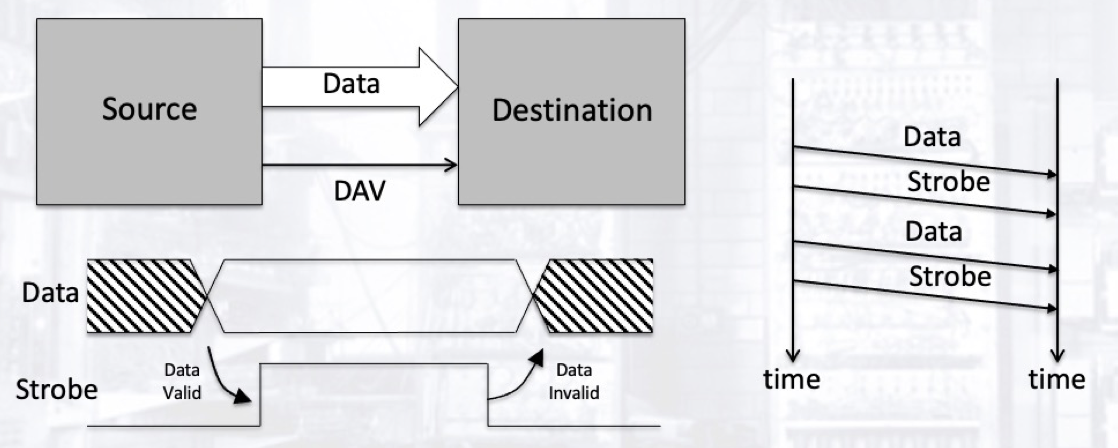
Storbing 是一种简单的非对称数据传输方法. 这一方法只需要一个控制信号, 该控制信号由发起数据传输的一方生成并控制. 控制信号用于指定和唤起接收方. 在正式开始数据传输之前, 发送方先在数据总线上不断地传输数据 Data, 随后在控制信号链路上发送抖动信号 DAV 广播指定的一个或数个数据接收方, 随后数据接收方收到抖动信号 DAV 后接收数据总线上的信号 (也就是我们要传输的数据), 数据传输发起方在假定接收方已经成功接收数据后停止控制信号链路和数据总线上的信号传递.
这种非对称的数据传输方式带来了一个显而易见的问题: 发送方无从得知接收方的实际状况, 因而无法保证数据传输能够稳定成功进行. 为了解决这个缺陷, 我们需要额外设计一条新的控制信号, 使得发送方和接收方能够实现双向通讯.
此外, 如果我们使用 Storbing 方法向多个接收设备传递数据, 则该过程的耗时取决于所有接收设备的数据接收时间中最长的那一个.
3.2 握手 (Handshaking)
Handshaking 是一种常用的对称数据传输方法. 在该方法中, 数据发送方和数据接收方之间可以进行双向通讯. 握手过程大致为:
- 数据发送方首先将目标数据在数据总线上广播, 随后拉高
Request信号告知数据接收方, 数据传输已经准备完毕. - 数据接收方在接收到
Request信号后开始接收数据总线上的数据, 并在接收完毕后拉高Acknoledge信号告知数据发送方, 数据已经接收完毕. - 数据发送方在接收到
Acknoledge信号后解除对数据总线的占用, 数据传输流程结束.
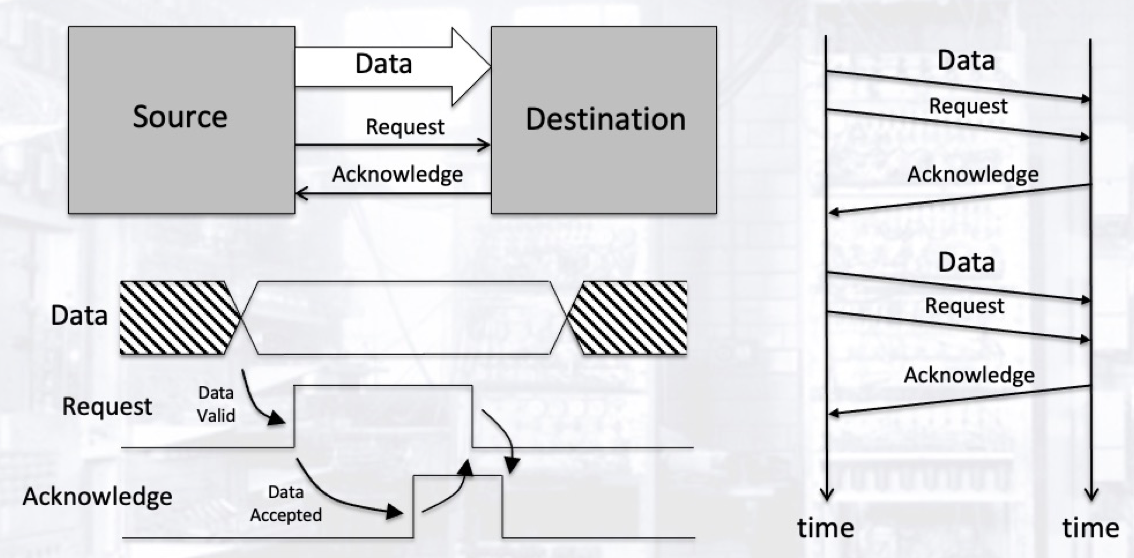
Handshaking 需要偶数多条并行链路: Request, Acknoledge, 数据链路/数据总线, 以及一条用以比对的地线.
3.3 并行通讯
并行通讯允许我们同时传输多个数据位. 并行通讯的实现成本较高, 因其需要更多的数据链路以同时传输多个位. 其主要优势在于:
- 并行通讯的设备界面极其简单:
并行输出可视为一个能被处理器写入的一组连续的内存地址, 并行输入可被视为一个缓冲区, 将以上两者结合起来就构成了最简单的并行通讯的设备界面, 其控制完全可以由软件实现. - 高带宽:
虽然并行通讯需要更多的数据链路, 但在传输距离较短且对数据传输延迟要求较高的使用场景, 如处理器和内存之间的直接通讯而言, 并行通讯是可行性最高的通讯方式.
并行通讯的一个缺陷为: 数据总线上传递的信息容易受到噪声干扰, 因而限制了数据传输速率.
3.4 串行通讯
相比并行通讯方法, 串行通讯只需要少得多的数据链路即可实现远距离的数据传输, 大大节约了成本. 此外, 串行通讯和主流的通讯介质, 如光纤, 之间的相性很好, 也适用于传输一些本身就具有串行特性的信息, 如磁带和光盘所记录的信息.
- 波特率 (
Baud Rate)
波特率定义为在一秒钟内信号变化的次数. 串行通讯协议往往定义了数个可选择的波特率, 常见的一个是 $9600$. 在进行数据传输时, 发送方和接收方必须基于相同的波特率发送/接收数据, 否则数据采样无法正常进行. - 奇偶校验位 (
Parity)
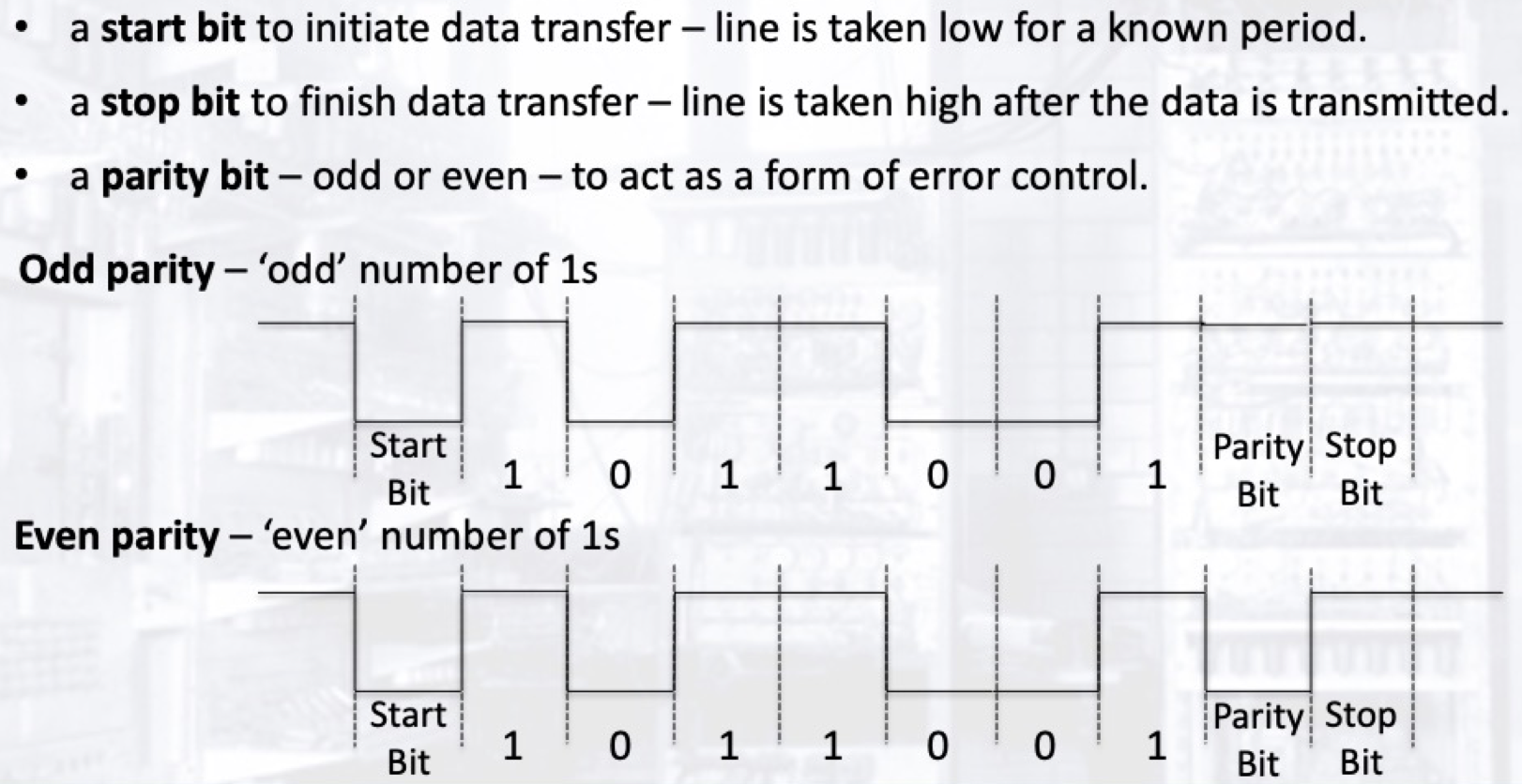
为了防止数据传输过程中出现错误, 使用串行通讯方式传输的每一个数据切片 (或数据包) 都包含了一个额外的奇偶校验位. 和波特率一样, 发送方河接收方同样需要基于相同的奇偶校验位的初始值对数据进行编码和解码. - 起始位和终止位 (
Start & Stop Bits)
起始位和终止位用于指示数据传输的状态.
3.5 通用串行总线协议 (USB)
USB 3.0 以前的协议使用四根线路进行数据传输和供电. USB 通过 power 和 ground 提供 $5$V供电 , 剩下的两条链路 D+ 和 D- 用于数据传输. 特别的是, USB 协议是通过比对两条互反的数据链路之间的电位差而非单条数据链路和地线之间的电位差来判断所传输的二进制位的, 这减小了信号噪声对传输信息的干扰.
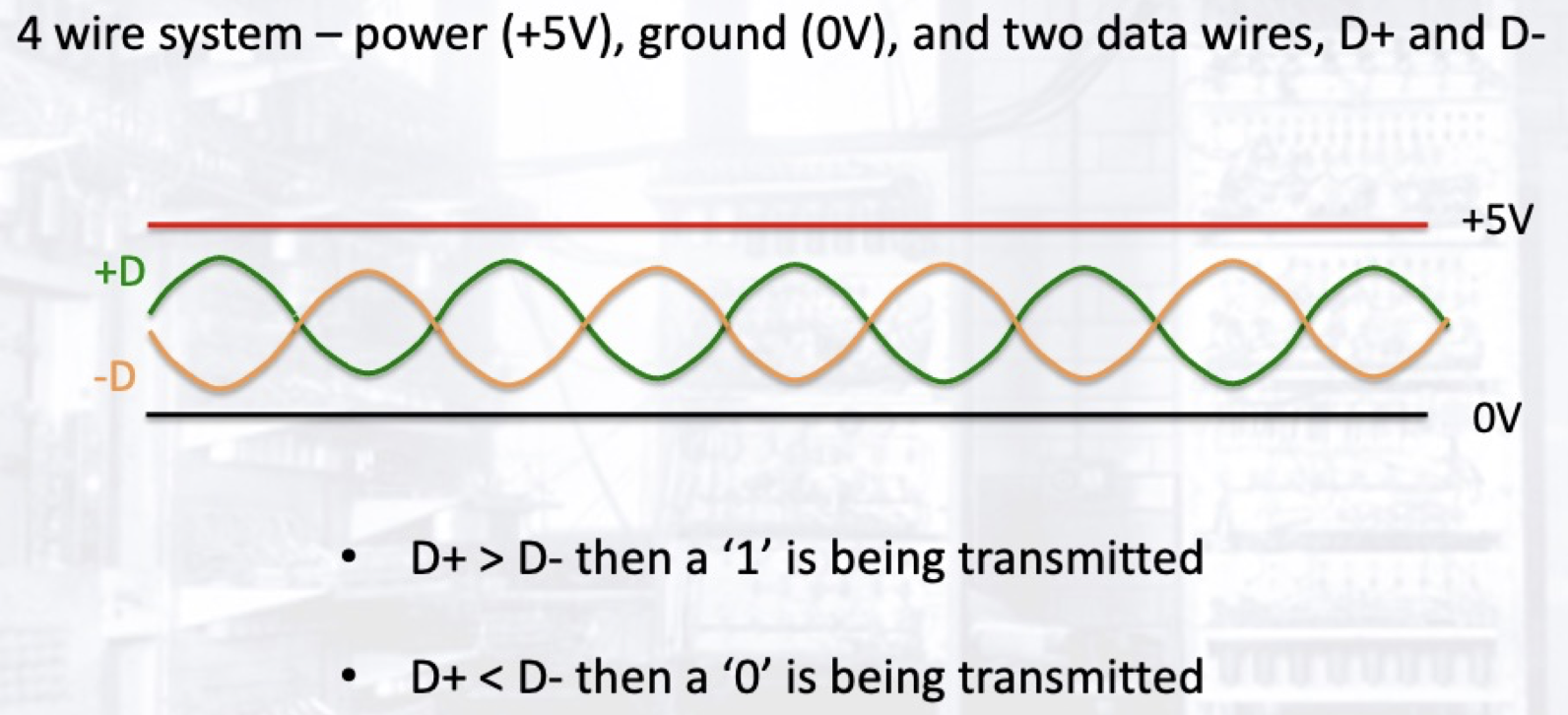
USB 协议使用 不归零编码 (Non-Return-to-Zero Inverted, NRZI) 编码被传输的数据:
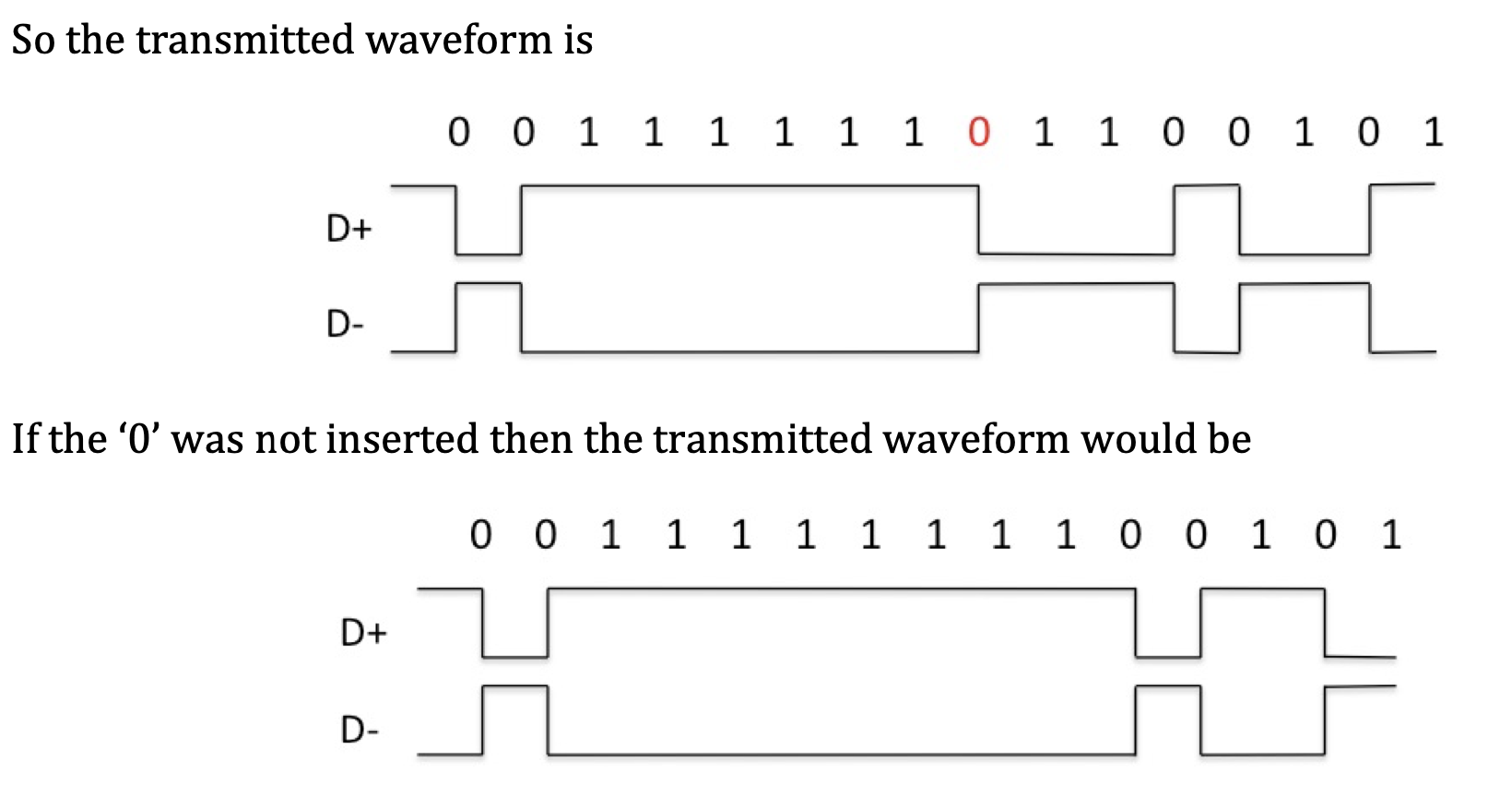
不归零编码规定, 信号电平的一次反转代表 $0$, 电平不变化代表 $1$, 且在表示完一个二进制位后, 信号电平不需要被重置. 不归零编码实现了对带宽的有效利用, 但当连续发送 $1$ 或 $0$ 时, 难以确定每个位的开始或结束. 为了避免这一问题, USB 协议规定, 若连续传输了六个 $1$, 则要在其后插入一个 $0$ 来进行强行位反转:
3.6 USB 数据包
使用 USB 协议进行的一切数据传输都涉及 USB 数据包的交换. USB 数据包含有对数据传输进行控制的信息, 被传输的数据本身与额外的数据校验信息:
| 类别 | 全称 | 功能 |
|---|---|---|
Sync |
- | 数据包必备项, 用于将设备端的时钟频率和主机端同步. |
PID |
Packet ID |
为一个 $8$ 位数字, 用于指示被传输的数据包类别. 前 $4$ 位为数据位, 后 $4$ 位为错误校验位. |
CRC |
Cyclic Redundancy Check |
用于错误校验. |
EOP |
End Of Packet data |
用于指示数据传输完毕. |
4. 硬件中断和直接内存访问 (DMA)
4.1 硬件中断
I/O 设备轮询模式的主要问题是, 由于处理器的速度比这些外围设备快得多, 因此将会浪费大量本可以用于处理数据和执行指令的时间在对 I/O 设备的轮询上. 若使用硬件中断方法, 处理器将不会定期对 I/O设备轮询, 检查它们是否已经准备就绪或传入了新的数据, 而是被动地接收由这些外围设备传来的中断信号: 当外围设备产生了新的数据需要被传入处理器, 或完成了处理器派发的任务后, 中断信号将会由控制链路传入处理器. 这样, 处理器就不需要浪费时间等待缓慢的外围设备处理或传入数据 (如等待从键盘传来的用户输入), 而在等待的时间里什么也不做; 所节省下来的时间将会全部用于其他的数据处理, 提升了处理器使用率和程序执行速度, 也让多任务处理成为可能.
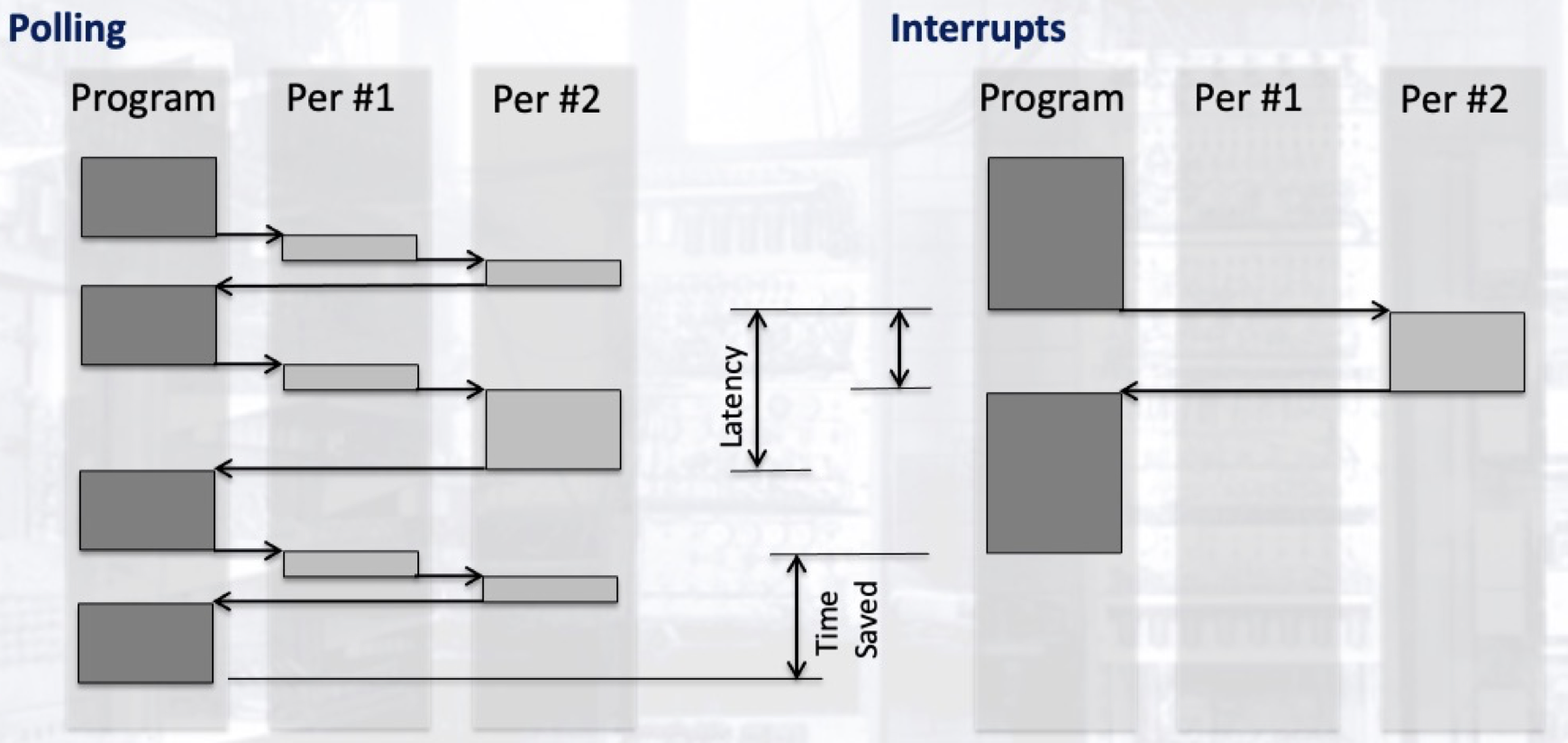
实际上, 中断信号源于 I/O 设备的设备界面而非其本身. 因此, 当中断信号被发出而处理器没能及时响应和处理的话, 从 I/O 设备传入的信息会丢失.
软件中断和硬件中断不可被混为一谈: 前者由当前正在运行的程序所控制, 是由执行中断指令 (SWI) 产生, 可以被预测和控制的, 不可屏蔽, 不会直接中断处理器. 而后者由外设引发, 由外设界面的中断控制器产生, 可被屏蔽, 并且不可预测.
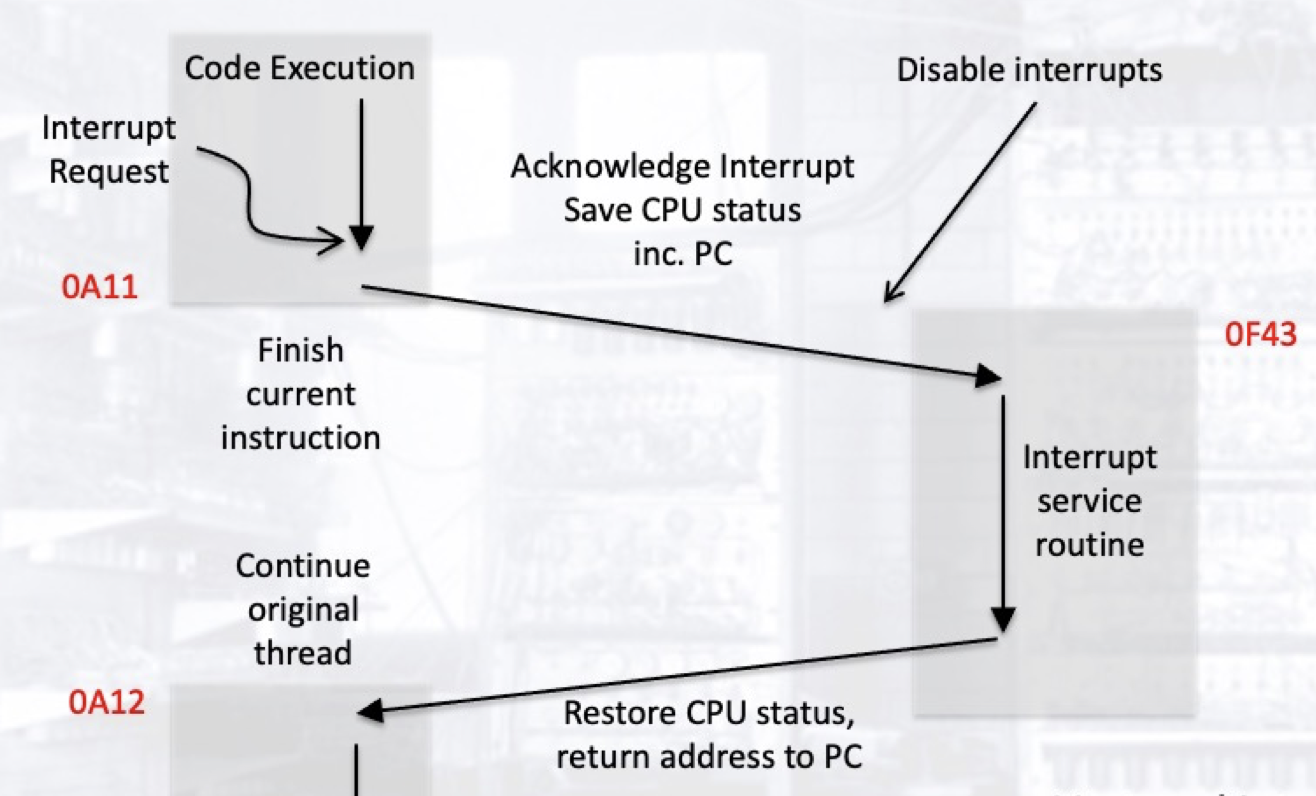
当中断发生后, 处理器将会 暂时停止在中断发生前所正在执行的任务, 保存当前的执行状态, 转而去执行某一个不同的任务, 在执行完毕后恢复状态, 继续执行原来的任务. 基于发生中断后跳转的分支不同, 中断又可分为 向量中断 (Vectored Interrupt) 和 非向量中断 (Non-Vectored Interrupt): 对于前者, 引起中断的设备还会提供因设备类型特定的, 存储有将要跳转到的指令的内存地址 (入口地址) , 而对后者而言, 无论引起中断的设备是什么, 其入口地址均是相同的, 在进行跳转后再去基于中断标志来判断中断类型 (即: 是什么设备引起了中断).
4.2 中断的实现
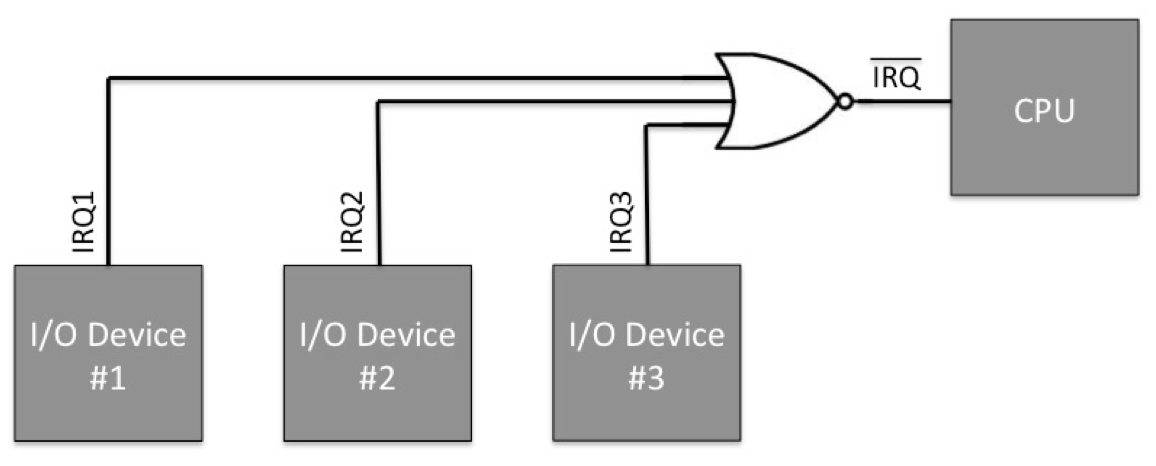
对于多个位于同一芯片內的中断源 (I/O 设备)而言, 将其中断线路全部进行异或运算, 即可得到一个单独的中断信号.
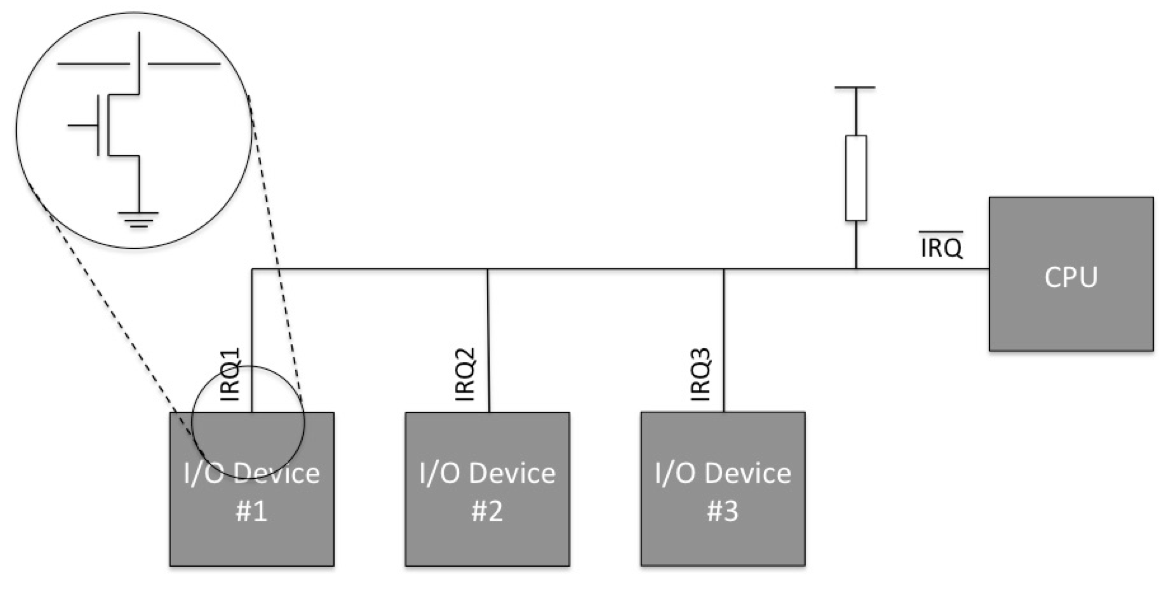
考虑分布在板上的数个不同的 I/O 设备. 在这一情况下, 我们需要使用一个电阻将中断链路拉高, 而在每一个 I/O 设备发生中断时, 一个电容器将会和中断链路连接, 从而拉低这一链路, 传递中断信号.
在接收到外围设备传来的中断信号后, 处理器还需要耗费一定时间来判断中断是由链路上的哪一个外设发送的. 但相比传统的轮询方式, 它仍然大大缩减了耗时. 向量中断使用额外的硬件电路直接判断和回传发起中断的硬件身份, 进一步节约了时间. 下面, 我们考虑更为复杂的情形: 中断优先级.
4.3 中断优先级和菊花链
基于引起中断的外围设备的不同, 在处理中断时, 同样要考虑优先级. 对中断优先级的判断逻辑可以嵌入在控制器中, 可以程序判断, 也可以通过菊花链的形式人为分级, 也可以将以上的三种方法组合使用.
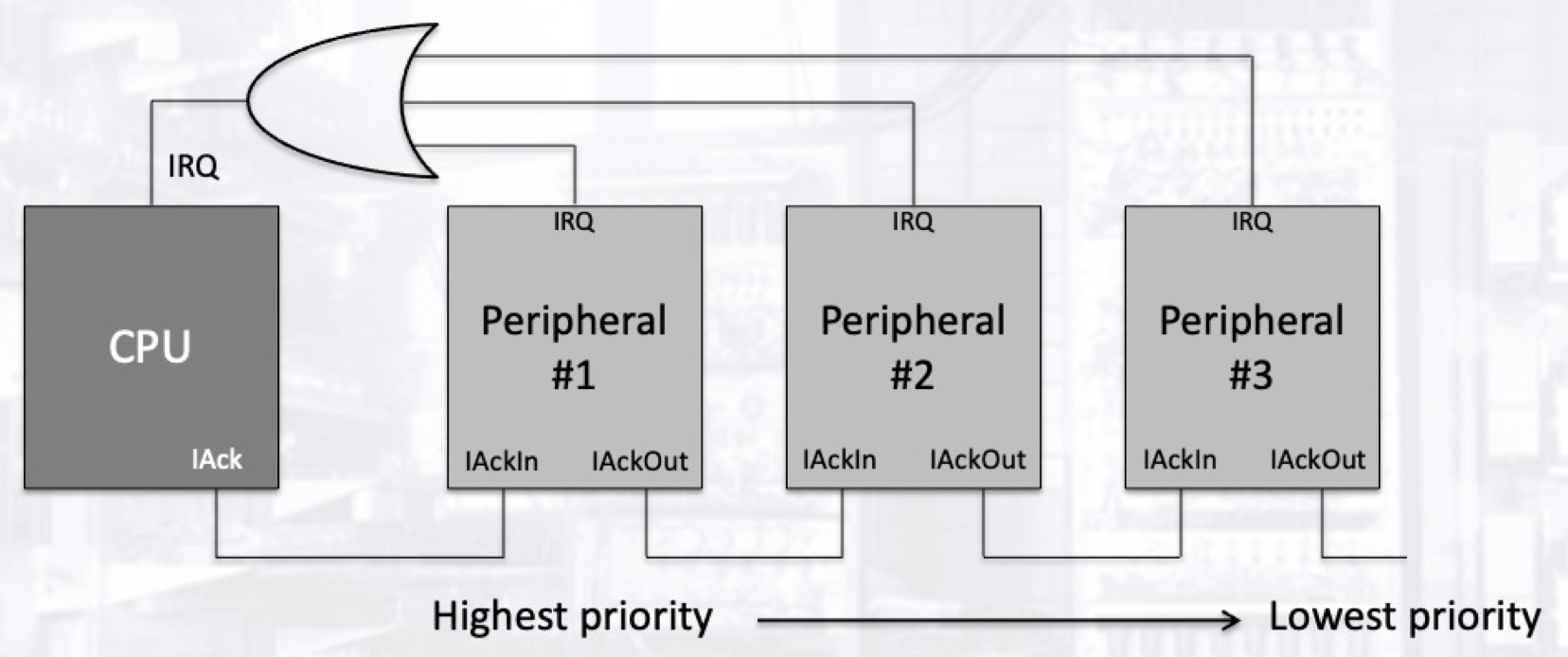
其中一种通过轮询来检测那个设备引起了中断的一种方式是将外设以菊花链的形式串联. 在菊花链中, 不同的外设往往会依其本身的优先级而串联. 链中所有的外设共享同样的中断请求线路 (Interrupt Request Line). 当链中的任何外设将该线路拉至低电平时, 处理器会接收这一中断请求, 并回传一个中断确认信号(Interrupt Acknowledge Signal), 该信号依序在链中传递.
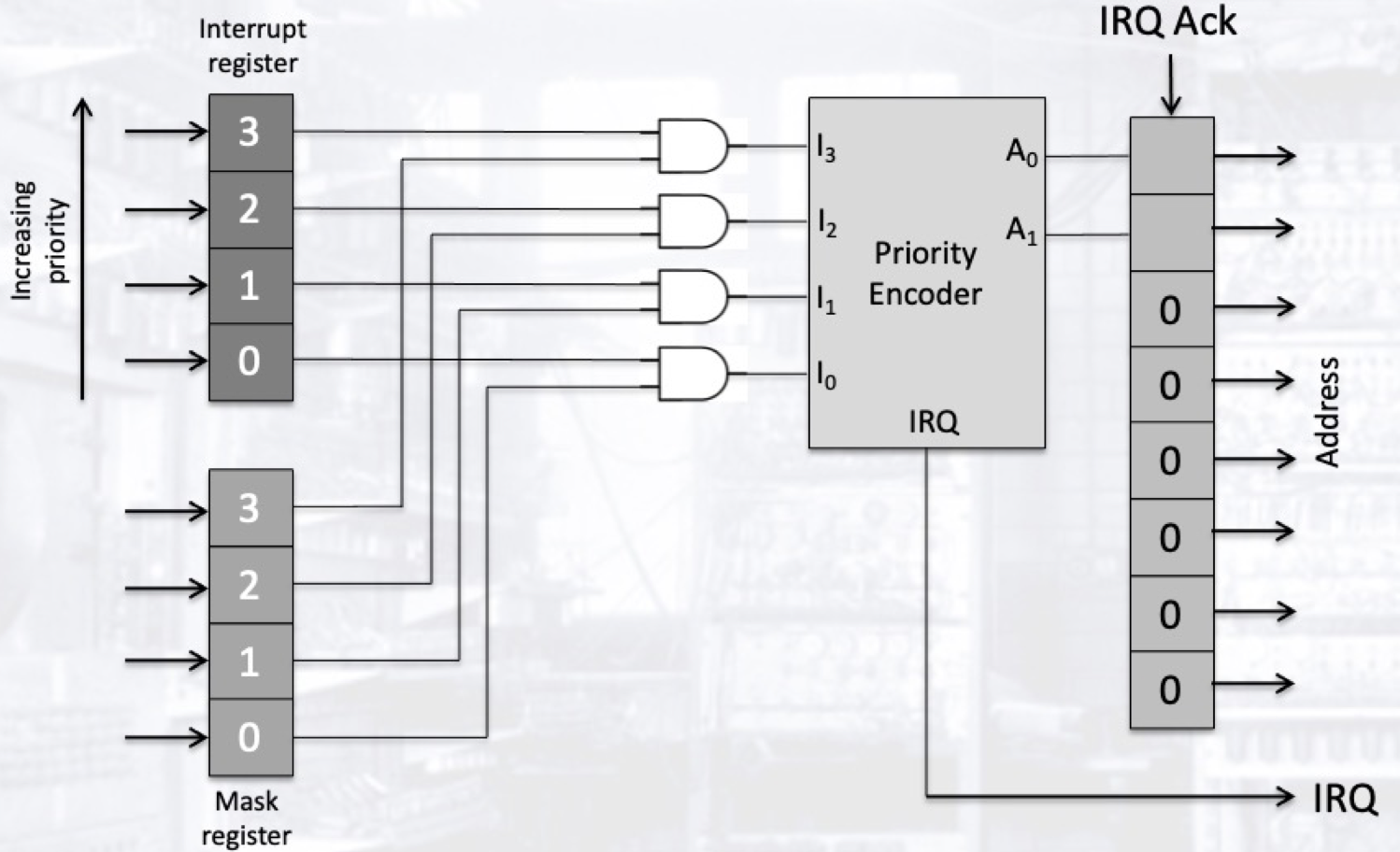
下面来看一个实现中断优先级的例子:
在本例中, 中断寄存器和四条来自不同外设的中断链路链接, 当其中任何一个外设产生中断时, 寄存器中的对应位会变为 $1$. 中断寄存器內的每一位数据和一个用来依情况禁用设备中断的掩码寄存器中的对应位通过一个与门执行与运算, 结果传递至优先级编码器. 外设中断优先级的判定规则被硬编码入优先级编码器中. 若编码器检测到两个或以上的中断, 它将优先输出高优先级的外设中断请求至处理器. 此外, 它还将输出一个用于构成内存地址一部分的 $2$ 位的值, 它作为内存地址的高位, 和其余 $6$ 个为 $0$ 的位组成一个完整的内存地址, 在所形成的内存地址处存储有对应的中断程序.
4.4 直接内存访问
中断仍需耗费大量的处理器时间用于将数据在外设和存储之间转移. 直接内存访问 (DMA) 允许外设绕过处理器对内存的特定地址进行直接访问, 从而将处理器从数据转移工作中解放出来. 直接内存访问常用于高带宽数据传输, 如计算机和光驱的通讯, 以及计算机和高分辨率, 高刷新率显示器之间的数据通讯.
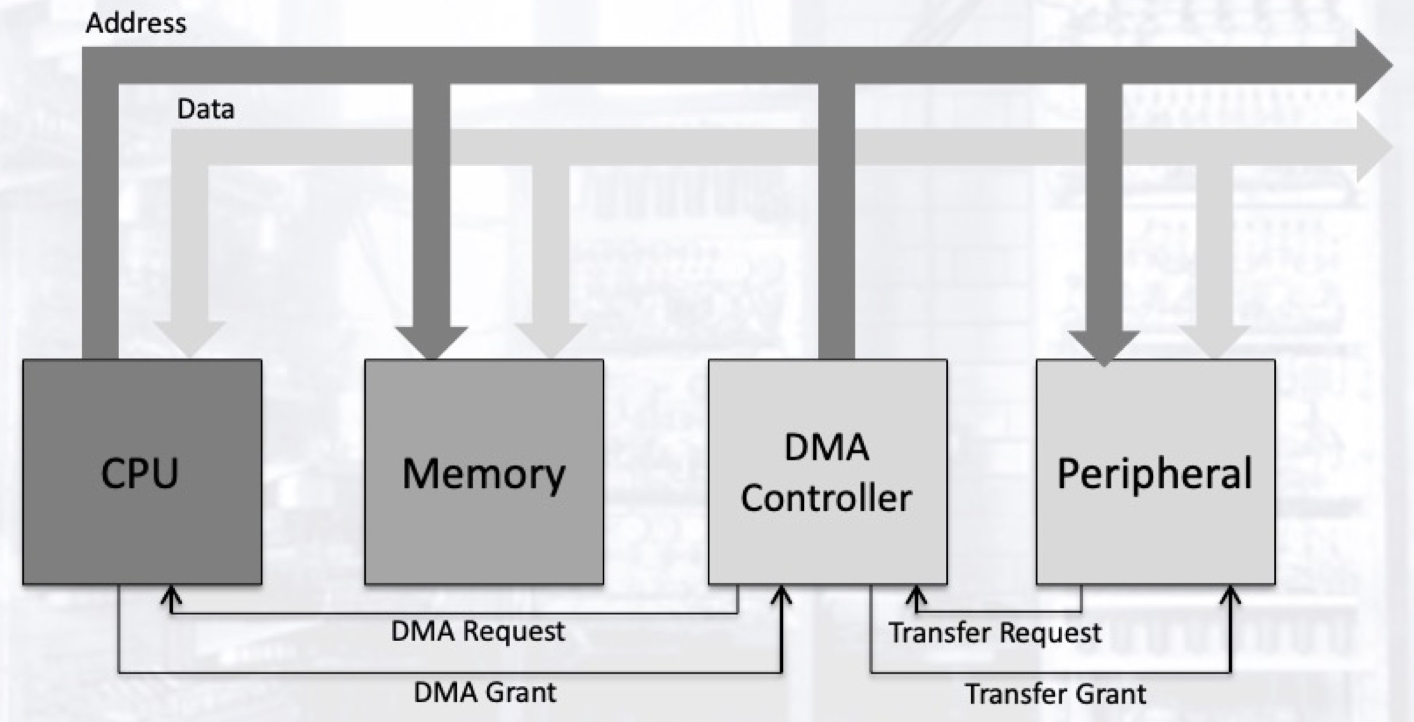
DMA 的工作原理是控制源于处理器的数据总线和地址总线, 并利用这些总线将数据从 I/O 设备直接传输至内存. 一般情况下, 数据总线和地址总线都由处理器所控制. 当外设需要执行 I/O 操作时, 会对 DMA 控制器发出传输请求, 而 DMA 控制器会进一步向处理器请求对总线的控制权.
DMA 控制器所执行的任务仅仅是对内存的写入或对内存的读取. 在 I/O 设备进行内存读写的同时, 处理器可以同时执行更加复杂的任务, 这进一步增加了计算机系统的并行性.
然而, 当处理器和 DMA 控制器同时需要总线的控制权时, 就会出现冲突, 而这一冲突将交由总线本身来解决. 不过, 即使这样的冲突发生, 直接内存访问方法仍然具有更高的效率.
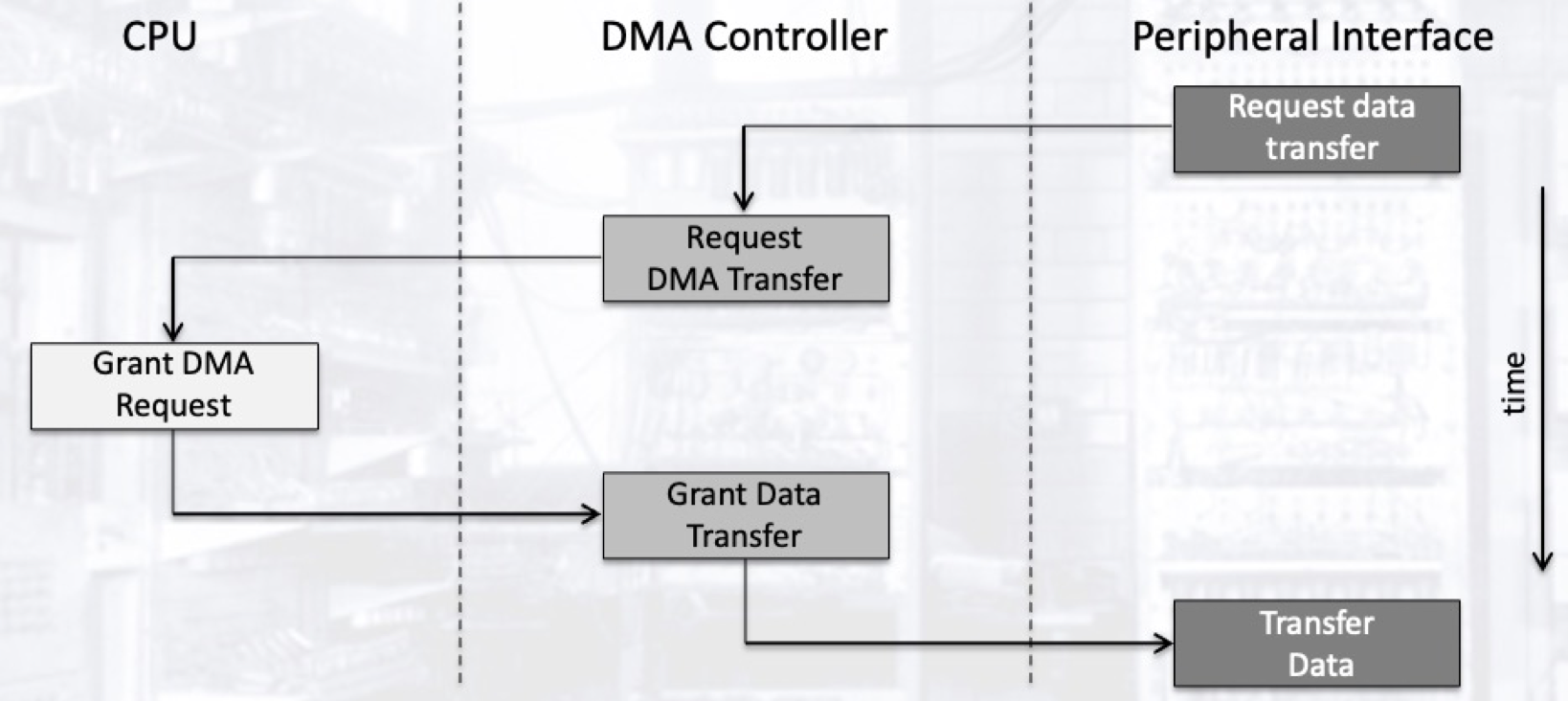
直接内存访问机制提供了两种传输数据块的方法:
Burst Mode
在大量数据传输的全过程中,DMA控制器都掌握对系统总线的控制权. 在此期间, 处理器因暂时失去对系统总线的控制权而停机.Cyclic Mode
在该模式下,DMA控制器的行为不干扰处理器对内存的正常访问.Transparent Mode
在该模式下, 当且仅当处理器不使用系统总线时,DMA控制器才进行数据传输. 该模式虽然对处理器性能影响最小, 但在执行大量数据传输方面效率很差.